目次
この記事について
このブログシリーズでは、注目すべきオープンソースソフトウェア(OSS)を定期的に紹介していきます。連載第26回となる今回は、文書理解の分野で革新をもたらすことが期待されている「Donut」に焦点を当てます。
近年、デジタル化の進展により、ドキュメントのデジタル処理がますます重要になっています。特に、従来のOCR(光学文字認識)技術に依存せずに高度な文書理解を実現する方法が求められています。これに応える形で登場したのが「Donut」です。このツールは、OCRに頼らずに視覚的な文書分類や情報抽出を行うためのエンドツーエンドのトランスフォーマモデルを使用しています。
「Donut」を利用することで、様々な言語やドメインに対して柔軟な適応が可能となり、文書処理の効率が飛躍的に向上します。この革新的なツールを通じて、開発者やデータサイエンティストは、文書処理の課題をより迅速かつ正確に解決できるようになるでしょう。今回の記事では、Donutの概要やメリット、導入方法についてご紹介します。
リンク:https://github.com/clovaai/donut

本コンテンツは、弊社AI開発ツール「IXV」を用いたOSSツール紹介です。情報の正確性には努めておりますが、内容に誤りが含まれる可能性がございますのでご了承ください。
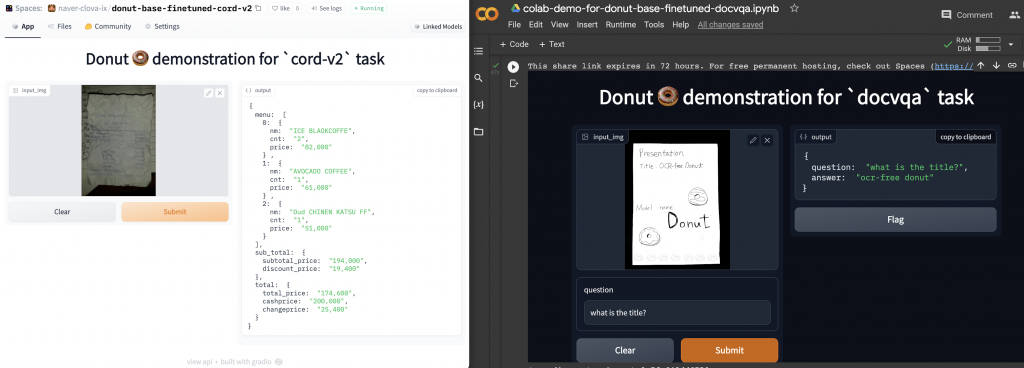
1. Donutでできること
Donut(Document Understanding Transformer)は、OCRを使用せずに文書を理解するためのエンドツーエンドのTransformerモデルです。Donutは、さまざまな視覚文書理解タスクにおいて、オフ-the-shelfのOCRエンジンやAPIを必要とせず、最先端のパフォーマンスを実現します。具体的には、以下のようなタスクに対応しています。
- 文書分類: Donutは、異なる種類の文書を分類する能力を持っています。
- 情報抽出: 文書から必要な情報を抽出することができます。
- 視覚的質問応答(VQA): 文書内の情報に基づいて質問に回答する機能を提供します。
- 合成文書生成(SynthDoG): 多様な言語やドメインに対応するためのモデルの事前学習をサポートします。
2. セットアップ手順
2.1 動作環境
Donutを使用するには、以下の動作環境が必要です。
- Python 3.7以上
- PyTorch 1.11.0以上
- torchvision 0.12.0以上
2.2 インストール方法
pipを使用してインストールする方法
pip install donut-python
GitHubリポジトリからクローンし、依存関係をインストールする方法
git clone https://github.com/clovaai/donut.git
cd donut/
conda create -n donut_official python=3.7
conda activate donut_official
pip install .
2.3 ライセンス
DonutはMITライセンスのもとで提供されています。詳細はリポジトリのライセンスセクションを参照してください。
3. 簡単な使い方
3.1 データの準備
Donutは、以下のデータセット構造を期待します。
dataset_name
├── test
│ ├── metadata.jsonl
│ ├── {image_path0}
│ ├── {image_path1}
│ ...
├── train
│ ├── metadata.jsonl
│ ├── {image_path0}
│ ├── {image_path1}
│ ...
└── validation
├── metadata.jsonl
├── {image_path0}
├── {image_path1}
...
3.2 モデルのトレーニング
文書分類タスクのトレーニングは、以下のコマンドで実行できます。
python train.py --config config/train_cord.yaml \
--pretrained_model_name_or_path "naver-clova-ix/donut-base" \
--dataset_name_or_paths '["naver-clova-ix/cord-v2"]' \
--exp_version "test_experiment"
3.3 推論と評価
トレーニング済みモデルを使用して、推論を行うには以下のコマンドを実行します。
python test.py --dataset_name_or_path naver-clova-ix/cord-v2 --pretrained_model_name_or_path ./result/train_cord/test_experiment --save_path ./result/output.json
結論
DonutはOCRを用いずに文書を理解するための強力なツールであり、文書分類や情報抽出、視覚的質問応答など多様なタスクに対応可能です。簡単なインストール手順と使い方を踏まえれば、すぐに始められるため、多くのプロジェクトに活用できることでしょう。興味のある方は、ぜひ公式リポジトリを訪れて、詳細なドキュメントやデモを確認してください。