目次
From Struggle (06-2024) to Mastery (02-2025) LLMs Conquer Advanced Algorithm Exams and Pave the Way for Editorial Generation
この論文は、最新の大規模言語モデル(LLM)が大学レベルの高度なアルゴリズム試験において優れた問題解決能力を示し、教育環境における生成的AIの活用可能性を探求するものです。
この論文の特徴は、最新の大規模言語モデル(LLMs)が大学レベルのアルゴリズム試験でトップパフォーマンスの学生と同等のスコアを達成し、特に複雑な多段階の問題に対する堅牢な推論能力を示した点です。
論文:https://arxiv.org/abs/2506.04965

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
この論文では、最先端の大規模言語モデル(LLMs)の大学レベルのアルゴリズム試験における性能の包括的な評価を示しています。複数のモデルをルーマニアの試験とその高品質な英訳の両方でテストし、LLMsの問題解決能力、一貫性、そして多言語性能を分析しました。実証研究の結果、最新モデルはトップパフォーマンスの学生と同等のスコアを達成するだけでなく、複雑な多段階のアルゴリズム課題においても堅牢な推論能力を示すことが明らかになりましたが、グラフベースのタスクには依然として課題が残っています。
これらの結果を踏まえ、LLMsが高品質な編集コンテンツを生成することにより教育環境をサポートする可能性を探求し、教員に学生へのフィードバックを向上させるための強力なツールを提供します。ここで議論された知見とベストプラクティスは、高度なアルゴリズム教育における生成AIのさらなる統合への道を開きます。
1. はじめに
大規模言語モデル(LLMs)の急速な進歩により、複雑なアルゴリズム問題を解決する能力が劇的に向上した。歴史的にLLMsは多分野で優秀だったが、高度なアルゴリズム問題での性能は限定的だった。しかし過去1年間で大幅な改善が見られ、最新のモデルは複雑なアルゴリズム課題を驚くべき精度で解決できるようになった。本論文では、大学レベルの高度アルゴリズム試験という文脈でこれらの進歩の詳細な分析を行う。また、LLM技術の教育環境での応用として、詳細な採点スキーム生成と高品質な解説コンテンツ生成の2つの有望なアプリケーションを探索する。
2. 関連研究
本研究はLLMs、アルゴリズム問題解決、教育応用の交差点に関する研究を基盤としている。LLMsは競技プログラミング環境での応用により複雑なタスクに取り組む能力が探求されている。教育におけるLLMsの使用は急速に発展している分野であり、採点・評価での可能性や自動フィードバック生成に関する研究が進められている。既存研究とは異なり、本研究は実世界の試験設定での高度なSTEMコンテンツに焦点を当て、ルーマニア語アルゴリズム試験での採点一貫性と性能を評価し、低リソース言語ルーマニア語での新規データセットを提供する点で独自性を持つ。
3. 試験解答者としてのLLMs: 実証評価
11のアルゴリズム問題からなる挑戦的なコンピュータサイエンス試験において、LLMsの問題解決能力の徹底的な評価を実施した。この試験は公開データセットとしてリリースされ、グラフに焦点を当てた高度アルゴリズムをカバーし、元々ルーマニア語で実施された。本章では手法論を詳述し、多様な最先端LLMsの性能に焦点を当てた評価結果を提示する。
3.1 手法論
ChatBot Arena LLMリーダーボードから選択した多様なアーキテクチャと訓練手法を持つ幅広いLLMsを評価した。OpenAI UI、Google AI Studio、Together AIプラットフォームを使用し、各ファミリーから数モデルずつ選択した。評価にはGPT-4 Legacy、GPT-4o、o1、o3-mini、Gemini 2.0 Flash、DeepSeekR1、Claude Sonnet 3.5、Llama3.3-70Bなどを含む。試験は元のルーマニア語版と高品質英語翻訳版の両方で実施され、LLMsには11問全体を個別ではなく一回のインタラクションで解答するよう指示した。
3.2 新モデルが旧モデルを凌駕
最先端LLMsの高度アルゴリズム試験での性能は、モデルのリリース日と強い相関を示した。過去4ヶ月以内にリリースされたo3-miniやGemini2.0 Flashなどのモデルは80点以上(上位5%)や70点以上(上位15%)を一貫して獲得した。対照的に、古いモデルは40点を下回ることが多かった。古いモデルは複雑なアルゴリズム問題だけでなく、試験の広範囲なコンテキスト処理でも苦戦しており、より大きく複雑なコンテキストウィンドウの処理が新旧LLMs間の重要な差別化要因であることを示唆している。
3.3 試験採点におけるLLMsの一貫性分析
チューター用途でのLLMs評価を目的として、試験問題解決における一貫性を検証した。o3-mini、Gemini 2.0 Flash、Sonnet 3.5の3つの代表的モデルを選択し、各モデルに5回の異なるセッションで試験を解答させ、各解答を独立して採点した。o3-miniとGemini 2.0 Flashは低い標準偏差(それぞれ2.41と2.70)で高い一貫性を示した一方、Sonnet 3.5は16.95という大きな変動性を示した。Sonnet 3.5の詳細分析では、5回中4回は約50点で類似していたが、1回は77点という優秀な成績を記録するブラックスワン的状況が見られた。
3.4 協調解答
異なるデータセットで訓練されたLLMsは様々な強みを示すため、複数の解答を組み合わせることでより効果的な解答者を作れるかを探索した。RunAvg(各LLMに自身の過去3回の答えを提供)とRunAvgAll(各LLMに異なるLLMsからの3つの解答を提供)の2つの実験を実施した。RunAvg戦略では自己強化により標準的行動を維持する傾向で小さな変化しか見られなかった。対照的にRunAvgAll戦略では、Gemini 2.0 Flash、Sonnet 3.5、DeepSeekR1で大幅な向上、o3-miniで軽微な減少を示した。これは最初のモデル群がo3-miniのより良い解答への露出から恩恵を受けた一方、o3-miniは低品質結果にのみアクセスしたためである。
3.5 LLMスコアと学生成績の比較
様々なLLMsの成績を学生の試験結果と比較した。o3-miniとGemini2.0 Flashは学生成績の上位パーセンタイル内の得点を達成し、良好な成績を示した。対照的にMixtral-8x22BやGPT-4 Legacyなどのモデルはより低いランクとなった。o3-miniは86.60点で98パーセンタイル、Gemini2.0 Flashは72.30点で88パーセンタイルを達成した。学生コホートの約5%が全国コンピュータサイエンスオリンピアードに参加経験があることを考慮すると、o3-miniの成績はクラス上位3%のみならず、おそらく全国上位1%に位置する。
3.6 LLMs対学生のタスク分析
LLMsと学生の各問題での結果を比較した。LLMsが大幅に劣る問題(問題1と3など)は、典型的なアルゴリズムの適用よりもグラフの視覚的分析を要求するものであった。人間の学生は二部グラフの視覚化やグラフ構造の分析など視覚的タスクを容易に解決できるが、LLMsは顕著な課題に直面する。問題1では、ほとんどのLLMsが有効な解答の正しい特定に失敗した。例えば4oは長いテキストの後に「十分に大きな二部成分が存在しないようです」と出力し、DeepSeekR1は無効な解答を出力した。一方でLLMsは理論的演習の証明や文字列アルゴリズムの具体例への適用、問題解決で強い性能を示した。
3.7 ルーマニア語対英語での性能
同じ高度アルゴリズム試験のルーマニア語版と英語翻訳版で各モデルを評価した。性能差をΔ = GradeEn – GradeRoとして定義した。新しいモデル(グループA)はルーマニア語で統計的に重要でない小さな差(-0.69)を示した一方、古いモデル(グループB)は英語でより大きな向上(+9.0)を見せた。4oやMistral-7B-v0.3などの古いモデルは英語への強いバイアスを示し、おそらく不均衡な多言語データを反映している。一方、o3-mini、o3-mini-high、Gemini2.0 FlashExpなどの最新モデルははるかに小さなギャップを示し、改善された多言語訓練を示唆している。
4. LLM支援採点スキームと解説生成
4.1 人間-AI協調による採点スキーム
コース指導者と最高性能のLLM解答者であるo3-miniとGemini Flash 2.0との人間-AI協調を通じて採点スキームを開発した。このプロセスでは、LLMsに解答の簡潔な説明を提供し、これらを包括的な採点スキームに拡張するよう促し、指導者が途中でエラーを精緻化・修正した。結果として例外的に詳細な採点スキームが得られ、GitHubのデータセット内で見つけることができる。この採点スキームは典型的なものよりもはるかに広範囲で、指導者が手動でこのような徹底的な評価フレームワークを作成する時間やエネルギーを持つことは稀である。
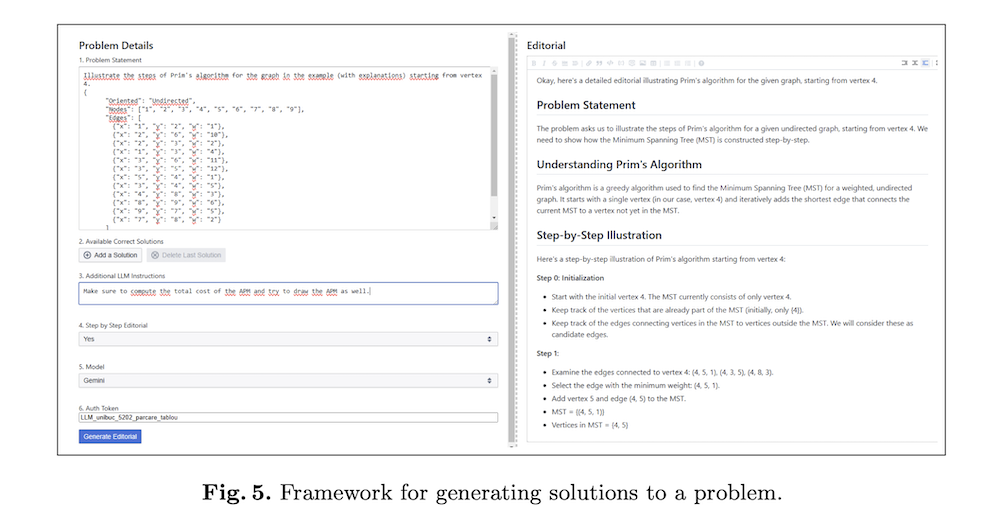
4.2 ウェブベースプラットフォーム
技術の実用性を示すため、ウェブベースアプリケーションを設計・実装した。価格的理由により、プラットフォームはGemini2.0 FlashとMistral largeのみをサポートし、ユーザーはリクエスト送信時に自由に選択できる。アプリケーションは教授と学生の作業を加速化するツールを目指し、それぞれ解説/採点スキーム作成と学習体験の向上を図る。現代のLLMsが複雑なタスクに対して一回の試行で有用な解答、説明、解説を生成するのに十分優秀で一貫していることに基づいている。現在はコンピュータサイエンスにより焦点を当てているが、幅広い分野をサポートするよう容易に修正可能である。
5. 結論
本研究では、複雑な大学レベルアルゴリズム試験に取り組む最先端LLMsの進歩を探求した。実証評価により、o3-miniやGemini2.0 Flashなどのモデルが最高性能の学生と同等であることを示し、多段階アルゴリズム課題における堅固な推論スキルと一貫性を実証した。一貫性分析では、アルゴリズムタスクでのLLM一貫性と性能間の強い相関を示すメトリックを提供し、改善されたモデルがより高い一貫性を示すことを示した。理論的演習と実用的応用の両方で優秀な現代LLMsは、高品質な解説コンテンツを生成することで教育環境をサポートできる。これらのモデルの一貫性と性能により、詳細な採点スキームと実用的フィードバックを提供する指導者と学生にとって価値あるツールとなる。
6. 今後の研究
LLMsにおける残存課題、特にグラフベースタスクの処理と採点の公平性・正確性の確保について明らかになった。今後の研究では、視覚的・テキストデータのシームレスな解釈のためのマルチモーダル機能を探索し、対話的で効果的な学習体験のためのLLMsの完全な可能性を解放するため、これらの制限に対処すべきである。また、複雑なアルゴリズム問題に対する詳細な段階的説明を提供するLLM生成解説コンテンツを活用する専用フィードバックループの開発も有望な方向性である。さらに、高度アルゴリズムコースでの学生学習成果に対するこのような解説フィードバックの影響を測定する統制研究の実施が、これらの技術の検証と生成的チューターシステムのベストプラクティス確立に不可欠である。