目次
ScaleMCP: Dynamic and Auto-Synchronizing Model Context Protocol Tools for LLM Agents
この論文は、Large Language Models (LLMs) が外部ツールと動的に相互作用できるようにするためのモデルコンテキストプロトコル(MCP)を活用した新しいツール選択アプローチ「ScaleMCP」を提案し、LLMエージェントの自律性と効率を向上させる方法を示しています。
ScaleMCPは、LLMエージェントが外部ツールを動的に管理し、MCPサーバーとリアルタイムで自動同期することで、従来の手動更新に依存せず、エージェントの自律性を大幅に向上させる新しいツール選択アプローチを提供します。
論文:https://arxiv.org/abs/2505.06416

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
最近の大規模言語モデル(LLM)の進展とモデルコンテキストプロトコル(MCP)の導入により、LLMエージェントの外部ツールやAPIとの動的な相互作用能力が大幅に拡張されました。しかし、既存のツール選択フレームワークはMCPサーバーを統合せず、エラーの発生しやすい手動更新に依存しているため、モノリシックなローカルツールリポジトリに重複や不一致、非効率が生じています。さらに、現在のアプローチはLLMエージェントが呼び出される前にツール選択を抽象化しているため、エージェントの自律性が制限され、マルチターンの対話中に動的に再クエリを行う能力が妨げられています。
これらの問題に対処するために、我々はScaleMCPという新しいツール選択アプローチを提案します。これは、LLMエージェントにMCPツールリトリーバーを動的に装備し、エージェントが自らツールをメモリーに追加する自律性を与えるとともに、CRUD(作成、読み取り、更新、削除)操作を通じてMCPサーバーとの間で単一の真実のソースを持つ自動同期ツールストレージシステムパイプラインを提供します。また、ツール文書の重要なコンポーネント(例えばツール名や合成質問など)を埋め込みプロセス中に選択的に強調することを目的とした新しい埋め込み戦略、ツール文書加重平均(TDWA)を提案します。
5,000の金融指標MCPサーバーからなるデータセットを用いた包括的な評価を行った結果、ツールリトリーバルとエージェント呼び出しのパフォーマンスにおいて大幅な改善が見られ、ScaleMCPのスケーラブルで動的なツール選択と呼び出しの効果が強調されました。
1. 序論
大規模言語モデル(LLM)とツール学習の最近の進歩により、LLMエージェントは外部ツールやAPIと動的に対話できるようになりました。モデルコンテキストプロトコル(MCP)の導入により、LLMと外部ツール、データソース、プロンプトの間の接続が標準化されました。しかし、既存のツール選択フレームワークには3つの重要な制限があります:
- MCPサーバーが統合されていない
- ツール定義とツールストレージシステム間の同期に手動更新が必要
- ツール選択プロセスがLLM呼び出しプロセスの外部で抽象化されている
これらの課題に対処するため、我々はScaleMCPを提案します。
2. 背景
2.1 モデルコンテキストプロトコル(MCP)
モデルコンテキストプロトコル(MCP)は、LLMと外部ツール、データソース、プロンプトの統合を標準化するためにAnthropicによって開発されたオープンプロトコルです。MCPにより、開発者はツール、API、データ、プロンプトをMCPサーバーを通じて公開したり、これらのサーバーに接続するAIアプリケーション(MCPクライアント)を構築したりできます。最近の研究では、MCPに関連するセキュリティとプライバシーの懸念が指摘されていますが、MCPはLLMエージェントツール統合の現在の標準として確立されつつあります。
2.2 ツール選択と検索
LLMは、直接アクセスして呼び出せるツールや関数の数に制限があります。一方では、複雑なマルチホップツール使用がLLMのツール選択と順序付けに関する推論能力を制約します。他方では、OpenAIやAnthropicなどのモデルプロバイダーは、一度に128以上のツールの統合を防ぐ厳格なAPI制限を適用しています。先行研究では、高度なRAGベースの手法を用いて、関連するツールのみを推論時に動的に装備することで、この制約を超えたスケーリングを行っています。
2.3 LLM呼び出しのためのツール呼び出し
ツール選択がLLMエージェントに装備する関連ツールの選定に関わる一方で、先行研究では純粋なLLMツール呼び出しにも焦点を当てています。LLMツール呼び出しのための現代的な微調整アプローチには、MOLoRA、効率的なツリーベースの手法、または複数のAIエージェントを使用した高品質ツール命令データセットの作成が含まれます。この論文では、OpenAI、Google、Anthropic、Metaのオリジナルのままのモデルを使用するプラグアンドプレイ手法に焦点を当てています。
3. 方法論
3.1 ScaleMCPの概要
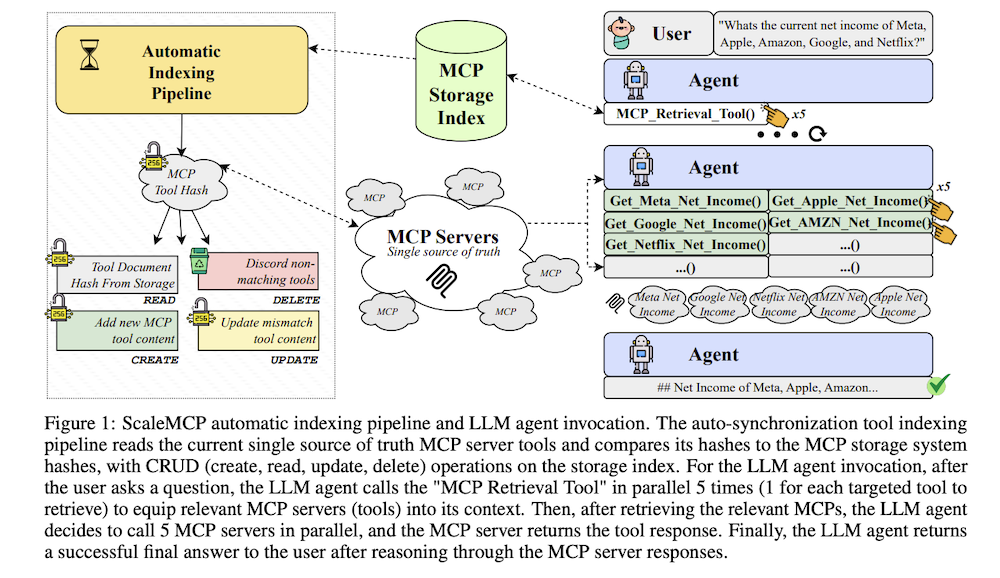
我々はScaleMCPを導入します。これは、MCPサーバー(ツール)用のLLMエージェントツール選択に対する新しいアプローチで、自動同期ツールストレージシステムインデックス作成パイプラインと、ツール呼び出しの自律性をLLMエージェントに与える現代的なエージェントRAGアプローチを包含します。ScaleMCPは、LLMの組み込み関数呼び出し機能を使用することで、LLMエージェントが数千のMCPサーバーにアクセスして使用できるようにし、ツールストレージを自律的に管理します。
3.2 ScaleMCP自動同期インデックス作成パイプライン
ツールストレージシステムは、ツール選択のユースケースと検索方法によって選択できます。最も一般的なストレージシステムはベクトルデータベースとベクトル検索ですが、グラフデータベース、ハイブリッドグラフRAGアプローチ、または標準データベースでの語彙的用語マッチングなどの他のオプションもあります。ScaleMCPは、MCPサーバーを真実の単一ソースとして使用する自動同期ツールストレージインデックス作成パイプラインによって駆動されます。
3.2.1 新しい埋め込みマッピング関数ツールドキュメント重み付き平均
先行研究では、ツールドキュメントコンポーネントの連結や単純平均、または単純なツール説明のみを使用しています。我々は、ツール固有のユースケース向けの新しい埋め込み関数パラダイムであるツールドキュメント重み付き平均(TDWA)を導入します。これにより、各ツールドキュメントコンポーネントの重要性が埋め込みの重み付き平均に寄与できるようになります。
3.3 ScaleMCP LLM呼び出し
LLM呼び出し内でスケーラブルなツール選択を可能にするために、LLMエージェントには特殊なMCP検索ツールが装備されており、関連するMCPサーバーを取得するためのキーワードを渡すことができます。LLMエージェントがMCP検索ツールを使用すると、フレームワークは自動的に取得されたMCPサーバーをLLMのコンテキストにロードし、関数呼び出しを使用して新しいツールをLLMに「バインド」します。
4. データセット構築
ScaleMCPの機能を評価するために、5,000の企業ベースの財務メトリックMCPサーバーと、期待されるツール呼び出しを伴う対応するインスタンスまたはユーザークエリのセットからなる大規模な実世界のデータセットを作成しました。
4.1 ツール作成
Fortune 1000企業から始め、各企業に対して5つの決定論的ツールを生成しました:
- get_{company}_current_stock_price
- get_{company}_stock_price_history
- get_{company}_analyst_price_targets
- get_{company}_revenue
- get_{company}_net_income
MCPサーバーの提供に利用したフレームワーク:https://github.com/jlowin/fastmcp
4.1.1 ツールドキュメント合成質問作成
ベクトル空間での各ツールの表現を改善するために、LLMを使用して各ツールテンプレートに対して0、5、または10の合成自然言語質問を生成し、ツールドキュメントを充実させました。
4.2 ユーザークエリインスタンス生成
ツールドキュメントに埋め込まれた合成質問に加えて、検索パフォーマンスとエージェント推論を評価するために設計されたスタンドアロンユーザークエリのセットを作成しました。約140,000のユーザークエリインスタンスを含む最終データセットは、企業、ツール、フレージングにわたる幅広い金融タスクをカバーしています。
5. 評価
5.1 実験1:MCPベクトルデータベース検索
5.1.1 実験設定
5,000のMCPサーバーで構成されるデータセットを使用して、異なる埋め込みモデルのMCPツールドキュメント検索における有効性を評価しました。5つの埋め込みモデルをテストし、各モデルを6つの検索構成(ベクトルのみの検索、ハイブリッド検索、BM25語彙検索、Cohereのクロスエンコーダリランカー、GPT-4oとClaude Sonnet 3.7を使用したLLMベースのリランカー)で評価しました。
5.1.2 結果分析
ベクトルのみの検索は、すべてのモデルで最高性能の埋め込みでもMAP値が0.50範囲と低いパフォーマンスを示しました。これは評価クエリが主にマルチホップであることに起因します。リランキング戦略は明確な改善を示し、GPT-4oとClaude Sonnet 3.7リランカーが全体で最強のスコアを示しました。
5.1.3 考察
これらの結果は、マルチホップ設定における従来のベクトル検索の重要な制限を確認します:単一のクエリ埋め込みは、複数の異なる検索ターゲットを捉えることができないことが多いです。これは、単一のクエリが複数(3-12)のゴールデンMCPツールを参照するケースでは、単一のベクトル表現がすべての関連ツールを効果的に検索する可能性が低いためです。
5.2 実験2:LLMエージェント評価
5.2.1 実験設定
DeepEvalフレームワークを使用して、OpenAIのgpt-4.1、gpt-4o、gpt-4o-mini、gpt-o4-miniやAnthropicのClaude 3.7 Sonnetを含む10のLLMエージェントの検索とツール呼び出しタスクにおけるエンドツーエンドのパフォーマンスを評価しました。各エージェントは3つの検索構成(BM25、TDWA埋め込みを使用したベクトル検索、Cohereリランカーを使用したベクトル検索)でテストされました。
5.2.2 結果
すべてのモデルの中で、gpt-o3はベクトル検索とCohereリランキングを組み合わせて94.4%という最高のタスク完了スコアを達成しました。対照的に、gpt-4o-miniは54.0%の最高ツール正確性と86.7%の強力なタスク完了スコアを達成し、全体的に最もバランスの取れたパフォーマーとなりました。
5.2.3 考察
結果は、現在のLLMベースのツール推論における重要な制限を明らかにしています:高品質なタスク出力は、低い基礎となるツール正確性を隠すことがあります。この問題は複雑なマルチホップクエリで増幅され、エージェントは単一の応答で複数のツール呼び出し(時には10以上)を編成する必要があります。
5.3 実験3:TDWA重み付け評価
5.3.1 実験設定
この実験では、検索有効性に対する異なるツールドキュメントストレージ戦略の影響を評価します。ツールあたりSQ = 10の固定合成質問数を使用して、3つの戦略を比較します:(1) Concat、すべてのツールコンポーネントの単純な非重み付き連結;(2) TDWA var-1、重み[0.2, 0.2, 0.2, 0.4];(3) TDWA var-2、重み[0.2, 0.3, 0, 0.5]。
5.3.2 結果
単純なベクトル検索では、単純なConcat戦略が両方のTDWAバリアントよりもNDCGとRecallで優れており、最高のトップ1パフォーマンス(0.634 NDCG、0.912 Recall)を達成しました。しかし、リランキングが適用されると、そのギャップは実質的に狭まります。
5.3.3 考察
ツールドキュメント重み付き平均(TDWA)は生のベクトル検索で単純な連結を上回りませんが、これらの結果はTDWAが非効果的であることを意味するものではありません。評価におけるConcat戦略の強さは、ツールデータセットの高度にキーワード駆動の性質(企業ティッカーや財務メトリックを持つツール名など)に由来する可能性が高いです。
6. 結論
大規模言語モデル(LLM)とモデルコンテキストプロトコル(MCP)の導入における進歩により、LLMエージェントの外部ツールとの動的なインタラクションが大幅に向上しました。しかし、既存のツール選択アプローチは、手動ストレージシステム同期、ローカルモノリシックツールリポジトリからの非効率性、およびエージェントの自律性の制限に関連する課題に直面し続けています。これらの問題に対処するために、我々はScaleMCPを導入しました。これは、LLMエージェントがマルチターンインタラクション中に膨大な量のMCPを自律的に管理できるようにするフレームワークです。