目次
Multi-Mission Tool Bench: Assessing the Robustness of LLM based Agents through Related and Dynamic Missions
この論文は、複数の関連ミッションを通じて大規模言語モデル(LLM)ベースのエージェントの堅牢性を評価するための「マルチミッションツールベンチ」を提案しています。
この論文の特徴は、複数の相互に関連するミッションを通じてエージェントの動的適応能力を評価する新たなマルチミッションツールベンチを提案し、実世界の複雑なシナリオにおける大規模言語モデル(LLM)の堅牢性を実証する点にあります。
論文:https://arxiv.org/abs/2504.02623
リポジトリ:https://github.com/yupeijei1997/MMTB

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
本論文では、ツール呼び出しのエージェントとしての大規模言語モデル(LLM)の堅牢性を評価するために、関連した動的ミッションを通じてのマルチミッションツールベンチを提案します。LLMは高度な理解力と計画能力を持ち、ユーザーは複雑なミッションを解決するためにLLMベースのエージェントに依存しています。しかし、既存のベンチマークは主に単一ミッションシナリオでエージェントを評価しており、実世界の複雑さを捉えきれていません。
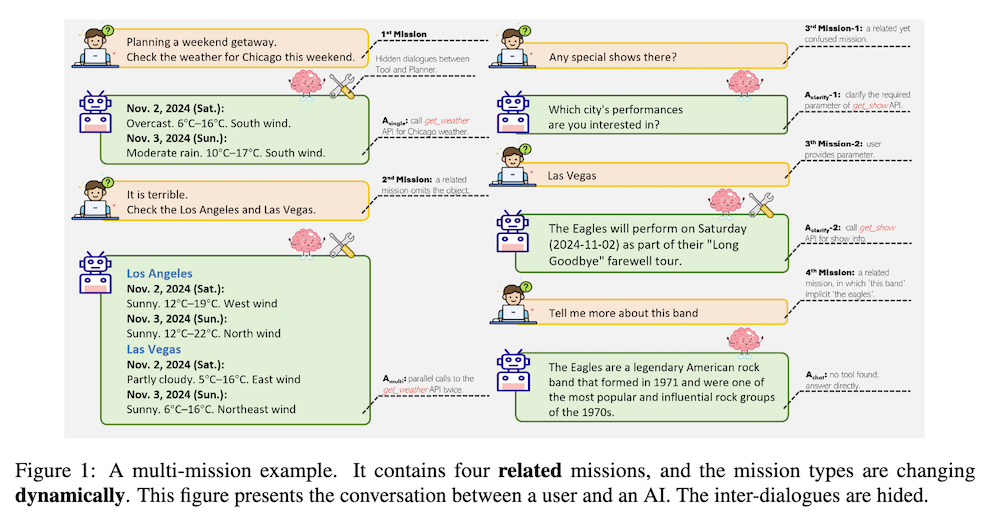
このギャップを埋めるために、マルチミッションツールベンチを提案し、各テストケースは相互に関連する複数のミッションで構成されるように設計されています。この設計により、エージェントは進化する要求に動的に適応する必要があります。さらに、提案されたベンチマークは、固定されたミッション数内でのすべてのミッション切り替えパターンを探ります。
具体的には、ベンチマークを構築するためのマルチエージェントデータ生成フレームワークを提案し、動的意思決定木を用いてエージェントの意思決定の正確性と効率性を評価する新しい方法を提案します。多様なオープンソースおよびクローズドソースのLLMに対する実験は、エージェントの堅牢性に影響を与える重要な要因を明らかにし、ツール呼び出しの分野に対して実行可能な洞察を提供します。
マルチミッションツールベンチによるLLMベースのエージェントの評価
1. はじめに
本論文では、従来のベンチマークが単一のミッションに依存している限界を克服するために、「マルチミッションツールベンチ」を提案しています。大規模言語モデル(LLM)は、ツール呼び出しエージェントとしての強力な潜在能力を持ち、ユーザーは複雑なミッションの解決にこれを活用しています。しかし、従来の評価方法では実世界の複雑性を反映できていません。この新しいベンチマークは、エージェントが動的に変化する要求に適応できるかを評価することを目的としています。
2. ベンチマークの設計
マルチミッションツールベンチでは、エージェントのアクション種別として、「単一ツールの使用」「複数ツールの使用」「ユーザーとのチャット」「パラメータ明確化後のツール使用」の4種類を定義しています。エージェントは単一ミッションでこれらのアクションを1つ実行し、連続したミッションでは複数のアクション種別を組み合わせます。このベンチマークの革新的な点は、ミッション切り替え空間を導入し、固定されたミッション数内ですべての可能なミッション種別の遷移パターンを網羅していることです。これにより、他のベンチマークと比較して、より広範なアクション多様性を実現しています。
3. データ生成フレームワーク
本研究では、5つの役割(ユーザー、プランナー、ツール、AI、チェッカー)を持つコントローラブルなデータ生成フレームワークを提案しています。このフレームワークでは、対話を通じてミッション実行プロセスをシミュレートします。プランナーがミッションを分析し、ツール呼び出しパスを計画し、アクション種別を決定する役割を担います。各生成プロセスでは、望ましいミッション種別とミッション関係を指定してフレームワークを誘導し、最終的にすべての可能な組み合わせを網羅するベンチマークを構築します。
4. 評価手法
提案された評価方法は、ツール間の依存関係による複数の実行順序の可能性に対応するため、動的評価フレームワークを導入しています。このフレームワークでは、依存関係分析、決定木構築、パス検証の3ステップを踏みます。まず、ツール依存関係を手動で識別し、深さ優先探索と位相ソートアルゴリズムを用いて可能な実行パスを生成します。エージェントのテスト中には、決定木に対して段階的なパスマッチングを行い、各アクションの正確性と最適性を評価します。
5. 実験結果
1,024のテストエントリからなるベンチマークに対して、24の最先端モデルを評価しました。結果から、特化型エージェントは単一ミッションで強力な一般モデルと同等のパフォーマンスを示すものの、マルチミッションシナリオでは急速に精度が低下することが判明しました。ミッション種類別の分析では、ほとんどのモデルがパラメータ不足の判断(Aclarityタイプ)に苦戦し、複数ツール呼び出し(Amulti)のうち、特に複雑なシリアル実行(AS multi)や組み合わせ実行(AS+P multi)が課題として浮かび上がりました。さらに、ミッション関係タイプの分析では、長期記憶が最も大きな影響を与えることが示されました。
6. 結論
本論文は、LLMベースのエージェントが実際の環境で直面する複雑なミッションに対してどのように評価できるかを示す新たなアプローチを提供しています。この研究は、ツール呼び出しエージェントの実用化に向けた重要な一歩であり、今後の研究においても大きな影響を与えることが期待されます。