目次
Towards Adaptive Memory-Based Optimization for Enhanced Retrieval-Augmented Generation
この論文は、オープンドメインの質問応答タスクにおいて、情報の取得と生成を最適化するための適応型メモリベースの手法「Amber」を提案し、複数のデータセットにおけるその効果を実証しています。
本論文の特徴は、複数のエージェントが協調してメモリを最適化し、動的な情報収集とフィルタリングを通じて、オープンドメインQAタスクにおける情報の有用性を高める点にあります。
論文:https://arxiv.org/abs/2504.05312
リポジトリ:https://anonymous.4open.science/r/Amber-B203/

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
本論文では、外部知識ベースからの非パラメトリックな知識をモデルに統合することによって、応答の正確性を向上させるとともに、事実誤認や幻覚を軽減する有望なアプローチである「Retrieval-Augmented Generation(RAG)」のための適応型メモリベースの最適化手法を提案します。この方法は、質問応答(QA)などのタスクに広く適用されています。
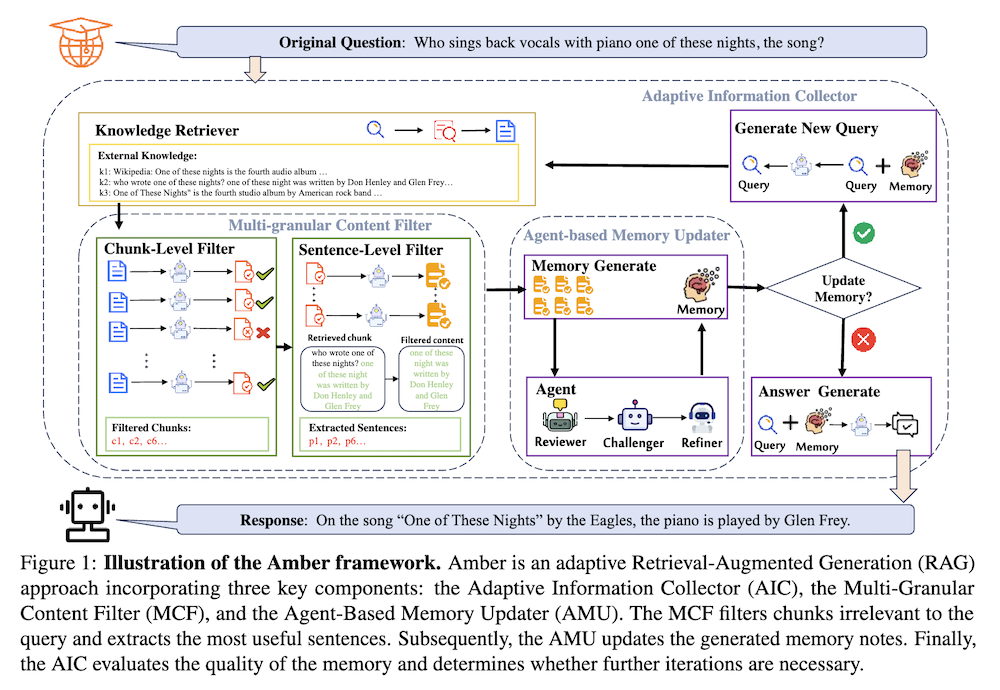
しかし、既存のRAG手法は、オープンドメインのQAタスクにおいては独立した検索操作を行い、取得した情報を生成に直接組み込むため、要約メモリを維持したり適応的な検索戦略を使用したりすることができず、冗長な情報からのノイズや不十分な情報統合を引き起こしています。これらの課題に対処するために、我々はオープンドメインQAタスクのための強化されたRAG(Amber)を提案します。Amberは、エージェントベースのメモリアップデータ、適応情報収集器、マルチグラニュラーコンテンツフィルターから構成され、反復メモリ更新のパラダイム内で協力して機能します。
具体的には、Amberはマルチエージェントの協調アプローチを通じて言語モデルのメモリを統合・最適化し、以前の検索ステップからの包括的な知識統合を確保します。さらに、蓄積された知識に基づいて検索クエリを動的に調整し、検索を停止するタイミングを決定することで、検索の効率性と有効性を向上させます。また、マルチレベルでのフィルタリングを行うことで関連性のないコンテンツを減らし、重要な情報を保持して全体的なモデルパフォーマンスを改善します。
論文の内容に基づいて、2章以降をより詳細にまとめます。各章は200文字程度に抑えて記載します。
1. はじめに
1.1 背景
Retrieval-Augmented Generation(RAG)は、外部知識ベースから非パラメトリックな知識を統合することによって、応答の精度を向上させる手法として注目されています。しかし、オープンドメインの質問応答(QA)タスクにおいては、情報の取得と生成のプロセスが独立しているため、ノイズの混入や情報の統合が不十分になるなどの課題があります。
1.2 提案手法
これらの課題を解決するために、本論文では「Adaptive memory-based optimization for enhanced RAG」(Amber)を提案します。Amberは、エージェントベースのメモリアップデーター(AMU)、適応情報コレクター(AIC)、多層コンテンツフィルター(MCF)の三つのコアコンポーネントで構成されています。
2. 関連研究
2.1 オープンドメインQA
オープンドメインQAは特定のドメインに制限されない質問に回答するタスクです。現代の手法はRetriever-and-Readerフレームワークを採用しています。近年ではマルチホップQAや長文QAが登場し、より複雑な質問に対応するため、複数の文書から情報を収集・統合する能力が必要とされています。KhotらやKhattabらは、複雑な質問を単純な部分問題に分解する手法を提案しています。
2.2 Retrieval-Augmented Generation
RAGは、LLMの応答品質を向上させるために不可欠となっています。初期のアプローチは単一の検索操作に依存していましたが、複雑なタスクでは不十分でした。そこでマルチタイム検索が探求されましたが、無関係なデータを取り込むリスクがありました。これを解決するため、適応型RAG(ARAG)が開発され、リアルタイムのフィードバックに基づいて検索戦略を動的に調整します。
3. 方法論
3.1 問題定式化
RAGは外部文書コーパスDからの関連情報を統合してLLMの生成品質を向上させることを目的としています。ユーザー入力xまたはクエリqに対して、検索器Rを使用してDから関連文書のサブセットを特定・選択します。LLMはこの情報を用いて改良された出力を生成します。
3.2 Amberの概要
Amberはクエリqに基づいて適応型メモリ更新反復RAG方法です。初期メモリM0を空集合として、AICが反復ループを開始します。各反復tでコーパスDからトップkのテキストチャンクCtを取得し、MCFがフィルタリングを行い、AMUが複数のエージェントを用いて新しい情報とメモリを統合します。AICは現在のメモリが十分かを評価し、必要に応じて新しいクエリを生成します。
3.3 エージェントベースのメモリアップデーター
AMUは複数エージェントを活用して効果的なメモリ更新を行う協調的アプローチを採用しています。レビュアー(評価者)、チャレンジャー(批判分析者)、リファイナー(改善実施者)の3つのエージェントが対話的に協力し、提案されたメモリ更新を評価・質問・改善します。これにより、情報統合の質が向上し、より正確で関連性の高いメモリが構築されます。
3.4 適応情報コレクター
AICはRAGワークフローの主要なスケジューラとして機能し、AMUによって生成されたメモリが質問に答えるのに十分かどうかを評価します。初期クエリと空のメモリから始まり、各反復で検索→メモリ更新→評価のステップを実行します。メモリが十分であれば終了し、不十分であれば新しいクエリを生成して次の反復へ進みます。このプロセスにより、包括的で質問に適合したメモリが構築されます。
3.5 多層コンテンツフィルター
MCFは、チャンクレベルと文レベルの2段階のフィルタリングを行います。チャンクレベルでは、検索されたチャンク全体がクエリに関連しているかを評価し、無関係なものを排除します。文レベルでは、関連性のあるチャンク内の各文を評価し、最も重要な文のみを抽出します。これにより、ノイズが大幅に削減され、モデルのパフォーマンスが向上します。
4. 実験設定
4.1 データセットと評価指標
実際的なシナリオをシミュレートするため、単一ホップQA(SQuAD、Natural Questions、TriviaQA)、マルチホップQA(2WikiMQA、HotpotQA)、長文QA(ASQA)データセットを統合的に使用しました。評価指標としては、正確さ(acc)、F1スコア(f1)、String Exact Match(str-em)、String Hit Rate(str-hit)を用いました。
4.2 ベースラインとLLM
実験では、情報検索なし(NoR)、単一時間RAG(STRAG)、適応型RAG(ARAG)の3種類のベースラインを比較しました。STRAGにはVanilla RAG、Chain-of-note、Self-Refine、Self-Rerankを、ARAGにはFLARE、Self-RAG、ReAct、Adaptive-RAG、Adaptive-Noteを含めました。LLMとしてはQwen2-7b、Llama3-8b、GPT-3.5を使用しました。
5. 結果と分析
5.1 主な結果
Amberはすべてのデータセットにおいて一貫して優れたパフォーマンスを示し、特にNatural Questions、2WikiMQA、HotpotQAではVanilla RAGを30%以上上回りました。単純なベースラインと比較して、Amberは検索された情報を適応的に探索し、不要なチャンクや文をフィルタリングする能力を持っているため、より効果的な知識保持が可能です。
5.2 分類器のパフォーマンス
Llama3-8bとQwen2-7bのどちらを使用した場合も、Amber分類器は有用な検索パッセージの分類で90%以上の精度を達成しました。さらに、40%以上の無関係な知識を除外することに成功し、知識の質を大幅に向上させました。
5.3 公平なtop-k比較
同じraw top-k設定下では、ARAG手法は一般に単一ステップ手法より多くのパッセージを検索します。公平な比較のため、サンプルごとの一意の検索パッセージの平均数を「fair top-k」として計算しました。この設定でもAmberの優位性が確認され、Vanilla手法は検索パッセージの数が増えても大きな改善を示しませんでした。
5.4 アブレーションスタディ
MCFの各コンポーネントとAMUの寄与を評価するため、2WikiMQAデータセットでアブレーション実験を実施しました。結果は、両フィルター戦略を組み合わせた場合に最高のパフォーマンスが得られ、チャンクレベルフィルターが文レベルフィルターよりも重要な役割を果たすことが示されました。また、AMUを除去するとパフォーマンスが大幅に低下し、エージェントがメモリ生成において重要な役割を果たすことが確認されました。
6. 結論
本研究では、メモリベースの適応的更新を特徴とする新しいRAG手法Amberを提案しました。協調的マルチエージェントメモリ更新メカニズム、適応的検索フィードバック反復、多層フィルタリング戦略を組み合わせることで、情報収集の効率化と適応的更新を実現し、回答の正確性を大幅に向上させました。複数のオープンドメインQAデータセットでの評価により、Amberの優位性と有効性が確認されました。今後の課題としては、より時間効率の良い一般化可能なファインチューニング戦略の設計が挙げられます。