目次
この記事について
OSS紹介シリーズの第15回目へようこそ。この記事では、注目すべきオープンソースソフトウェア(OSS)を取り上げ、その機能や活用法について詳しく解説しています。
前回は表形式データの処理に特化したTableBankをご紹介しましたが、今回はその内部で重要な役割を果たしているツール「OpenNMT-py」にスポットライトを当てます。TableBankの強力な言語処理能力を支えるこのフレームワークは、単独でも非常に優れた機能を持ち、様々な自然言語処理プロジェクトで活用されています。
「OpenNMT-py」は、PyTorchをベースにしたオープンソースの神経機械翻訳(NMT)および大規模言語モデルのフレームワークです。翻訳や言語モデリング、要約など、多岐にわたる自然言語処理タスクに対応できる柔軟性を持ち、研究者や開発者にとって新たなアイデアを試すための理想的な環境を提供しています。特に、最近のAI技術の進化により言語処理の自動化需要が高まる中、「OpenNMT-py」はその要望に応える力を秘めています。
この記事を通じて、「OpenNMT-py」の基本的な特徴や活用方法について詳しく解説し、読者のみなさんが自身のプロジェクトにどのように役立てられるかを示したいと思います。翻訳技術やNLPへの理解が深まることで、より効果的なツール活用が広がることを願っています。
リンク:https://github.com/OpenNMT/OpenNMT-py
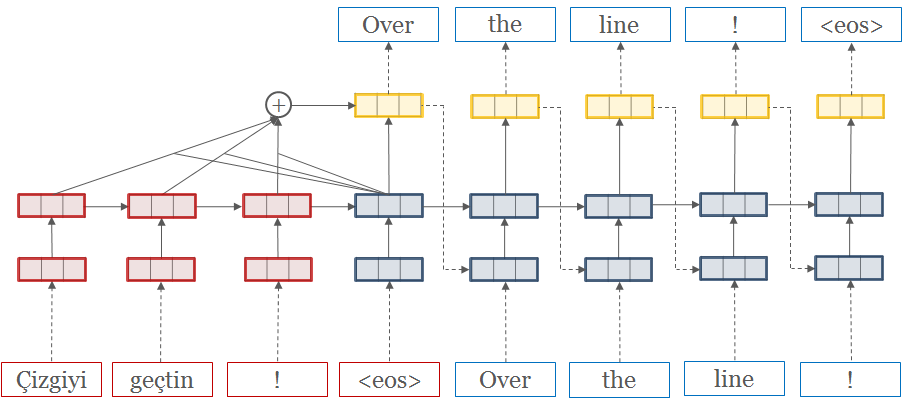

本コンテンツは、弊社AI開発ツール「IXV」を用いたOSSツール紹介です。情報の正確性には努めておりますが、内容に誤りが含まれる可能性がございますのでご了承ください。
1. OpenNMT-pyでできること
OpenNMT-pyは、PyTorchをベースにしたオープンソースのニューラル機械翻訳(NMT)および大規模言語モデルのフレームワークです。以下のような機能を提供しています。
1.1 ニューラル機械翻訳
OpenNMT-pyは、さまざまな言語間の翻訳を行うためのモデルを構築、トレーニング、推論を行うことができます。研究者や開発者が新しいアイデアを試すために設計されており、多くの企業でも本番環境での利用が実証されています。
1.2 言語モデル
大規模な言語モデルの構築と応用に利用でき、文章生成や要約などのタスクにも対応しています。
1.3 高度な機能
最新の更新により、8ビットおよび4ビットの量子化、LoRAアダプタ、Tensor並列処理などの高度な機能がサポートされています。これにより、リソースを効率的に使用しながら大規模なモデルを訓練・推論することが可能です。
2. セットアップ手順
OpenNMT-pyを使用するためには、以下の手順でセットアップを行います。
2.1 環境要件
- Python 3.8以上
- PyTorch 2.0以上(2.2未満)
2.2 インストール方法
Dockerを使用する場合
Dockerを使用することで、簡単に環境を構築できます。以下のコマンドでDockerイメージを取得します。
docker pull ghcr.io/opennmt/opennmt-py:3.4.3-ubuntu22.04-cuda12.1コンテナを起動するためのコマンドは以下の通りです。
docker run --rm -it --runtime=nvidia ghcr.io/opennmt/opennmt-py:test-ubuntu22.04-cuda12.1ローカルにインストールする場合
ローカル環境に直接インストールする場合は、以下の手順を実行します。
- リポジトリをクローンします。
git clone https://github.com/OpenNMT/OpenNMT-py.git
cd OpenNMT-py
2. pipを使用してインストールします。
pip install -e .
2.3 依存関係の手動インストール
パフォーマンス向上のために、NVIDIAのApexやFlash Attentionなどの追加の依存関係を手動でインストールすることが推奨されています。
3. 簡単な使い方
OpenNMT-pyの使用は、次のような基本的なコマンドから始まります。
3.1 データの準備
まず最初に、モデルをトレーニングするためのデータを準備します。OpenNMT-pyでは、並列コーパス(ソーステキストとターゲットテキスト)が必要です。
例として、英語-ドイツ語の翻訳用サンプルデータセットを使用してみましょう:
# サンプルデータのダウンロードと展開
wget https://s3.amazonaws.com/opennmt-trainingdata/toy-ende.tar.gz
tar xf toy-ende.tar.gz
cd toy-endeダウンロードしたデータセットには以下のファイルが含まれています:
- src-train.txt(翻訳元の英語テキスト)
- tgt-train.txt(翻訳先のドイツ語テキスト)
- src-val.txt(検証用の英語テキスト)
- tgt-val.txt(検証用のドイツ語テキスト)
次に、YAML形式の設定ファイルを作成します。以下はシンプルな例です:
# toy_en_de.yaml
## データの保存先
save_data: toy-ende/run/example
## 語彙データの保存先
src_vocab: toy-ende/run/example.vocab.src
tgt_vocab: toy-ende/run/example.vocab.tgt
# 同名ファイルの上書き防止
overwrite: False
# コーパス設定:
data:
corpus_1:
path_src: toy-ende/src-train.txt
path_tgt: toy-ende/tgt-train.txt
valid:
path_src: toy-ende/src-val.txt
path_tgt: toy-ende/tgt-val.txtこの設定ファイルを使って語彙データを構築します:
onmt_build_vocab -config toy_en_de.yaml -n_sample 100003.2 モデルのトレーニング
次に、モデルをトレーニングするための設定を追加します。先ほどのYAML形式の設定ファイルに以下の内容を追加しましょう:
# 先ほど生成した語彙ファイルのパス
src_vocab: toy-ende/run/example.vocab.src
tgt_vocab: toy-ende/run/example.vocab.tgt
# 単一GPUでトレーニング
world_size: 1
gpu_ranks: [0]
# チェックポイントの保存設定
save_model: toy-ende/run/model
save_checkpoint_steps: 500
train_steps: 1000
valid_steps: 500トレーニングを開始するには、以下のコマンドを実行します:
onmt_train -config toy_en_de.yamlこのコマンドにより、デフォルトの2層LSTMモデル(エンコーダーとデコーダーの両方で500の隠れユニットを持つ)が構築され、トレーニングが開始されます。
3.3 翻訳の実行
トレーニングが完了したら、モデルを使って新しいテキストを翻訳できます:
onmt_translate -model toy-ende/run/model_step_1000.pt -src toy-ende/src-test.txt -output toy-ende/pred_1000.txt -gpu 0 -verboseこのコマンドは、ビームサーチを使用して翻訳を実行し、結果をtoy-ende/pred_1000.txtに出力します。
注意点:サンプルデータセットは小さいため、翻訳結果の品質は限定的です。実際のプロジェクトではより大きなデータセットを使用することをお勧めします。例えば、翻訳や要約のための数百万の並列文を含むデータセットが公開されています。
4. 応用例:事前学習済みLLMの生成
OpenNMT-pyは単純な翻訳モデルだけでなく、大規模言語モデル(LLM)の扱いにも対応しています。
4.1 Hugging Face Hubからのモデル変換
OpenNMT-pyは、Hugging Face Hubなどの外部ソースからモデルをインポートするためのコンバーターを提供しています。例えば、OpenLlamaモデルを変換するには:
python tools/convert_openllama.py --model_dir /path_to_HF_model --tokenizer_model /path_to_tokenizer.model --output /path_to_Openllama-onmt.pt --format pytorch --nshards N4.2 推論用設定ファイルの準備
モデルの推論には、YAML形式の設定ファイルを使用するのがベストプラクティスです:
transforms: [sentencepiece]
#### Subword
src_subword_model: "/path_to/llama7B/tokenizer.model"
tgt_subword_model: "/path_to/llama7B/tokenizer.model"
# モデル情報
model: "/path_to/llama7B/llama7B-onmt.pt"
# 推論設定
seed: 42
max_length: 256
gpu: 0
batch_type: sents
batch_size: 1
precision: fp16
beam_size: 1
n_best: 1
report_time: true4.3 テキスト生成
設定ファイルを使用してテキストを生成するには:
python onmt/bin/translate.py --config /path_to_config/llama7B/llama-inference.yaml --src /path_to_source/input.txt --output /path_to_target/output.txt以上が、OpenNMT-pyの基本的な使い方の流れです。シンプルな翻訳モデルから大規模言語モデルまで、幅広いNLPタスクに柔軟に対応できることが、このフレームワークの強みです。
結論
OpenNMT-pyは、ニューラル機械翻訳や言語モデルの研究・開発において強力なツールです。Dockerを利用することで簡単にセットアップでき、豊富な機能を活用して大規模なモデルを効率的に扱うことが可能です。今後の開発や研究において、ぜひ活用してみてください。