目次
CountingDINO: A Training-free Pipeline for Class-Agnostic Counting using Unsupervised Backbones
この論文は、ラベルやトレーニングデータなしで、クラスに依存しない物体のカウントを行うための新しい手法「CountingDINO」を提案しています。
CountingDINOは、完全に教師なしの特徴抽出器を用いることで、ラベル付きデータなしで高精度なクラスに依存しないオブジェクトカウントを実現する革新的なフレームワークです。
論文:https://arxiv.org/abs/2504.16570
リポジトリ:https://lorebianchi98.github.io/CountingDINO/
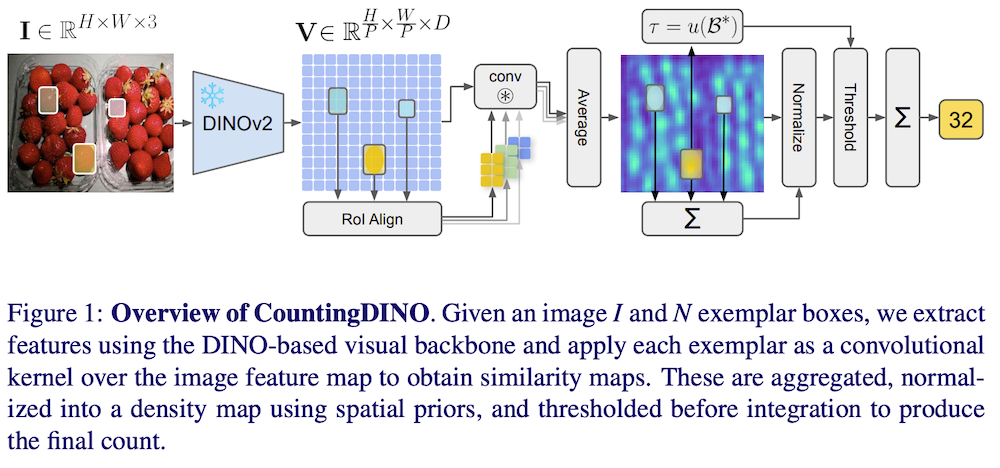
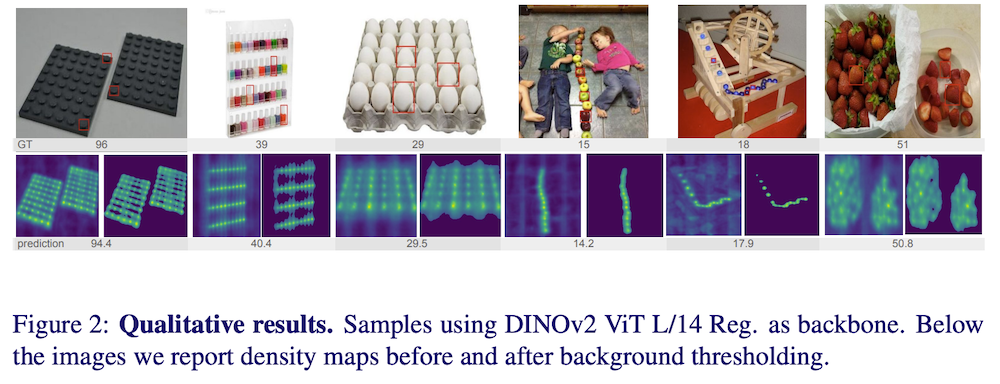

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
この論文では、クラスに依存しないカウント(CAC)が、事前に定義されたカテゴリに制限されることなく、画像内のオブジェクトの数を推定することを目指しています。しかし、現在の例示ベースのCAC手法は、推論時に柔軟性を提供する一方で、トレーニングにラベル付きデータに大きく依存しているため、多くの下流の使用例に対するスケーラビリティと一般化が制限されています。
本論文では、完全に教師なしの特徴抽出器を利用した、初のトレーニング不要の例示ベースのCACフレームワークであるCountingDINOを提案します。具体的には、自己教師ありの視覚専用バックボーンを用いてオブジェクトに関する特徴を抽出し、提案された全体のパイプラインを通じて注釈データの必要性を排除します。推論時には、DINO特徴からROI-Alignを介して潜在的なオブジェクトプロトタイプを抽出し、それらを畳み込みカーネルとして使用して類似度マップを生成します。これらは、シンプルながら効果的な正規化スキームを通じて密度マップに変換されます。
我々のアプローチは、FSC-147ベンチマークで評価され、同じラベルなしおよびトレーニングなしの設定で最先端の教師なしオブジェクト検出器に基づくベースラインを一貫して上回ります。さらに、我々は教師ありバックボーンに依存するトレーニング不要の手法、教師なしの非トレーニング不要手法、さらにはいくつかの完全に教師ありの最先端アプローチを上回る競争力のある結果を達成しています。これは、ラベルなしおよびトレーニングなしのCACがスケーラブルかつ効果的であることを示しています。
1. イントロダクション
Class-agnostic counting (CAC)は、ユーザーが推論時に対象カテゴリを定義できるようにすることで、クラス固有の再トレーニングの必要性を取り除きます。これは車両、人、細胞、動物などの事前定義されたオブジェクトタイプに依存するクラス固有のカウンティングアプローチの限界に対処します。しかし、既存のCACモデルは依然としてアノテーション付きのトレーニングデータに大きく依存しています。本論文では、CountingDINOを導入します。これは、ラベル付きデータをどの段階でも必要としない初のトレーニングフリーのエグゼンプラーベースのCACフレームワークです。我々のアプローチは、自己教師あり学習されたDINOバックボーンを使用して、アノテーション付きデータなしでオブジェクト認識特徴を抽出します。
2. 関連研究
2.1 エグゼンプラーベースのクラス非依存カウンティング
カテゴリ特定のオブジェクトカウンティングは、人、車両、昆虫、生物学的構造などのカウンティングに幅広い実世界のアプリケーションを持つコンピュータビジョンの長年のタスクです。密度マップ回帰はCACの有効なアプローチであり、検出ベースの手法を上回りますが、カテゴリ固有のアノテーションとトレーニングへの依存がスケーラビリティと一般化を制限します。FamNet、RCAC、BMNet、LOCA、PseCo、CACViT、DAVEなどの最近の手法は様々なアプローチを提案していますが、ほとんどが教師あり学習を必要とします。UnCounTRは自己コラージュを使用し、TFPOCとOmniCountはSAMを利用するトレーニングフリーのパイプラインを提案していますが、完全にラベルフリーではありません。
2.2 教師なし視覚バックボーン
DINO系列などの自己教師あり学習モデルは、教師なしでも分類や局所化に非常に効果的な表現を生成することが示されています。DINOはビジョントランスフォーマーに基づき自己蒸留で訓練され、パッチレベルの特徴がラベルなしでも豊かな意味情報を捉えることを示しています。本研究では、完全に教師なしのバックボーンを活用した初のトレーニングフリーのエグゼンプラーベースCACフレームワークを提案します。
3. 手法
我々の手法は、同じ画像から少数のエグゼンプラーバウンディングボックスが与えられた時に、そのオブジェクトクラスのインスタンス総数を推定することを目的とします。これを実現するために、DINOの自己教師あり学習されたバックボーンのオブジェクト理解能力を活用します。
3.1 DINOベースの特徴抽出
入力画像をDINOベースの自己教師あり視覚バックボーンに通すことで密な特徴マップを生成します。各エグゼンプラーに対して、バウンディングボックス座標を使ってROI-Alignを適用し、エグゼンプラーの特徴表現を抽出します。エグゼンプラー表現を改良するために、バウンディングボックス内で中心に置かれた楕円形の重み付けマスクを適用します。これは周辺領域を減衰させ、中心を強調する効果があります。
3.2 類似度マップ生成
各プールされたエグゼンプラー特徴をコンボリューショナルカーネルとして画像特徴マップに適用し、2D類似度マップを作成します。これを各エグゼンプラーバウンディングボックスについて繰り返し、得られた類似度マップを平均して単一の集約類似度マップを得ます。
3.3 密度マップの正規化
集約された類似度マップはオブジェクトインスタンスの発生確率が高い領域を強調しますが、各オブジェクトインスタンスが1に積分されるような正規化が必要です。入力として提供されたNつのエグゼンプラーバウンディングボックスを活用し、それらの領域がちょうどNにカウントされるように正規化係数を推定します。
3.4 密度マップ寄与のしきい値処理
類似度マップはオブジェクト領域を強調しますが、背景にも低い活性化が含まれ、積分時に過剰カウントの原因となります。これに対処するため、各エグゼンプラー領域内の単位カウントに基づいてしきい値を設定し、低活性化領域を抑制します。
3.5 空間解像度の向上
DINOの空間解像度が小さなオブジェクトを捉えるのに十分でない場合のために、入力画像を重複しない均等な四分割に分割し、各部分画像を独立して処理します。各四分割から特徴を抽出した後、元の空間配置に従って特徴マップを再組み立てし、より高解像度の表現を得ます。
4. 実験評価
4.1 データセットと評価指標
FSC-147データセットを使用して評価を行いました。このデータセットは6,135枚の画像からなり、147オブジェクトクラスが含まれており、各画像には3つのエグゼンプラーバウンディングボックスが提供されています。評価には平均絶対誤差(MAE)と二乗平均平方根誤差(RMSE)を使用しました。
4.2 ベースライン
CountingDINOが教師なしバックボーンを使用した初のトレーニングフリーエグゼンプラーベースのCAC手法であるため、CutLERを適応させたベースラインを設計しました。CutLERは、DINO特徴から得られた擬似ラベルを活用する教師なしオブジェクト検出器です。検出されたオブジェクトとエグゼンプラー間の類似度に基づいてフィルタリングを行います。
4.3 最先端手法との比較
我々の手法を、TFPOC、OmniCount、UnCounTR、UnCounTRv2、FamNet、RCAC、BMNet、LOCA、PseCo、CACViT、DAVEなど様々な最先端CAC手法と比較しました。完全にトレーニングフリーで教師なしのアプローチにもかかわらず、特にDINOv2特徴を使用した場合、競争力のある性能を達成しました。
4.4 アブレーション研究
いくつかの重要な要素についてアブレーション実験を行いました:
- 楕円形の仮定:楕円形の重み付けマスクを使用することで性能が大幅に向上
- 密度マップのしきい値:背景活性化の抑制により、MAEとRMSEの両方が改善
- 異なる解像度:画像分割による入力解像度の増加が性能向上に寄与
- 視覚バックボーン:DINOv2がDINOより一貫して優れており、MAEやCLIPより大幅に性能が高い
- エグゼンプラー数:エグゼンプラー数が増えるほど精度が向上、特に1から2への増加で大きな改善が見られた
5. 結論
本研究では、完全に教師なしでトレーニングフリーのエグゼンプラーベースのクラス非依存カウンティングフレームワークを初めて導入しました。DINOからの自己教師あり特徴を活用することで、既存のCAC手法の主要な制限である高コストな人間のアノテーションへの依存を解消しました。我々のアプローチはFSC-147ベンチマークで競争力のある性能を達成し、同じ設定のベースラインを上回り、教師ありバックボーンに依存するトレーニングフリー手法、トレーニングフリーでない教師なし手法、さらには完全に教師あり手法と比較しても優れた結果を示しました。