目次
Scaling On-Device GPU Inference for Large Generative Models
この論文は、プライバシーと効率性を考慮しつつ、リソース制約のあるデバイス上で大規模生成モデルのGPU推論を拡張するための最適化フレームワーク「ML Drift」を提案しています。
本論文の特徴は、ML Driftという最適化フレームワークを用いることで、既存のデバイス上の生成AIモデルに比べて最大100倍のパラメータを持つモデルを効率的に実行可能にし、リソース制約のあるデバイス上での複雑なAIワークロードのデプロイを実現する点です。
論文:https://arxiv.org/abs/2505.00232

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
本論文では、生成AIの進展により、大規模な機械学習モデルが画像処理、音声合成、音声認識などの分野を革新していることについて述べています。サーバーベースのデプロイメントが最高のパフォーマンスの中心である一方で、プライバシーや効率性の観点から、デバイス上での推論の必要性は依然として存在します。デバイス上の機械学習アクセラレーターとして最も広く利用されているGPUに注目し、最先端のGPU加速推論エンジンの能力を拡張する最適化フレームワーク「ML Drift」を提案します。
ML Driftは、既存のデバイス上の生成AIモデルよりも10倍から100倍多くのパラメータを含む生成AIワークロードをデバイス上で実行可能にします。さらに、ML DriftはクロスGPU API開発に関連する複雑なエンジニアリング課題に対処し、モバイルとデスクトップ/ノートパソコンプラットフォーム全体での広範な互換性を確保することで、リソースが制約されたデバイス上でより複雑なモデルのデプロイを容易にします。我々のGPU加速ML/AI推論エンジンは、既存のオープンソースGPU推論エンジンに対してオーダーオブマグニチュードの性能向上を達成します。
1. 序論
過去10年間で、画像合成や自然言語処理などの分野に革命をもたらす大規模生成モデルが急速に普及しました。サーバーベースの展開が最高のパフォーマンスを発揮する一方、プライバシー、レイテンシ削減、オフライン機能、サーバーコスト削減のためにオンデバイス実行が重要です。モバイルGPUは、その広範な可用性と計算能力により、これらの複雑なモデルの展開に最適なソリューションです。しかし、現代の生成モデルは、前世代と比較して10〜100倍の規模を持ち、リソースに制約のあるモバイルGPUへの展開には大きな課題があります。
2. 関連研究
エッジデバイスのリソース制約は、機械学習モデルの効果的な展開に重要な課題をもたらします。この分野の研究は、汎用GPUを活用するアプローチ、専用推論フレームワーク、そして最近ではエッジデバイス上での大規模生成モデルの展開の複雑さに関する研究に大別できます。ML Driftは、OpenCL、Metal、OpenGL ES、Vulkan、WebGPUなど、多様なバックエンドでのパフォーマンス最適化を優先し、他のソリューションの範囲を超えています。
2.1 汎用GPU推論
既存のGPUアクセラレーテッドな推論の多くは、TensorRTやROCmなどのベンダー固有のライブラリに依存しています。これらは特定のハードウェアプラットフォームで最高のパフォーマンスを発揮しますが、アーキテクチャの特異性により、多様なGPUエコシステム間での移植性が制限されます。
2.2 不均質なエッジデバイス向け推論エンジン
エッジデバイス向け推論エンジンの最適化は、不均質なハードウェア(CPU、GPU、NPU)を活用することに重点が置かれています。ハードウェアとOSベンダーは、Apple CoreML、Arm Compute Library、Huawei HiAI Engineなどの専用SDKを提供していますが、これらはベンダー依存のため移植性と展開の柔軟性に懸念があります。クロスプラットフォームのフレームワークとしては、ExecuTorch、ONNX Runtime Mobile、MACE、MNN、NCNNなどがあります。
2.3 大規模生成モデル推論
大規模生成モデルの出現により、機械学習推論の要求がさらに高まっています。サーバーサイド展開用の専用ライブラリとしてLMDeploy、SGLang、vLLMなどが提案されています。同時に、llama.cpp、ollama、torchchatなどのライブラリを通じて、大規模生成モデルの効率的なエッジ推論を可能にする取り組みも進行中です。
3. 大規模モデルのためのGPU推論のスケーリング
ML Driftは、手動で最適化されたシェーダーテンプレートからランタイムで動的コード生成を実行する新しいアプローチを導入します。テンサー仮想化という概念を導入し、論理テンサー表現から物理的なGPUオブジェクトを抽象化することで、多様なメモリレイアウトとカーネル構成を可能にし、これを座標変換と組み合わせて柔軟なアクセスを実現しています。
3.1 論理テンサーと物理的GPUオブジェクト
論理テンサーとは、数学的または機械学習の文脈で意味のある軸を持つ多次元配列を指します。物理的GPUオブジェクトは、GPUバッファ、イメージバッファ、テクスチャアレイなど、この論理テンサーを実現する実際のメモリバッファです。各軸にはバッチ、高さ、幅、深さ、チャネルなどの意味が割り当てられ、GPUの4要素SIMDを活用するためにPHWC4メモリレイアウトなどの最適化が行われます。
3.2 テンサー仮想化
単一の均一なレイアウトでは一部のGPUカーネルに最適でない場合があります。ML Driftは「テンサー仮想化」を導入し、テンサーの論理表現と物理的なGPU上の保存を分離します。これにより、テンサーは様々なタイプと数のGPUメモリオブジェクトを使用して実現でき、カーネル作成者は低レベルのメモリ管理を気にせずにアルゴリズムロジックに集中できます。
3.3 座標変換
生成シェーダープログラムが柔軟なメモリレイアウトを持つテンサーを読み書きできるようにするため、ML Driftはシェーダーコード生成段階で、テンサー要素の座標を実際のGPUメモリオブジェクトの座標に変換するヘルパー関数を導入します。これにより、ニューラルネットワークオペレータをGPUバッファやテクスチャからのテンサー要素へのアクセスから抽象化します。
3.4 デバイス特殊化
ML Driftは、プラットフォームに依存しない抽象化をターゲットGPU言語に変換する様々なGPUバックエンド向けのシェーダージェネレータを開発します。ランタイム分析によりGPUプロパティを特定し、各GPUオペレータに適応型カーネル選択、ベンダー固有拡張の活用、構文変換、重み変換などの変換を適用します。
3.5 メモリ管理
大規模生成モデルのメモリフットプリントは、モデルの重みと中間テンサーによって大きく影響されます。ML Driftは、非オーバーラップなライフスパンを持つテンサーにメモリバッファを割り当てたり、大きなメモリブロックを事前に割り当ててテンサーにオフセットを割り当てるといったアプローチでメモリ共有を実現します。例えば、Stable Diffusion 1.4では、GREEDY BY SIZEアプローチにより、ランタイムメモリフットプリントを4.31GBから387MBに削減(93%の節約)することに成功しています。
3.6 オペレータフュージョン
ML Driftは、要素ごとの操作、テンサー並べ替え操作、または残差接続の連続を検出すると、自動的にオペレータフュージョンを適用します。具体的な例として、アテンションブロック内でロータリーエンベディングとクエリ(Q)、キー(K)、値(V)の投影のレイアウト変換を組み合わせるカスタムカーネルを作成し、マルチヘッド、マルチクエリ、グループドクエリのアテンションなど、様々なアテンション機構に対応しています。
3.7 LLM推論のためのステージ認識最適化
ML Driftは、LLM推論のプレフィルとデコードステージを区別します。プレフィルステージは計算集約的であり、専用のGPU量子化カーネルから恩恵を受け、デコードステージはメモリバウンドであり、入力アクティベーション量子化を操作カーネル内に直接統合することでメモリ転送オーバーヘッドを軽減します。
3.8 GPU最適化KVキャッシュレイアウト
ML DriftはLLM推論の行列乗算に畳み込みカーネルを使用します。KVキャッシュは畳み込みの重みとして機能し、QKV変換と互換性のあるレイアウトで保存されます。Kキャッシュは計算のためにOHWIレイアウトを使用し、Vキャッシュは期待されるアテンション出力レイアウトを確保するために次元を逆転させたOHWIレイアウトを使用します。
4. 性能評価
ML Driftの性能評価は、モバイル(Arm MaliおよびQualcomm Adreno)、デスクトップ/ラップトップ(IntelおよびNVIDIA)、Apple SiliconなどのGPU上で、大規模テキスト-イメージモデルと大規模言語モデルを対象に行われました。
4.1 大規模拡散モデル
Stable Diffusion 1.4を使用して、OpenCL、Metal、WebGPUバックエンドのパフォーマンスを評価しました。Samsung S23 UltraのQualcomm Adreno 740 GPU上では、512×512画像の生成(20イテレーション)のエンドツーエンドレイテンシが10.96秒を達成し、以前の報告から8%の改善を示しました。Intel Meteor Lake Ultra 7 165UのWindowsラップトップでは、ML Drift OpenCLがONNX Runtime with DirectMLと比較して2.7倍の高速化を実現しました。Apple SiliconではM1 UltraとMacBook Pro M4 Pro上でのStable Diffusion 1.4の実行時間がそれぞれ3.86秒と5.34秒で、Apple CoreMLよりも優れたパフォーマンスを示しました。
4.2 大規模言語モデル
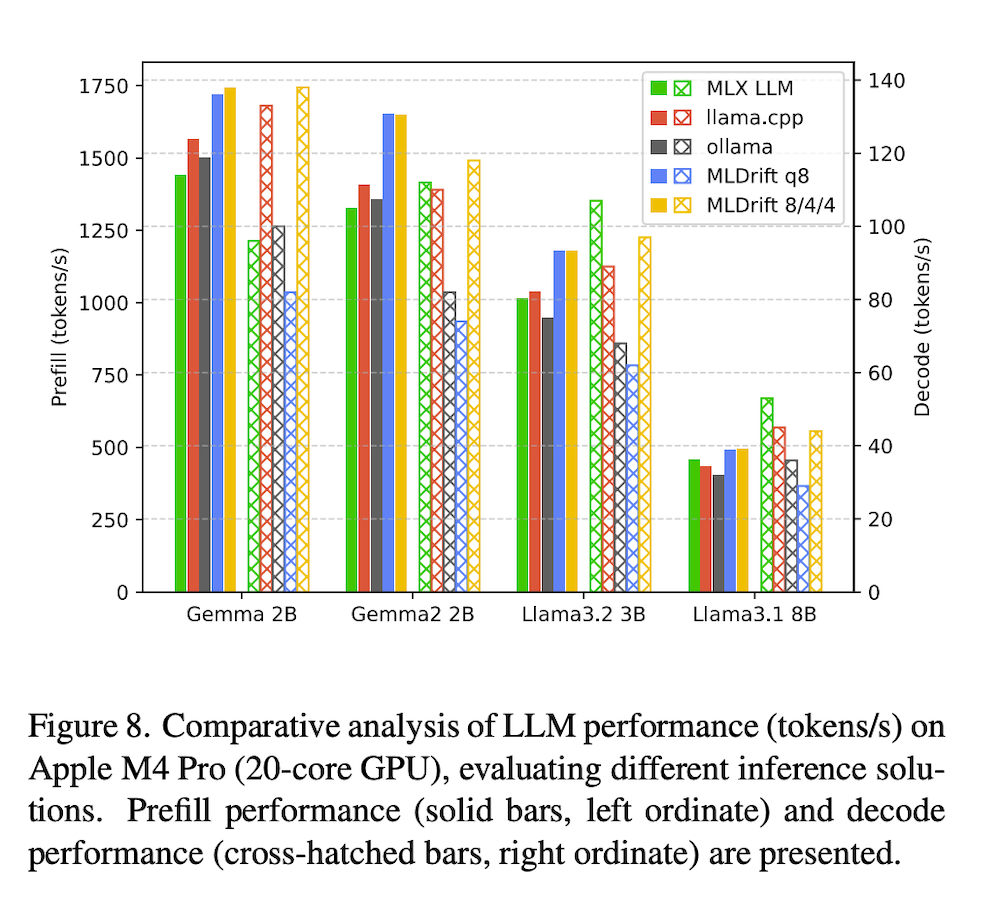
Gemma 2B、Gemma2 2B、Llama 3.2 3B、Llama 3.1 8Bの4つのオープンウェイトモデルを使用して、ML Driftの推論パフォーマンスを評価しました。モバイルおよびデスクトップのプラットフォームで、llama.cpp、ollama、torchchat、MLC LLM、MLX LMなどの確立されたLLM GPU推論ソリューションと比較しました。Qualcomm Adreno GPUでは、ML DriftのOpenCLバックエンドが他のオープンソースLLM推論ソリューションと比較して、トークンのプレフィルで5〜11倍の高速化を達成しました。NVIDIA GeForce RTX 4090上でのデコードパフォーマンスは、llama.cppと比較して5%〜25%のパフォーマンス低下を示しましたが、ollamaやtorchchatを上回りました。Apple M4 Pro上では、ML DriftのMetal実装がトークンプレフィルフェーズでllama.cppベンチマークより14%、MLX LLMより20%の速度向上を示し、すべてのテストモデルでllama.cppとollamaを一貫して上回りました。
5. 結論
ML Driftは、テンサー仮想化を通じて論理テンサーインデックスと物理的GPUインデックスを分離することで、様々なGPU上での大規模生成モデルの効率的な展開を実現する新しい推論フレームワークです。デバイス特殊化、メモリ管理戦略、オペレータフュージョンと組み合わせることで、大幅なパフォーマンス向上を達成しています。モバイル、デスクトップ、Apple Silicon GPUなど多様なハードウェアプラットフォームでの評価により、既存のオープンソースソリューションと比較して桁違いの改善が示されました。今後の研究は、高度な量子化技術、スパーシティの組み込み、ベンダー拡張を活用した最新のMLワークロード向けの特殊命令の探求などに焦点を当てる予定です。