目次
Graph-KV: Breaking Sequence via Injecting Structural Biases into Large Language Models
この論文は、構造的バイアスを大規模言語モデルに注入することで、シーケンスの制約を克服し、情報の構造的依存関係をより効果的にモデル化する新しい手法「Graph-KV」を提案しています。
Graph-KVは、構造的帰納バイアスを取り入れることで、シリアライズされた入力の制約を克服し、特にリトリーバル強化生成やマルチホップ推論のタスクにおいて、モデルの性能を大幅に向上させる新しいアプローチを提供します。
論文:https://arxiv.org/abs/2506.07334
リポジトリ:https://github.com/Graph-COM/GraphKV

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
現代の大規模言語モデル(LLM)は本質的に自己回帰的であり、入力を構造的依存関係に関係なく平面的なシーケンスにシリアライズする必要があります。このシリアライズは、特にリトリーバル強化生成(RAG)や、ネイティブなグラフ構造を持つデータに対する推論といったタスクにおいて、モデルが構造的帰納バイアスを活用する能力を妨げます。
そこで、私たちはこの制限を克服する可能性を持つGraph-KVを提案します。Graph-KVは、テキストセグメントのKVキャッシュを凝縮された表現として利用し、構造的帰納バイアスを通じてそれらの相互作用を制御します。このフレームワークでは、「ターゲット」セグメントは、シリアライズされたシーケンス内のすべての前のセグメントではなく、指定された「ソース」セグメントのKVキャッシュのみに選択的に注意を払います。このアプローチは、グラフ構造のブロックマスクを誘導し、注意を疎にし、LLM内でメッセージパッシングのようなステップを可能にします。さらに、ソースおよびターゲットセグメントに戦略的に配置された位置エンコーディングは、位置バイアスとコンテキストウィンドウの消費を削減します。
私たちは、Graph-KVを以下の3つのシナリオで評価しました:(1)直接推論、マルチホップ推論、長文理解を含む7つのRAGベンチマーク、(2)引用エゴグラフとして構造化されたフルテキストの学術論文に対する新しいQAタスクであるARXIV-QA、(3)引用ネットワーク内の論文トピック分類。位置バイアスを効果的に削減し、構造的帰納バイアスを活用することにより、Graph-KVはさまざまな設定で標準的なコストのかかるシーケンシャルエンコーディングを大幅に上回ります。
1. はじめに
現代の大規模言語モデル(LLM)は本質的に自己回帰的であり、構造的依存関係に関係なく、入力を平坦な系列にシリアル化することを要求する。このシリアル化は、特に検索拡張生成(RAG)やネイティブなグラフ構造を持つデータでの推論において、構造的帰納バイアスを活用するモデルの能力を阻害する。本論文では、この制限を克服する可能性を持つGraph-KVを紹介する。Graph-KVは、テキストセグメントのKV-キャッシュを凝縮表現として活用し、構造的帰納バイアスを通じてそれらの相互作用を制御する。
2. 関連研究
LLMにおける位置バイアス、並列エンコーディングとブロック注意、LLMによる構造化データのモデリング、ノイズの多いマルチホップ推論の課題について説明している。位置バイアスは入力データの順序によってLLMの性能が悪影響を受ける現象で、位置埋め込みと因果注意メカニズムの相互作用から生じる。並列エンコーディングは二次計算複雑度を回避するためにドキュメントを個別に並列処理するが、文書間依存関係のモデリングができない共通の制約がある。
3. 方法論
3.1 Graph-KV
Graph-KVは構造認識注意メカニズムと適切に割り当てられた共有位置エンコーディングを用いて構造的帰納バイアスを注入する。まず、各テキストチャンクの初期KV表現をオフラインで並列エンコーディングし、グラフ構造に従って「ターゲット」チャンクの表現を「ソース」チャンクとの注意メカニズムによって更新する。位置エンコーディングの割り当てでは、独立したテキストチャンクは共有範囲[0, L)に、構造的依存関係がある場合のターゲットチャンクは[L, 2L)に割り当てられ、位置バイアスを軽減し文脈効率を向上させる。
4. 実験
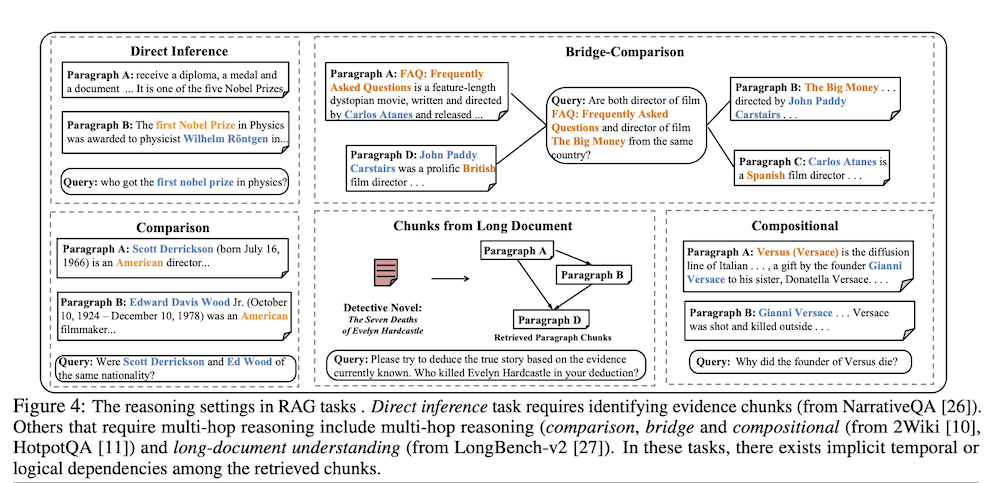
4.1 タスク1:検索拡張生成(RAG)
7つのRAGベンチマークで評価し、直接推論、マルチホップ推論、長文書理解をカバーした。Graph-KVはバイパータイトグラフを用いて構造バイアスを確立し、類似度スコアが上位m個のチャンクをソースチャンクとして扱う。結果として、Graph-KV-Fullが一般的に疎化された変種を上回り、マルチホップ推論を重視するタスクでは逐次エンコーディングを約2-10%上回る性能を示した。
4.2 タスク2:ARXIV-QA – 全文を用いた引用ネットワークでのマルチホップ推論
arXivデータセットから100の学術論文とその参考文献を用いた新しいタスクを作成した。60の中心論文に対する技術的質問に答えるには、論文の主要文脈の解釈、引用関係の理解、参考文献の文脈理解が必要である。平均約88kトークンの文脈処理が求められる。Graph-KVは中心論文と全ての参考文献を接続するターゲット-ソースペアを形成し、ディストラクタが含まれる場合の位置バイアスを回避して一貫して最高の性能を達成した。
4.3 論文トピック分類
CoraとPubmed引用グラフを用いた論文トピック分類タスクで評価した。中心論文をアブストラクト、タイトル、近傍に基づいて複数のカテゴリに分類するタスクで、各中心論文は数百の参考文献を持つ可能性がある。Graph-KVは参考文献への依存関係を組み込むことで、逐次エンコーディングと並列テキストエンコーディングベースラインの両方を上回る性能を示した。従来の手法がテキスト埋め込み潜在空間での分類やアダプタ訓練を行うのに対し、Graph-KVはLLMの基本メカニズムを調整する初のアプローチである。
4.4 タスク4:スケーラビリティと効率性のストレステスト
合成データでのストレステストを実施し、Graph-KVは逐次エンコーディングと比較して3倍以上の近傍数をエンコードできることを確認した。time-to-first-token(TTFT)レイテンシの評価では、構造的バイアスを注入したテキストチャンクの事前充填により、逐次エンコーディングでは実現できない効率性の向上を実現した。これらの利点は、逐次エンコーディングでは実現不可能な、構造的バイアスを注入したテキストチャンクの事前充填機能に起因する。
5. 結論と今後の研究
Graph-KVは、注意メカニズムに構造的帰納バイアスを直接注入し、戦略的位置エンコーディングを採用することで、自己回帰LLMの構造化データ処理における制限を克服する新しいアプローチである。RAG、新しい学術QAベンチマーク(ARXIV-QA)、論文トピック分類にわたる評価で、特にマルチホップ推論と長文脈シナリオにおいて、逐次および並列エンコーディングベースラインを大幅に上回る性能を実証した。現在は1ホップ構造依存関係を評価しているが、より複雑なデータトポロジーを理解するための構造依存関係活用の核心的アイデアは、より広範な研究に重要な可能性を持つ。