目次
A Survey of Scaling in Large Language Model Reasoning
この論文は、大規模言語モデルの推論能力を向上させるためのスケーリング戦略について、さまざまな観点から包括的に調査したものです。
この論文は、大規模言語モデルの推論能力向上におけるスケーリング戦略を多角的に分析し、特に入力サイズや推論ステップのスケーリングが論理的整合性や多段階推論に与える影響を詳細に探求している点が特徴的です。
論文:https://arxiv.org/abs/2504.02181

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
大規模言語モデル(LLM)の急速な進展により、さまざまな戦略(例:マルチエージェントの協力)によってその推論能力が大幅に向上しています。しかし、データとモデルサイズのスケーリングによって達成されるパフォーマンスの向上が確立されているのに対し、LLMの推論のスケーリングはより複雑であり、推論パフォーマンスに悪影響を及ぼす可能性があり、モデルの整合性とロバスト性に新たな課題をもたらします。
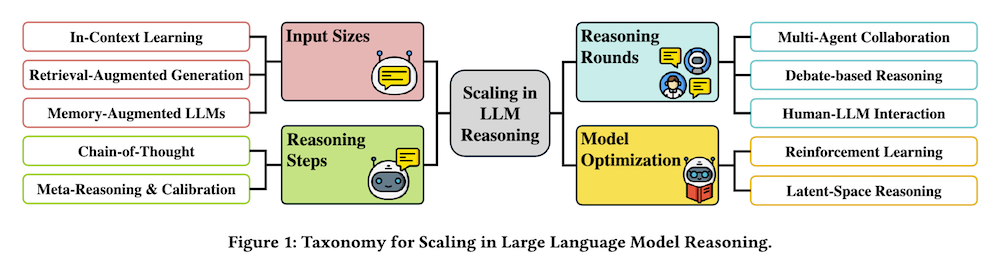
本調査では、LLMの推論におけるスケーリングを包括的に検討し、複数の次元に分類し、さまざまなスケーリング戦略が推論能力の向上にどのように、またどの程度寄与するかを分析します。まず、LLMがより広範な文脈を処理し利用することで推論を改善するための入力サイズのスケーリングを探ります。次に、多段階推論と論理的整合性を向上させる推論ステップのスケーリングを分析します。さらに、反復的な相互作用が推論結果を洗練する推論ラウンドのスケーリングを検討します。加えて、反復的なモデル改善を通じた最適化に焦点を当てたトレーニング可能な推論のスケーリングについて議論します。
最後に、さまざまなドメインにおけるスケーリングの応用をレビューし、LLMの推論をさらに進展させるための今後の方向性を示します。これらの多様な視点を統合することで、本調査はスケーリング戦略がどのように根本的にLLMの推論能力を向上させるかについての洞察を提供し、次世代AIシステムの開発をさらに導くことを目指しています。
1. 序論
大規模言語モデル(LLM)は自然言語処理タスクにおいて急速に進化し、顕著な進歩を遂げています。これらの進歩の主要な原動力はスケーリングであり、トレーニングデータとモデルパラメータのサイズを増加させることで性能が大幅に向上しています。しかし、単純なタスクと比較して、推論は構造化された思考、多段階の推論、論理的一貫性を必要とするため、推論のスケーリングはより複雑です。この調査では、LLM推論におけるスケーリングを複数の次元に分類し、異なるスケーリング戦略がどのように、どの程度まで推論能力の向上に貢献するかを分析します。
2. 入力サイズのスケーリング
LLMがスケールアップするにつれて、より大きな入力コンテキストを処理する能力が推論、検索、適応性の強化において重要になっています。しかし、長い入力はより高い計算コスト、メモリ制約、効率のボトルネックなどの課題をもたらします。この章では、入力サイズのスケーリングのための主要な戦略を検討します。
2.1 文脈内学習
文脈内学習(ICL)は、入力プロンプト内のデモンストレーションを条件として、パラメータ更新なしに新しいタスクに適応することをLLMに可能にします。ICLのパフォーマンスを向上させるためにさまざまなアルゴリズムが開発され、文脈スケーリングが観察されており、文脈内の例の数が増えるとモデルのパフォーマンスが向上します。最近の研究ではmany-shot ICLが調査されており、数百から数千のデモンストレーションを活用することでさまざまなタスクで大きなパフォーマンス向上が示されています。
2.2 検索拡張生成
検索拡張生成(RAG)は、幻覚や訓練データを超えた概念への限定された一般化などのLLMの制限に対処するために広く採用されている戦略です。外部情報を組み込むことで、RAGは事実の根拠付けを強化し、モデルのアクセス可能な知識ベースを拡大します。しかし、従来のRAGは短い検索単位で動作し、大規模な文書コーパスをスキャンして関連する段落を見つける必要があります。最近の長文脈LLMの進歩により、意味的不整合を減らしながら拡張コンテキストを処理することが可能になっています。
2.3 メモリ拡張LLM
LLMの推論能力のスケーリングは、既存のアーキテクチャがサポートする限られたトークンウィンドウを超えて効果的なコンテキストを拡張する必要があることが多くあります。コンテキスト長を増やすことでLLMはより長いシーケンスを処理できますが、そのようなスケーリングは注意メカニズムの二次的複雑性による計算のボトルネックと収益の逓減に直面します。これらの制限に対処するために、メモリ拡張戦略が登場し、LLMが持続的に関連するコンテキスト情報を保存、管理、動的に取得することを可能にしています。
3. 推論ステップのスケーリング
複雑な推論タスクは多段階の計算を必要とし、モデルは問題を分解し、解決策を反復的に改善し、正確さを検証する必要があります。推論の深さと幅をスケーリングすることで論理的一貫性と問題解決性能を強化できますが、過剰思考や計算コストの増加などのリスクも伴います。この章では、チェーン・オブ・ソート(CoT)プロンプティングなどの鍵となるアプローチとメタ推論技術を探ります。
3.1 チェーン・オブ・ソート
チェーン・オブ・ソート(CoT)プロンプティングは、ゼロショットまたは少数ショットデモンストレーションを通じて、詳細なステップバイステップの熟考を刺激することによってLLMの推論能力を強化する重要な技術として登場しました。LLMは確率的に動作するため、最適な答えを常に生成するとは限りません。これを軽減するために、自己一貫性やBest-of-Nなどの繰り返しサンプリングアプローチが使用され、複数の推論チェーンを並列に生成し、頻度、外部報酬モデル、または補助検証者に基づいて最良の答えを選択します。
3.2 メタ推論と調整
適切なプロンプトエンジニアリングにより、LLMには自己修正の継承能力があることが多くの研究で示されています。典型的に、LLMは自分の回答にフィードバックを生成することで自己反映できます。まず元の入力に対する初期応答を生成し、次に元の入力と初期応答に基づいてフィードバックを生成し、最後に入力、初期応答、フィードバックに基づいて洗練された応答を生成します。一般的に、自己修正は異なるフィードバックソース(固有のプロンプトと外部情報)に依存することがあります。
4. 推論ラウンドのスケーリング
単一ステップまたは連続的な推論を超えて、反復的な複数ラウンドの推論によりLLMは応答を洗練し、代替案を議論し、外部フィードバックを統合することができます。しかし、推論ラウンドの数をスケーリングすると、効率性、冗長性、パフォーマンス低下に関連する課題が生じます。この章では、反復的な相互作用を活用する主要なアプローチを探ります。
4.1 マルチエージェントコラボレーション
最近の研究者たちは、複数のLLMが協調的な方法で連携して改善された問題解決能力を達成するマルチエージェントコラボレーションの有効性を探求しています。これらのフレームワークでは、各LLM(エージェント)に異なる役割が割り当てられ、構造化された相互作用を通じて他のエージェントとの対話によって出力を反復的に洗練します。エージェントの数を増やすとタスクの多様性が向上し、役割の専門化が可能になりますが、一定数のエージェントを超えるとパフォーマンスは横ばいになるか、反する推論パス、冗長性、調整オーバーヘッドの増加により悪化する可能性があります。
4.2 議論ベースの推論
マルチLLMを協調的なタスク実行に活用する一般的なフレームワークを超えて、研究者たちはマルチラウンドの推論で推論の有効性を高めるためのLLMの使用も探求しています。具体的には、これらのフレームワークでは、各LLM(またはエージェント)は議論者として機能し、反復的な交換を通じて自らの推論を洗練しながら、他者に挑戦し、説得する談話に従事します。この領域での先駆的な研究であるMulti-Agent Debate (MAD)は、「目には目を」のメカニズムに従い、議論を監督して決定的な答えに到達する指定された審判と共に、複数のエージェントが構造化された議論に従事するフレームワークを導入しています。
4.3 人間とLLMの相互作用
LLM推論のスケーリングは、モデルサイズとコンテキストウィンドウだけでなく、人間との相互作用の質と深さにも依存しています。人間参加型フレームワークは、反復的な洗練、フィードバック駆動のプロンプティング、適応的な応答生成を統合することでLLMのパフォーマンスを向上させます。この相互作用パラダイムは、LLMを静的な推論エンジンからユーザーの介入から学習することができる動的に進化するエージェントに変換します。
5. モデル最適化のスケーリング
推論時の技術を超えて、モデル最適化のスケーリングは、強化学習と潜在空間処理を通じてLLM推論を強化することができます。RLベースの推論は人間の意図にモデルの動作を合わせ、多様なタスクにわたってモデルのパフォーマンスを向上させますが、収益の逓減に直面し、より良いポリシー最適化と適応的な報酬モデリングが必要です。一方、ループされたトランスフォーマーは表現を繰り返すことで効率的に推論の深さを改善し、より大きなモデルの必要性を減らすことができます。
5.1 強化学習
以前の研究では、監督付き微調整(SFT)データが大量に蓄積されているか慎重にキュレーションされているかにかかわらず、優れたLLMから知識を蒸留することで、より小さなモデルの複雑なタスク解決のための推論能力を強化できることが示されています。しかし、最近の研究では、SFTデータの量を単に増やすことは通常、log-線形のパフォーマンス改善をもたらすだけであると主張しています。さらに、SFTデータのみでトレーニングされたモデルは、訓練セットを暗記することで過学習し、分布外(OOD)タスクへの一般化に苦労する傾向があります。
5.2 潜在空間推論
明示的な推論では、モデルは最終出力を生成する前に中間ステップを生成します。このアプローチは複雑なタスクをより単純なステップに分解しますが、冗長で計算コストが高い場合があります。推論効率を向上させるために、モデルは明示的な言語化の必要性をスキップして、潜在空間で推論を実行することができます。例えば、Deng et al.は層間で多段階推論を潜在表現に蒸留することを提案し、モデルが単一の順方向パスで複雑な問題を解決できるようにし、それによって効率性とスケーラビリティを向上させています。
6. 応用
6.1 AI研究
LLMのスケーリングはAI研究を根本的に変革し、従来のドメインを拡張し、全く新しい研究分野を開拓しています。このセクションでは、スケーリングがLLM-as-a-Judge、ファクトチェック、対話システムの3つの重要な領域にどのように影響したかを探ります。より大きなモデルは人間の好みとの相関が大幅に高く、複数のジャッジモデル間でのスケーリングは評価の信頼性を向上させる効果的なアプローチとして浮上しています。
6.2 生産
LLMの推論能力のスケーリングは、特にソフトウェア開発、データサイエンスワークフロー、インタラクティブAIシステムにおいて、生産用途を大幅に強化しています。このサブセクションでは、これらの領域を例示的な例とともに議論します。拡張された推論能力により、対話エージェントは完全なコンテキスト認識のある長期的な相互作用を維持し、歴史的コンテキストと外部知識を効果的に統合することができます。
6.3 科学
LLMのスケーリングは科学分野に大きな恩恵をもたらし、医学、金融、災害管理が顕著な応用分野として浮上しています。医学分野では、モデルサイズを増やすことで医学的推論能力が向上し、医学的質問に対するパフォーマンスが比例して改善しています。このパターンは診断推論にも及び、より大きなモデルは小さなモデルが見逃す複雑な疾患進行パターンを識別することができます。
7. 将来の方向性
スケーラブルな推論における効率性:LLMの推論能力のスケーリングは複雑な問題を解決する能力を向上させますが、応答長も増加し、単純なタスクには非効率的になります。しかし、現在のLLMはすべてのクエリに均一な推論努力を適用し、不必要な計算オーバーヘッドを引き起こします。改善のための重要な方向性は、タスクの難易度に基づいて推論の深さを動的に調整する適応型推論フレームワークです。
逆スケーリングと安定性:逆スケーリングとは、LLMが特定のタスクで予想外に悪化する現象を指し、モデルサイズの増加によって一貫した改善を予測する標準的なスケーリング法則と矛盾します。これは、モデルが訓練分布のパターンによる偽りだが可能性の高い応答を生成する模倣的な虚偽などに起因します。
スケーリングされた推論モデルにおけるセキュリティリスク:CoTプロンプティングはLLMの構造化された推論を実行する能力を強化しますが、モデルの推論プロセスを操作するバックドア攻撃など、新たなセキュリティ脆弱性も導入します。BadChainは、クエリに隠されたトリガーが存在する場合、悪意のある変更を最終的な応答にもたらすバックドア推論ステップを注入することで、モデルのステップバイステップの推論を悪用します。
8. 結論
この調査では、大規模言語モデルにおけるスケーリング戦略が推論能力にどのように影響するかについて包括的な分析を提供しました。入力サイズ、推論ステップ、推論ラウンド、モデル最適化という4つの主要な次元を検討し、各次元における方法、利点、課題を強調しました。スケーリングは多くのドメインでLLM推論を改善しますが、計算上の非効率性、不安定性、新たなセキュリティリスクといった制限も導入します。適応的計算、堅牢な最適化、安全なマルチエージェント調整など、これらの問題に対処する新たな方向性を強調しました。LLMが進化し続けるにつれて、スケーラブルな推論の理解と改良が、より能力のある、信頼性の高い、効率的なAIシステムを構築する上で重要となります。