目次
本日の論文
REPLUG: Retrieval-Augmented Black-Box Language Models
この論文は、既存の大規模言語モデル(LLM)をブラックボックスとして扱い、外部知識を検索・活用する機能を追加することで、モデルの性能を向上させる新しい手法「REPLUG」を提案しています。
以下は、LLMを活用して論文の内容を要約したものになります。
概要
REPLUGは、言語モデルをブラックボックスとして扱い、調整可能な検索モデルで拡張する新しいフレームワークです。
検索した文書を単純に入力の前に付加するだけの設計により、既存のモデルに容易に適用できます。言語モデルを使用して検索モデルを監督し、より良い予測に役立つ文書を見つけることができます。
実験では、GPT-3の言語モデリング性能を6.3%、Codexの5ショットMMLU性能を5.1%向上させました。この手法は、大規模言語モデルの性能を外部知識の活用により効果的に改善します。
イントロダクション
我々はREPLUGを紹介します。これは検索拡張型言語モデリングフレームワークで、言語モデル(LM)をブラックボックスとして扱い、調整可能な検索モデルで拡張します。従来の検索拡張型LMとは異なり、REPLUGは単に検索した文書を凍結されたブラックボックスLMへの入力の前に付加するだけです。この単純な設計により、既存の検索モデルと言語モデルに容易に適用できます。さらに、LMを使用して検索モデルを監督し、LMの予測性能を向上させる文書を見つけることができます。
背景と関連研究
ブラックボックス言語モデル
GPT-3やCodexなどの大規模言語モデルは、商業的な理由からAPIとしてのみ利用可能であり、内部表現にアクセスしたりファインチューニングしたりすることができません。一方、OPT-175BやBLOOM-176Bのようなオープンソースモデルも、実行やファインチューニングに膨大な計算リソースを必要とします。従来の検索拡張型モデルフレームワークは、言語モデルの内部表現にアクセスする必要があるため、これらの大規模モデルには適用が困難でした。
検索拡張型モデル
様々なNLPタスクにおいて、外部知識ストアから関連情報を検索して言語モデルを拡張することが効果的であることが示されています。一般的に、入力をクエリとして使用し、コーパスから一連の文書を検索し、それらを言語モデルに追加情報として組み込んで最終的な予測を行います。しかし、これらの手法の多くは、モデルパラメータの更新や内部表現へのアクセスが必要であり、大規模なブラックボックスLMには適用が困難でした。
REPLUG
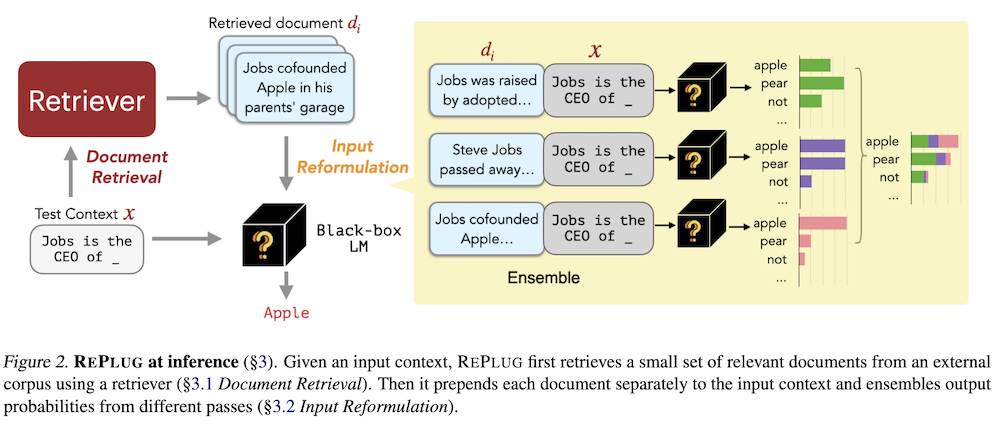
推論時のREPLUG:入力コンテキストが与えられると、REPLUGはまず外部コーパスから関連性の高い少数の文書を検索器を用いて取得します。その後、各文書を個別に入力コンテキストの前に付加し、異なるパスからの出力確率をアンサンブルします。
文書検索
入力コンテキストxが与えられたとき、検索器はコーパスDから関連性の高い少数の文書を検索することを目的とします。我々は、デュアルエンコーダーアーキテクチャに基づく密な検索器を使用します。エンコーダーは入力コンテキストxと文書dの両方をエンコードします。検索時には、入力コンテキストxにも同じエンコーダーを適用してクエリ埋め込みE(x)を得ます。クエリ埋め込みと文書埋め込みの類似度は、それらのコサイン類似度によって計算されます。
入力の再構成
検索されたトップkの文書は、元の入力コンテキストxに関する豊富な情報を提供し、LMがより良い予測を行うのに潜在的に役立ちます。我々は、アンサンブル戦略を採用しています。具体的には、検索された各文書dをxに前置し、この連結をLMに別々に渡し、すべてのkパスからの出力確率をアンサンブルします。
REPLUG LSR: 密な検索器の訓練
我々はさらに、REPLUG LSR(LM監督検索を伴うREPLUG)を提案します。これは、LM自体を使用して、どの文書を検索すべきかについての監督を提供することで、REPLUGの検索器を適応させます。我々のアプローチは、検索された文書の確率を、言語モデルの出力シーケンスのパープレキシティの確率に一致するように調整するものと見なすことができます。
実験
言語モデリング
The Pileデータセットを用いて、GPT-3およびGPT-2ファミリーの言語モデルをベースラインとして、REPLUGとREPLUG LSRの性能を評価しました。結果は、REPLUGとREPLUG LSRの両方がベースラインを大幅に上回ることを示しています。特に、REPLUG LSRは8つのモデルの平均で7.7%の改善を示し、REPLUGの4.7%を上回りました。
MMLU
Massive Multi-task Language Understanding(MMLU)データセットを用いて、5ショットの文脈内学習設定でREPLUGとREPLUG LSRの性能を評価しました。結果は、REPLUGとREPLUG LSRがCodexの性能をそれぞれ4.5%と5.1%向上させ、パラメータ数が3倍のFlan-PaLMに匹敵する結果を達成しました。
オープンドメインQA
Natural QuestionsとTriviaQAの二つのオープンドメインQAデータセットで評価を行いました。REPLUG LSRは、NQで12.0%、TQAで5.0%のCodexの性能を向上させ、少数ショット設定で最高性能を達成しました。
分析
REPLUGの性能向上が単なるアンサンブル効果からくるものではないことを示しました。また、REPLUGが多様な言語モデルファミリーに適用可能であることを実証しました。質的分析では、REPLUGが特に珍しいエンティティを含むテキストに対して有効であることが分かりました。
結論
REPLUGは、言語モデルをブラックボックスとして扱い、調整可能な検索モデルで拡張する検索拡張型言語モデリングパラダイムを導入しました。評価結果は、REPLUGが既存の言語モデルと統合して、言語モデリングやダウンストリームタスクでの性能を向上させることができることを示しています。この研究は、大規模なブラックボックス言語モデルに検索を統合する新しい可能性を切り開き、最先端の大規模LMでさえも検索から恩恵を受けられることを実証しています。