目次
本日の論文
Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting
この論文は、小規模な特殊化されたLMを使って複数の回答案を並列生成し、大規模な汎用LMでそれらを検証することで、検索拡張生成(RAG)の精度と効率を向上させる新しい手法「Speculative RAG」を提案しています。
以下は、LLMを活用して論文の内容を要約したものになります。
概要
この論文は、検索拡張生成(RAG)の性能を向上させる新しいフレームワーク「SPECULATIVE RAG」を提案しています。小規模な専門家LMが並列に複数のドラフトを生成し、大規模な汎用LMがそれらを検証するという二段階のアプローチを採用しています。この方法により、検索された文書の多様な視点を効率的に処理し、入力トークン数を削減しつつ、長文脈での位置バイアスを軽減します。実験結果は、複数のベンチマークでの精度向上とレイテンシ削減を示しており、特にPubHealthでは精度が12.97%向上し、レイテンシが51%削減されました。
1. はじめに
大規模言語モデル(LLM)は質問応答タスクで顕著な成功を収めていますが、最新の情報や難解な事実を要する知識集約型の質問に直面すると、事実の不正確さや幻覚に苦戦します。検索拡張生成(RAG)は、外部データベースから検索した情報をコンテキストに組み込むことで、これらの問題を緩和する有望な解決策として登場しました。しかし、RAGシステムは複数の文書を検索するため、LLMへの入力が長くなり、処理に課題が生じます。本論文では、SPECULATIVE RAGを導入し、小さな専門家LMによる並列ドラフト生成と大きな汎用LMによる効率的な検証を組み合わせることで、RAGの性能と効率を向上させる新しいアプローチを提案しています。
2. 関連研究
この章では、SPECULATIVE RAGに関連する二つの主要な研究分野について概説しています。一つは検索拡張生成(RAG)であり、もう一つは投機的デコーディングです。これらの分野における最近の進展と、それらがSPECULATIVE RAGの開発にどのように影響を与えたかを説明しています。
2.1 検索拡張生成 (Retrieval Augmented Generation)
RAGは、LLMの生成能力を外部データベースからの情報検索と組み合わせて、より正確で最新の応答を生成する手法です。最近の研究は、LLMが何をいつ検索すべきかを理解できるようにすることや、コンテキストをより効果的に利用する方法の設計に焦点を当てています。SAILやSelf-Reflective RAGなどのアプローチが紹介されていますが、これらは追加の指示チューニングを必要とし、リソース集約的である可能性があります。
2.2 投機的デコーディング (Speculative Decoding)
投機的デコーディングは、自動回帰的デコーディングの遅延を減少させることを目的としたアプローチです。小さなモデルを使用して複数の将来のトークンをドラフトし、それらを目標モデルで並列に検証します。この概念は、トークンレベルのドラフティングから回答レベルのドラフティングへと拡張されており、SPECULATIVE RAGの基礎となっています。従来の検証基準とは異なり、SPECULATIVE RAGは言語モデリング目的を活用して回答ドラフト全体の信頼性を直接評価します。
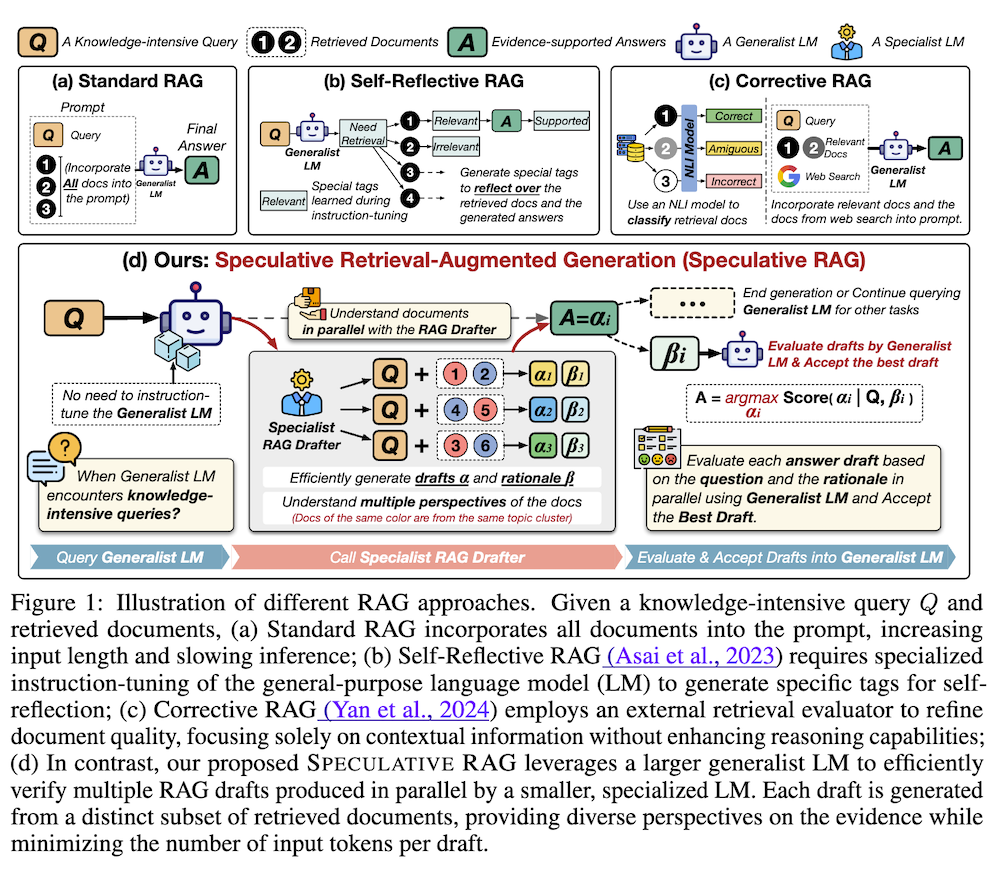
(a) 標準RAG: すべての検索文書をプロンプトに組み込みます。これにより入力が長くなり、推論が遅くなる問題があります。
(b) Self-Reflective RAG: 汎用言語モデル(LM)に特別な指示チューニングを行い、自己反省のための特殊タグを生成させます。これにより、モデルは必要に応じて文書を動的に検索し、検索文書の関連性を批評してから応答を生成します。
(c) Corrective RAG: 外部の検索評価器を使用して文書の品質を改善します。ただし、文脈情報のみに焦点を当てており、推論能力の向上は行いません。
(d) 提案手法:Speculative RAG: 小規模な専門家LMを使用して並列に複数のRAGドラフトを生成し、大規模な汎用LMでそれらを効率的に検証します。各ドラフトは検索文書の異なるサブセットから生成され、証拠に関する多様な視点を提供しながら、ドラフトごとの入力トークン数を削減します。
Speculative RAGは、RAGドラフターを使用して文書を並列に理解し、ドラフトを生成します。その後、汎用LMが質問と根拠に基づいて各ドラフトを評価し、最良のドラフトを受け入れます。このアプローチにより、効率的に多様な視点を処理しつつ、高品質な回答を生成することができます。
3. 投機的検索拡張生成 (Speculative Retrieval Augmented Generation)
この章では、SPECULATIVE RAGの詳細な構造と機能を説明しています。LLMの推論能力を向上させつつ処理速度を維持するために、分割統治アプローチを採用しています。小さな専門家LMであるRAGドラフターを使用して複数の回答案を迅速に生成し、大きな汎用LMであるRAG検証機がこれらのドラフトを評価、選択し、生成結果に統合します。
3.1 概要
SPECULATIVE RAGは、検索された文書を複数の視点でクラスタリングし、各クラスタから1つの文書をサンプリングしてサブセットを作成します。これらのサブセットを並列にRAGドラフターに分配し、回答案と根拠を生成します。生成された各ドラフトと根拠のペアに対して、RAG検証機が信頼度スコアを計算し、最終的な回答を選択します。この手法により、多様な視点を効率的に処理しつつ、冗長性を最小限に抑えることができます。
3.2 専門家RAGドラフター
RAGドラフターは、検索された文書を理解し、質問に基づいて回答案と根拠を生成するように指示チューニングされた小さな専門家LMです。この節では、RAGドラフターの訓練方法、多視点サンプリング戦略、およびドラフト生成プロセスについて詳しく説明しています。
3.2.1 指示チューニング
RAGドラフターの訓練データセットは、多様な指示-応答ペアから構成されています。これらのペアは検索された文書と生成された根拠で拡張されます。訓練目的は、クエリと文書に基づいて応答と根拠を生成する確率を最大化することです。この指示チューニングにより、RAGドラフターは文脈を理解し、適切な回答を生成する能力を獲得します。
3.2.2 多視点サンプリング
検索された文書の冗長性を最小限に抑え、多様性を高めるために、文書をクラスタリングし、各クラスタから1つの文書をサンプリングしてサブセットを作成します。この方法により、各サブセットが検索結果の多様な視点を含むようになります。クラスタリングには指示認識型埋め込みモデルとK-means法を使用しています。
3.2.3 RAGドラフティング
RAGドラフターは、サンプリングされた文書サブセットごとに回答案と根拠を生成します。生成された回答案と根拠は、後続のRAG検証機による評価に使用されます。この並列処理により、効率的に多様な視点を考慮した回答案を生成することができます。
3.3 汎用RAG検証機
RAG検証機は、事前訓練された汎用LMを使用して、RAGドラフターが生成した回答案と根拠を評価します。検証プロセスでは、自己一貫性スコアと自己反省スコアを計算し、最も信頼できる回答案を選択します。この手法により、生の検索結果を処理する必要がなくなり、効率的に高品質な回答を生成することができます。
4. 実験
この章では、SPECULATIVE RAGの性能評価について詳細に説明しています。TriviaQA、MuSiQue、PubHealth、ARC-Challengeの4つの公開ベンチマークデータセットを用いて実験を行っています。実験では、標準RAG、Self-Reflective RAG、Corrective RAGなどのベースラインと比較し、SPECULATIVE RAGの精度とレイテンシを評価しています。また、アブレーション研究や様々な設定での分析も行っています。
4.1 ベースライン
標準RAG、Self-Reflective RAG、Corrective RAGなど、比較対象となる既存のRAGシステムについて説明しています。これらのベースラインには、Mistral、Mixtral、Alpacaなどの異なるLLMを使用しており、公平な比較のために同じバックボーンLLMを採用しています。
4.2 実験設定
SPECULATIVE RAGの実装詳細と実験設定について説明しています。RAGドラフターにはMistral 7Bを、RAG検証機にはMistral 7BまたはMixtral 8x7Bを使用しています。文書のエンベッディングには軽量な指示認識型モデルを使用し、推論にはvLLMフレームワークを採用しています。各データセットに対する具体的な設定も記述されています。
4.3 主な結果
SPECULATIVE RAGが全てのベンチマークで一貫してベースラインを上回る性能を示したことを報告しています。特に、PubHealthデータセットでは最大12.97%の精度向上を達成しています。また、RAGドラフターの指示チューニングの効果や、RAG検証機の信頼性の高いドラフト検証能力についても言及しています。
4.4 レイテンシ分析
SPECULATIVE RAGと標準RAGのレイテンシを比較分析しています。SPECULATIVE RAGが並列処理と小規模なRAGドラフターの使用により、一貫して最低のレイテンシを達成したことを示しています。特にPubHealthデータセットでは、最大51.25%のレイテンシ削減を実現しています。
4.5 アブレーション研究
SPECULATIVE RAGの主要コンポーネントに関するアブレーション研究の結果を報告しています。多視点サンプリングの効果や、各信頼度スコア(ドラフトスコア、自己一貫性スコア、自己反省スコア)の重要性を検証しています。結果は、提案手法の各要素が性能向上に寄与していることを示しています。
5. 結論
この章では、SPECULATIVE RAGの主要な貢献と成果を要約しています。提案されたフレームワークは、RAGタスクをドラフティングと検証の2つのステップに分解し、小さな専門化されたRAGドラフターに重要な作業を委託し、大きな汎用LMで検証を行うことで、RAGの性能と効率を向上させています。多様な文書サブセットから並列に複数のドラフトを生成することで、入力トークン数を削減し、長文脈での位置バイアスのリスクを軽減しながら、高品質な回答候補を提供しています。実験結果は、従来のRAGシステムと比較して最大12.97%の精度向上とレイテンシの51%削減を示しており、SPECULATIVE RAGの有効性を実証しています。この研究は、タスク分解を通じてRAGの性能を向上させる協調的アーキテクチャの可能性に新たな光を当てています。
付録
A. 根拠生成のプロンプト
根拠生成に使用されるプロンプトの具体例を示しています。Gemini-Ultraモデルを使用して、与えられた証拠に基づいて適切な根拠を生成する方法を説明しています。プロンプトには、証拠の内容、指示、期待される応答が含まれており、モデルがどのように根拠を生成すべきかを示しています。
B. RAGドラフティングのプロンプト
RAGドラフターが使用するプロンプトの例を提供しています。このプロンプトは、指示と証拠を含み、モデルに応答と根拠の両方を生成するよう指示しています。具体的な質問と関連する証拠文書の例が含まれており、RAGドラフターがどのように情報を処理し、回答を生成するかを示しています。
C. 標準RAGのプロンプト
標準RAGシステムで使用されるプロンプトの例を2つ提示しています。1つは非指示チューニングLM用、もう1つは指示チューニングLM用です。これらのプロンプトは、質問、検索された証拠文書、そして期待される応答形式を含んでおり、標準RAGシステムがどのように情報を処理するかを示しています。
D. ケーススタディ
SPECULATIVE RAGの動作を具体的に示すケーススタディを提供しています。同じ質問に対して生成された2つのドラフトの例を示し、RAGドラフターが検索結果の多様な視点をどのように理解し、高品質なドラフトを生成するかを説明しています。また、RAG検証機がどのように信頼できないドラフトをフィルタリングするかも示しています。
E. 指示チューニング設定
RAGドラフターの訓練に使用されたデータセットの構築方法や、訓練の具体的な設定について詳細に説明しています。使用されたハードウェア、ソフトウェアライブラリ、およびトレーニングプロセスの詳細が含まれています。
F. 自己反省文の効果
自己反省文が検証プロセスにどのように影響するかを分析しています。異なる自己反省文を使用した場合の性能比較を提供し、汎用LMの言語モデリング目的による検証能力の安定性を示しています。