目次
本日の論文
A Survey on Large Language Model based Autonomous Agents
この論文は、大規模言語モデル(LLM)を活用した自律エージェントの構築、応用、評価に関する包括的な調査を行い、この新興分野の現状と課題を体系的にまとめたものです。
以下は、LLMを活用して論文の内容を要約したものになります。
概要
この論文は、大規模言語モデル(LLM)を基盤とした自律エージェントに関する包括的な調査を提示しています。従来の限定的な環境での訓練とは異なり、LLMベースのエージェントは人間レベルの知能の可能性を示しています。
論文では、エージェントの構築、社会科学・自然科学・工学分野での応用、および評価戦略について体系的にレビューしています。また、統一的なフレームワークを提案し、この新興分野の現状を整理するとともに、将来の課題と方向性を提示しています。
1. LLMベース自律エージェントの構築
LLMベース自律エージェントの構築には、エージェントアーキテクチャの設計と特定のタスクを完遂するためのエージェント能力の獲得という2つの重要な側面があります。
アーキテクチャ設計では、LLMをより効果的に活用するための構造を考案し、能力獲得では、設計されたアーキテクチャにタスク特有の能力、スキル、経験を付与する戦略を開発します。
1.1 エージェントアーキテクチャ設計
エージェントアーキテクチャは、プロファイリングモジュール、メモリモジュール、プランニングモジュール、アクションモジュールから構成されます。
プロファイリングモジュールはエージェントの役割を定義し、メモリとプランニングモジュールはエージェントを動的な環境に置き、過去の行動を思い出し、将来の行動を計画することを可能にします。
アクションモジュールはエージェントの決定を具体的な出力に変換します。これらのモジュールは相互に影響を与え合い、エージェントの全体的な機能を形成します。
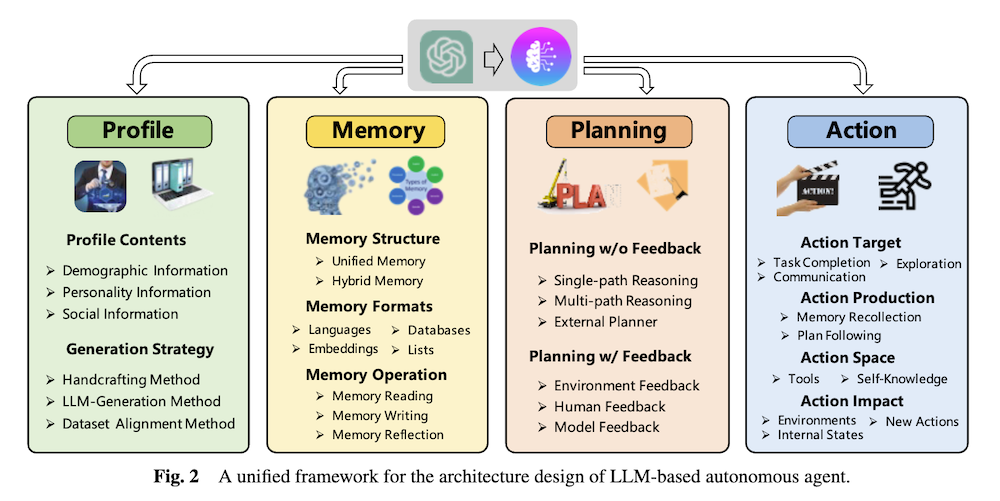
図2は、LLMベース自律エージェントのアーキテクチャ設計のための統一フレームワークを示しています。このフレームワークは、Profile、Memory、Planning、Actionという4つの主要モジュールで構成されています。各モジュールの簡潔な説明は以下の通りです:
- Profile(プロフィール)モジュール: エージェントの役割を定義します。人口統計情報、性格情報、社会的情報などを含み、手作業、LLM生成、データセット整合の方法で生成されます。
- Memory(メモリ)モジュール: エージェントの経験や知識を保存し、活用するためのモジュールです。統一メモリや混合メモリなどの構造があり、読み取り、書き込み、反省などの操作を行います。
- Planning(計画)モジュール: エージェントの行動計画を立てるためのモジュールです。フィードバックの有無によって異なる方法があり、単一パス推論、マルチパス推論、外部プランナーなどの戦略が含まれます。
- Action(アクション)モジュール: エージェントの決定を具体的な結果に変換するモジュールです。タスク完了、コミュニケーション、環境探索などの目標があり、メモリの再収集やプラン追従などの方法で生成されます。
1.1.1 プロファイリングモジュール
プロファイリングモジュールは、エージェントの役割を特定することを目的としています。エージェントのプロファイルは通常、基本情報、心理情報、社会情報を含み、これらはプロンプトに書き込まれてLLMの動作に影響を与えます。
Handcrafting Method:
この方法では、エージェントのプロファイルを手動で指定します。例えば、異なる性格を持つエージェントを設計する場合、「あなたは外向的な人物です」や「あなたは内向的な人物です」などのプロンプトを使用します。この方法は柔軟性が高いですが、多数のエージェントを扱う場合には労力がかかる可能性があります。
LLM-generation Method:
この方法では、エージェントのプロファイルをLLMを用いて自動生成します。通常、プロファイル生成のルールを指定し、必要に応じて少数のシードプロファイルを提供した後、LLMを使用して全てのエージェントプロファイルを生成します。この方法は、多数のエージェントを扱う場合に時間を節約できますが、生成されるプロファイルの正確な制御が難しい場合があります。
Dataset Alignment Method:
この方法では、実世界のデータセットからエージェントのプロファイルを取得します。典型的には、データセット内の実際の人間に関する情報を自然言語プロンプトに組織化し、それを用いてエージェントをプロファイリングします。この方法は実際の人口の属性を正確に捉えることができ、エージェントの行動をより意味のある、現実世界を反映したものにすることができます。
1.1.2 メモリモジュール
メモリモジュールは、環境から知覚した情報を保存し、記録された記憶を利用して将来の行動を促進します。このモジュールはエージェントが経験を蓄積し、自己進化し、より一貫性があり、合理的で効果的な方法で行動することを助けます。
Memory Structures:
LLMベース自律エージェントは通常、人間の記憶過程に関する認知科学研究から導き出された原理とメカニズムを組み込んでいます。
Unified Memory:
この構造は人間の短期記憶のみをシミュレートし、通常はin-context learningによって実現されます。記憶情報は直接プロンプトに書き込まれます。
Hybrid Memory:
この構造は人間の短期記憶と長期記憶を明示的にモデル化します。短期記憑は最近の知覚を一時的にバッファリングし、長期記憶は時間をかけて重要な情報を統合します。
Memory Formats:
メモリの保存媒体のフォーマットには、自然言語メモリ、埋め込みメモリなどがあります。
Memory Operations:
メモリ操作には、メモリの読み取り、書き込み、反射の3つの重要な操作があります。これらの操作により、エージェントは環境と相互作用し、重要な知識を獲得、蓄積、利用することができます。
1.2 エージェント能力獲得
エージェント能力獲得は、LLMのファインチューニングを行うか否かによって大きく二つの戦略に分類されます。
1.2.1 ファインチューニングを伴う能力獲得
この方法では、タスク依存のデータセットに基づいてエージェントをファインチューニングします。データセットは人間による注釈、LLMによる生成、または実世界のアプリケーションからの収集によって構築されます。
1.2.2 ファインチューニングを伴わない能力獲得
この方法では、プロンプトエンジニアリングやメカニズムエンジニアリングといった技術を用いて、既存のLLMの能力を引き出したり、エージェントの進化メカニズムを設計したりします。
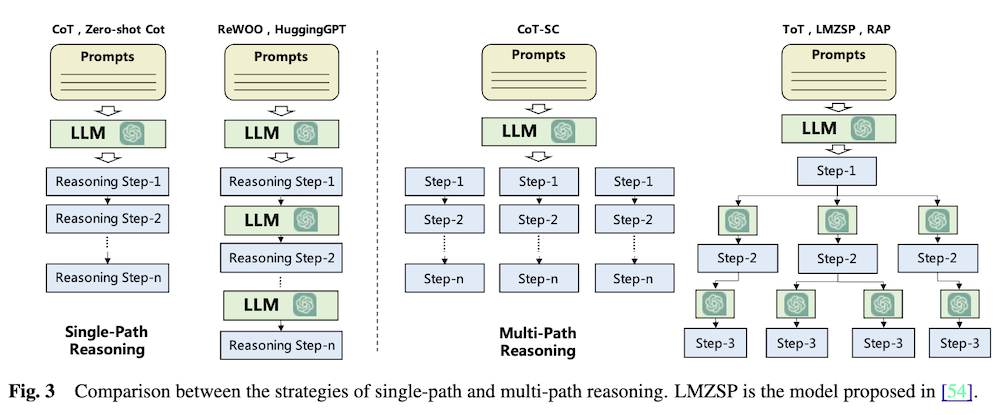
図3は、単一パス推論と多重パス推論の戦略を比較して示しています。
- 単一パス推論(Single-Path Reasoning):
- CoT(Chain of Thought)とZero-shot CoT: LLMは一度の呼び出しで全ての推論ステップを生成します。
- ReWOO, HuggingGPT: 複数回LLMを呼び出し、各ステップで推論を行います。
- 多重パス推論(Multi-Path Reasoning):
- CoT-SC(Self-consistent CoT): 複数の推論パスを生成し、最も頻度の高い答えを選択します。
- ToT(Tree of Thoughts), LMZSP, RAP: 各ステップで複数の可能性を生成し、ツリー構造で探索します。
2. LLMベース自律エージェントの応用
LLMベース自律エージェントは、その強力な言語理解能力、複雑なタスク推論能力、常識理解能力により、社会科学、自然科学、工学など多岐にわたる分野で応用されています。
2.1 社会科学における応用
社会科学分野では、LLMベースエージェントは心理学実験のシミュレーション、政治科学や経済学の研究、社会現象のシミュレーション、法律分野での意思決定支援、研究補助などに活用されています。これらの応用により、人間の行動や社会システムの理解が深まり、新たな知見が得られています。
2.2 自然科学における応用
自然科学分野では、文献管理やデータ管理、実験補助、自然科学教育などにLLMベースエージェントが応用されています。これらのエージェントは、大量の科学文献の処理、実験計画の立案と実行、学生への教育支援などを効率的に行うことができ、科学研究の進展に貢献しています。
2.3 工学における応用
工学分野では、LLMベースエージェントはコンピュータサイエンスやソフトウェア工学、産業オートメーション、ロボティクスなど、幅広い領域で応用されています。これらのエージェントは、コード生成、ソフトウェア開発プロセスの自動化、産業システムの最適化、ロボットの制御など、様々なタスクを効率的に遂行し、工学的問題解決を支援しています。
3. LLMベース自律エージェントの応用
LLMベース自律エージェントは、その強力な言語理解能力、複雑なタスク推論能力、常識的理解能力により、多くの分野に影響を与える可能性を示している。この章では、社会科学、自然科学、工学の3つの異なる分野におけるLLMベース自律エージェントの応用について簡潔にまとめる。
3.1 社会科学
社会科学は、社会とその中の個人間の関係を研究する科学の一分野である。LLMベース自律エージェントは、その印象的な人間のような理解力、思考力、タスク解決能力を活用して、この分野を促進することができる。
3.1.1 心理学
心理学の分野では、LLMベースのエージェントはシミュレーション実験の実施、メンタルヘルスサポートの提供などに活用できる。例えば、LLMに異なるプロフィールを割り当て、心理学実験を完了させることで、人間の参加者を伴う研究と一致する結果を生成できることが示されている。また、LLMベースの会話エージェントが、ユーザーの不安、社会的孤立、うつ病への対処を支援できることも見出されている。
3.1.2 政治学と経済学
LLMベースのエージェントは、イデオロギーの検出や投票パターンの予測、政治演説の談話構造や説得要素の理解、人間の経済行動の探索などに活用されている。
3.1.3 社会シミュレーション
LLMベースのエージェントを用いて仮想環境を構築し、有害情報の伝播などの社会現象をシミュレートする研究が行われている。例えば、オンラインソーシャルコミュニティのシミュレーション、ソーシャルネットワークでのエージェントの行動特性の影響調査、仮想の町での人間の日常生活のシミュレーションなどが行われている。
3.1.4 法学
LLMベースのエージェントは、法的意思決定プロセスを支援し、より情報に基づいた判断を促進するのに役立つ。複数の言語モデルを使用して複数の裁判官の意思決定プロセスをシミュレートし、多様な意見を収集して投票メカニズムを通じて結果を統合するシステムや、データベースとキーワード検索戦略の両方をサポートする中国の法律モデルなどが開発されている。
3.1.5 研究助手
LLMベースのエージェントは、社会科学研究の幅広い分野で多様な支援を提供している。例えば、簡潔な論文要約の生成、重要なキーワードの抽出、詳細な研究スクリプトの作成、新しい研究課題の特定などを行い、研究プロセスを豊かにし、効率化している。
3.2 自然科学
自然科学は、観察と実験による経験的証拠に基づいて自然現象の記述、理解、予測を行う科学の一分野である。LLMの発展に伴い、自然科学におけるLLMベースのエージェントの応用がますます普及している。
3.2.1 文書管理とデータ管理
自然科学研究では、大量の文献の収集、整理、統合が必要であり、これには多大な時間と人的資源が必要である。LLMベースのエージェントは、言語理解や、インターネットやデータベースなどのツールを使用したテキスト処理において強力な能力を示している。これらの能力により、エージェントは文書管理とデータ管理に関連するタスクで優れた性能を発揮する。
3.2.2 実験助手
LLMベースのエージェントは、独立して実験を行う能力を持ち、科学者の研究プロジェクトを支援する貴重なツールとなっている。例えば、実験目的を入力として受け取り、インターネットにアクセスして関連文書を取得し、必要な情報を収集し、Pythonコードを使用して必要な計算を行い、後続の実験を実行するシステムが開発されている。
3.2.3 自然科学教育
LLMベースのエージェントは人間と流暢にコミュニケーションを取ることができるため、エージェントベースの教育ツールの開発にしばしば活用されている。例えば、学生の実験設計、方法論、分析の学習を促進するエージェントベースの教育システムが開発されている。これらのシステムの目的は、学生の批判的思考と問題解決能力を向上させると同時に、科学的原理のより深い理解を促進することである。
3.3 工学
LLMベース自律エージェントは、工学研究や応用を支援し強化する大きな可能性を示している。この節では、LLMベースエージェントのいくつかの主要な工学分野での応用について概説する。
3.3.1 土木工学
土木工学では、LLMベースのエージェントを使用して、建物、橋、ダム、道路などの複雑な構造物の設計と最適化を行うことができる。例えば、人間の建築家とエージェントが協力して3Dシミュレーション環境で構造物を構築するインタラクティブなフレームワークが提案されている。
3.3.2 コンピュータサイエンスとソフトウェア工学
コンピュータサイエンスとソフトウェア工学の分野では、LLMベースのエージェントはコーディング、テスト、デバッグ、ドキュメント生成の自動化に可能性を提供している。例えば、複数のエージェントの役割が自然言語の会話を通じてコミュニケーションと協力を行い、ソフトウェア開発ライフサイクルを完了するエンドツーエンドのフレームワークが提案されている。
3.3.3 産業オートメーション
産業オートメーションの分野では、LLMベースのエージェントを使用して生産プロセスのインテリジェントな計画と制御を実現することができる。例えば、大規模言語モデルをデジタルツインシステムと統合して柔軟な生産ニーズに対応する新しいフレームワークが提案されている。
3.3.4 ロボティクスと身体化人工知能
最近の研究では、ロボティクスと身体化人工知能のためのより効率的な強化学習エージェントが開発されている。焦点は、具現化された環境での計画、推論、協力のための自律エージェントの能力向上にある。例えば、高レベルコマンドを使用して改善された計画を可能にし、低レベルコントローラーを提案してコマンドをアクションに変換する統一されたエージェントシステムが提案されている。
4. LLMベース自律エージェントの評価
LLM自体と同様に、LLMベース自律エージェントの有効性を評価することは困難な課題である。この章では、評価の2つの一般的なアプローチである主観的評価と客観的評価の概要を説明する。
4.1 主観的評価
主観的評価は、人間の判断に基づいてエージェントの能力を測定する。これは、評価データセットがない場合や、定量的な指標を設計することが非常に困難な場合、例えばエージェントの知性やユーザーフレンドリー性を評価する場合に適している。
4.1.1 人間による注釈
この評価方法では、人間の評価者が様々なエージェントによって生成された出力を直接スコア付けまたはランク付けする。例えば、多くの注釈者を雇用し、エージェントの能力に直接関連する5つの主要な質問についてフィードバックを提供するよう依頼する方法がある。
4.1.2 チューリングテスト
この評価戦略では、人間の評価者がエージェントによって生成された出力と人間によって作成された出力を区別する必要がある。与えられたタスクで評価者がエージェントと人間の結果を区別できない場合、エージェントがそのタスクで人間のようなパフォーマンスを達成できることを示している。
4.2 客観的評価
客観的評価とは、計算、比較、時間の経過とともに追跡できる定量的な指標を使用してLLMベース自律エージェントの能力を評価することを指す。主観的評価とは対照的に、客観的な指標は、エージェントのパフォーマンスに関する具体的で測定可能な洞察を提供することを目的としている。客観的評価を実施するには、評価指標、プロトコル、ベンチマークの3つの重要な側面がある。
4.2.1 指標
エージェントの有効性を客観的に評価するために、適切な指標を設計することが重要である。理想的な評価指標は、エージェントの品質を正確に反映し、実世界のシナリオでエージェントを使用する際の人間の感覚と一致する必要がある。既存の研究から、以下の代表的な評価指標を結論付けることができる:(1)タスク成功指標、(2)人間類似性指標、(3)効率性指標。
4.2.2 プロトコル
評価指標に加えて、客観的評価のもう一つの重要な側面は、これらの指標をどのように活用するかである。先行研究では、以下のような一般的に使用される評価プロトコルを特定できる:(1)実世界シミュレーション、(2)社会的評価、(3)マルチタスク評価、(4)ソフトウェアテスト。
4.2.3 ベンチマーク
指標とプロトコルが与えられた場合、評価を実施するための適切なベンチマークを選択することが重要な残りの側面である。過去には、人々は実験で様々なベンチマークを使用してきた。例えば、多くの研究者がALFWorld、IGLU、Minecraftなどのシミュレーション環境をベンチマークとして使用して、エージェントの能力を評価している。
5. 関連調査
大規模言語モデルの活発な発展に伴い、様々な側面に詳細な洞察を提供する包括的な調査が多数登場している。これらの調査は、LLMの背景、主な発見、主流の技術から、ダウンストリームタスクへの応用や展開に関連する課題まで、幅広いトピックをカバーしている。人間の知能とLLMの整合性、推論能力の向上、ツールの利用能力の拡張、評価手法など、LLMに関する様々な側面が調査されている。
しかし、本論文以前には、急速に発展し非常に有望な分野であるLLMベースのエージェントに特化した研究はなかった。本研究では、LLMベースのエージェントに関連する100の研究をまとめ、その構築、応用、評価プロセスをカバーしている。
6. 課題
LLMベース自律エージェントに関する先行研究は多くの顕著な成功を収めているが、この分野はまだ初期段階にあり、その発展には対処すべき重要な課題がいくつか存在する。
6.1 役割演技能力
従来のLLMとは異なり、自律エージェントは通常、異なるタスクを達成するために特定の役割(プログラムコーダー、研究者、化学者など)を演じる必要がある。そのため、エージェントの役割演技能力は非常に重要である。LLMは映画評論家のような一般的な役割を効果的にシミュレートできるが、正確に捉えるのが難しい役割や側面がまだ多く存在する。
まず、LLMは通常ウェブコーパスに基づいて訓練されているため、ウェブ上でほとんど議論されていない役割や新しく出現した役割については、LLMがうまくシミュレートできない可能性がある。さらに、先行研究では、既存のLLMが人間の認知心理学的特徴をうまくモデル化できず、会話シナリオにおける自己認識の欠如につながる可能性があることが示されている。
6.2 一般化された人間との整合性
人間との整合性は、従来のLLMに関して多く議論されてきた。LLMベース自律エージェントの分野、特にエージェントがシミュレーションに使用される場合、このコンセプトをより深く議論する必要がある。
人間により良くサービスを提供するために、従来のLLMは通常、正しい人間の価値観に沿うように微調整されている。しかし、エージェントが現実世界のシミュレーションに使用される場合、理想的なシミュレーターは、正しくない価値観を持つものも含め、多様な人間の特性を正直に描写できる必要がある。
実際、人間の否定的な側面をシミュレートすることはより重要かもしれない。なぜなら、シミュレーションの重要な目的の一つは問題を発見し解決することであり、否定的な側面がなければ解決すべき問題がないことを意味するからである。
6.3 プロンプトの堅牢性
エージェントの合理的な行動を確保するために、設計者がLLMにメモリや計画モジュールなどの補助モジュールを組み込むのは一般的な実践である。しかし、これらのモジュールを含めるには、一貫した操作と効果的なコミュニケーションを促進するために、より複雑なプロンプトを開発する必要がある。
先行研究では、LLMのプロンプトの堅牢性の欠如が指摘されており、わずかな変更でも大きく異なる結果が生じる可能性がある。この問題は、自律エージェントを構築する際により顕著になる。なぜなら、単一のプロンプトではなく、すべてのモジュールを考慮したプロンプトフレームワークが必要であり、一つのモジュールのプロンプトが他のモジュールに影響を与える可能性があるからである。
さらに、プロンプトフレームワークはLLM間で大きく異なる可能性がある。多様なLLMに適用可能な統一された堅牢なプロンプトフレームワークの開発は、重要かつ未解決の課題である。
6.4 幻覚
幻覚はLLMの基本的な課題であり、モデルが高い信頼度で虚偽の情報を生成する傾向として特徴付けられる。この課題はLLMだけでなく、自律エージェントの領域でも重要な懸念事項である。例えば、コード生成タスク中に単純な指示に直面した場合、エージェントが幻覚的な行動を示す可能性があることが観察されている。幻覚は、不正確または誤解を招くコード、セキュリティリスク、倫理的問題などの深刻な結果につながる可能性がある。
6.5 知識境界
LLMベース自律エージェントの重要な応用の一つは、多様な実世界の人間の行動をシミュレートすることである。人間のシミュレーションの研究には長い歴史があるが、最近の関心の高まりは、LLMが人間の行動をシミュレートする上で顕著な能力を示したことによるものである。
しかし、LLMの力が必ずしも有利とは限らないことを認識することが重要である。具体的には、理想的なシミュレーションは人間の知識を正確に複製する必要がある。この文脈では、LLMは平均的な個人が知っている以上の膨大なウェブ知識コーパスで訓練されているため、圧倒的な能力を示す可能性がある。LLMの膨大な能力はシミュレーションの有効性に大きな影響を与える可能性がある。
6.6 効率性
自己回帰アーキテクチャのため、LLMは通常推論速度が遅い。しかし、エージェントはメモリからの情報抽出、アクション前の計画立案など、各アクションに対して複数回LLMに問い合わせる必要がある可能性がある。その結果、エージェントのアクションの効率はLLMの推論速度に大きく影響される。
7. 結論
本調査では、LLMベース自律エージェントの分野における既存研究を体系的にまとめている。これらの研究を、エージェントの構築、応用、評価という3つの側面から提示し、レビューを行っている。
各側面について、既存研究間のつながりを描き出すための詳細な分類を提供し、主要な技術とその発展の歴史を要約している。先行研究のレビューに加えて、この分野における複数の課題を提起しており、これらは将来の潜在的な研究方向を導くことが期待される。