目次
本日の論文
Unifying Large Language Models and Knowledge Graphs: A Roadmap
この論文は、大規模言語モデル(LLM)とナレッジグラフ(KG)を統合するための包括的なサーベイとロードマップを提示している研究です。
以下は、LLMを活用して論文の内容を要約したものになります。
概要
大規模言語モデル(LLM)とナレッジグラフ(KG)の統合に関する包括的なロードマップを提示しています。
LLMはブラックボックスで事実的知識に欠ける一方、KGは構造化された事実的知識を提供しますが、KG自体の構築と進化には課題があります。
この研究では、KG強化LLM、LLM拡張KG、相乗効果のあるLLM+KGという3つのフレームワークを提案し、各フレームワークの既存研究をレビューした上で、将来の研究方向を示唆しています。
序論
大規模言語モデル(LLM)は、ChatGPTやGPT4などの例に見られるように、その出現能力と汎用性により、自然言語処理と人工知能の分野で新たな波を起こしています。しかし、LLMはブラックボックスモデルであり、事実的知識の捕捉とアクセスに課題があります。一方、ナレッジグラフ(KG)は、WikipediaやHuapuなどの構造化された知識モデルで、豊富な事実的知識を明示的に保存します。KGはLLMを強化し、推論と解釈可能性のための外部知識を提供できますが、KGの構築と進化には困難が伴います。そのため、LLMとKGを統合し、それぞれの利点を活用することが補完的なアプローチとなります。
背景
大規模言語モデル(LLM)
LLMは大規模コーパスで事前学習された言語モデルで、エンコーダーのみ、エンコーダー-デコーダー、デコーダーのみの3つの構造に分類されます。BERTやRoBERTaなどのエンコーダーのみモデル、T5やUL2などのエンコーダー-デコーダーモデル、GPT-3やChatGPTなどのデコーダーのみモデルが代表的です。プロンプトエンジニアリングは、LLMの効果を最大化するためのプロンプト作成と改良に焦点を当てた新しい分野です。
ナレッジグラフ(KG)
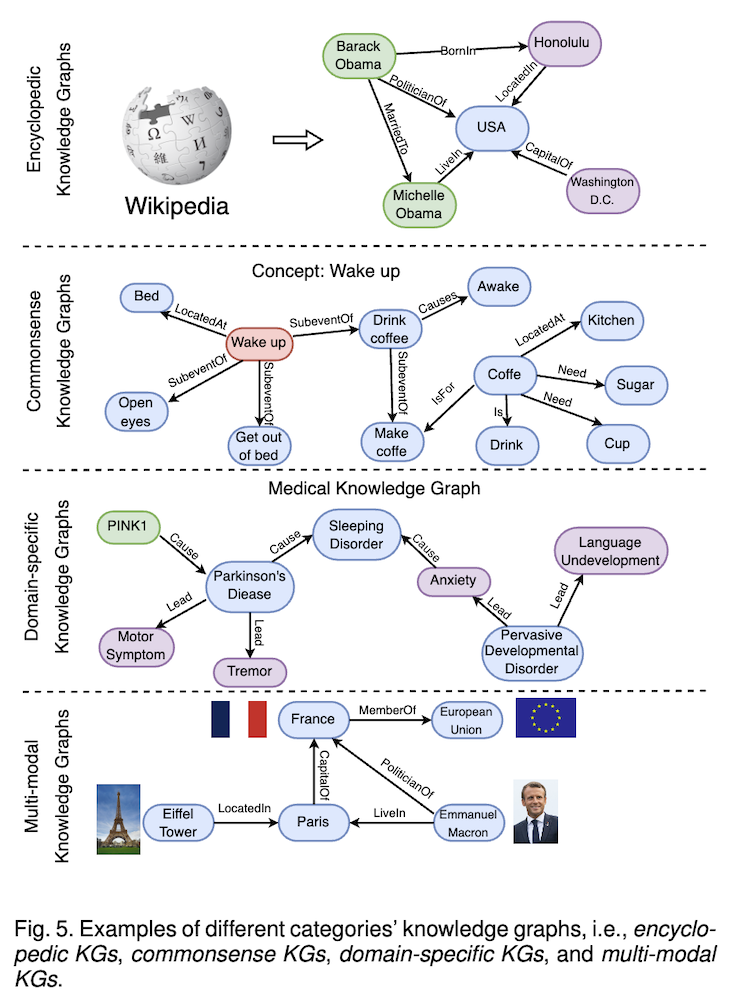
KGは構造化された知識を三つ組(エンティティ、関係、エンティティ)のコレクションとして保存します。KGは百科事典的KG、常識KG、ドメイン特化KG、マルチモーダルKGの4つに分類されます。WikidataやFreebaseなどの百科事典的KG、ConceptNetなどの常識KG、医療分野のUMLSなどのドメイン特化KG、IMGpediaなどのマルチモーダルKGが代表例です。
- 百科事典的ナレッジグラフ:実世界の一般的な知識(人物、場所、事象など)とその関係を構造化して表現します。
- 常識ナレッジグラフ:日常生活における一般的な概念、行動、因果関係などの暗黙知を形式化して表現します。
- ドメイン特化ナレッジグラフ:特定の分野(例:医療、金融、生物学など)に関する専門的な知識と関係を体系的に表現します。
- マルチモーダルナレッジグラフ:テキストだけでなく、画像、音声、動画などの多様なモダリティの情報を統合して知識を表現します。
応用
LLMとKGは様々な実世界アプリケーションに適用されています。ChatGPTやBardなどのチャットボット、Fireflyの画像編集、CopilotのコーディングアシスタントNNNEW Bingのウェブ検索、Shop.aiの推薦システムなどがLLMを活用しています。WikidataやKOなどの知識ベース、OpenBGの推薦システム、Doctor.aiのヘルスケアアシスタントなどがKGを利用しています。
ロードマップとカテゴリ化
ロードマップ
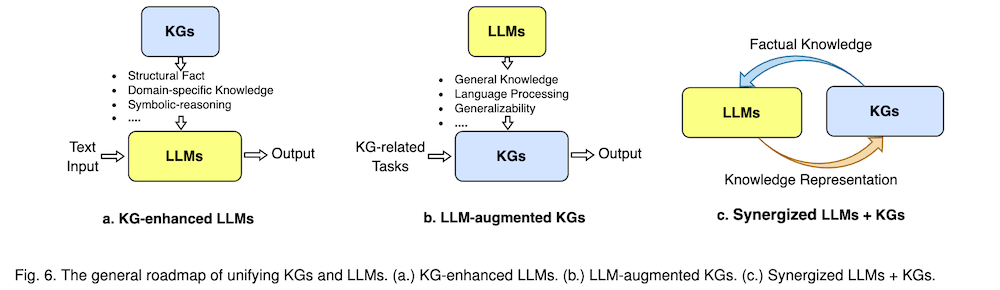
LLMとKGを統合するためのロードマップは、KG強化LLM、LLM拡張KG、相乗効果のあるLLM + KGの3つのフレームワークで構成されています。KG強化LLMとLLM拡張KGは、それぞれLLMとKGの能力を向上させることを目的とした並行フレームワークです。これらのフレームワークを基盤として、相乗効果のあるLLM + KGは、LLMとKGを相互に強化する統合フレームワークを目指しています。
カテゴリ化
研究のカテゴリ化は、KG強化LLM、LLM拡張KG、相乗効果のあるLLM + KGの3つの主要なフレームワークに基づいています。KG強化LLMは、LLMの事前学習、推論、解釈可能性の向上に焦点を当てています。LLM拡張KGは、KG埋め込み、KG補完、KG構築、KGからテキスト生成、KG質問応答などのタスクにLLMを適用します。相乗効果のあるLLM + KGは、知識表現と推論の観点から最近の試みをレビューしています。
KG強化LLM
KG強化LLM事前学習
KGをLLMの事前学習に統合する方法には、訓練目的へのKG統合、LLM入力へのKG統合、KG教示チューニングの3つのアプローチがあります。これらの方法は、LLMが実世界の知識をより効果的に学習し、表現することを可能にします。
KG強化LLM推論
LLMが最新の知識にアクセスできるようにするため、推論段階でKGを統合する方法が研究されています。主に検索拡張知識融合とKGプロンプティングの2つのアプローチがあります。これらの方法により、LLMは動的に変化する知識に対応できるようになります。
KG強化LLM事前学習と推論の比較
KG強化LLM事前学習は大量の非ラベルデータを知識で豊かにしますが、知識の更新には再訓練が必要です。一方、KG強化LLM推論は知識の更新が容易ですが、LLMが知識を十分に活用できない可能性があります。アプリケーションの要件に応じて適切な方法を選択する必要があります。
KG強化LLM解釈可能性
KGを用いてLLMの解釈可能性を向上させる研究は、LLMプロービングのためのKGとLLM分析のためのKGの2つのカテゴリーに分類されます。これらの方法は、LLMに保存されている知識を理解し、LLMの推論プロセスを解釈するのに役立ちます。
LLM拡張KG
LLM拡張KG埋め込み
LLMをKG埋め込みに適用する方法には、LLMをテキストエンコーダーとして使用する方法と、テキストとKGの共同埋め込みにLLMを使用する方法があります。これらの方法により、KG表現が豊かになり、未知のエンティティや関係の表現が改善されます。
LLM拡張KG補完
LLMをKG補完に適用する方法には、エンコーダーとしてのLLMとジェネレーターとしてのLLMの2つのアプローチがあります。これらの方法により、テキスト情報を考慮したより効果的なKG補完が可能になります。
LLM拡張KG構築
LLMをKG構築に適用する方法には、エンティティ発見、共参照解決、関係抽出、エンドツーエンドKG構築、LLMからのKG蒸留などがあります。これらの方法により、より効率的で正確なKG構築が可能になります。
LLM拡張KGからテキスト生成
LLMをKGからテキスト生成に適用する方法には、LLMからの知識活用と大規模な弱教師ありKG-テキストコーパスの構築があります。これらの方法により、KGからより自然で正確なテキスト生成が可能になります。
LLM拡張KG質問応答
LLMをKG質問応答に適用する方法には、エンティティ/関係抽出器としてのLLMと回答推論器としてのLLMがあります。これらの方法により、自然言語質問とKGのギャップを埋め、より効果的な質問応答が可能になります。
相乗効果のあるLLM + KG
相乗効果のある知識表現
テキストコーパスとKGの知識を効果的に表現する統合モデルの設計を目指しています。これにより、両方のソースからの知識をより良く理解し、多くのダウンストリームタスクに活用できます。
相乗効果のある推論
LLMとKGを効果的に活用して推論を行う統合モデルの設計を目指しています。LLM-KG融合推論とエージェントとしてのLLMによるKG推論の2つのアプローチがあり、それぞれ異なる特徴と課題を持っています。
将来の方向性とマイルストーン
LLMにおけるハルシネーション検出のためのKG、LLMにおける知識編集のためのKG、ブラックボックスLLMへの知識注入のためのKG、KGのためのマルチモーダルLLM、KG構造を理解するためのLLM、双方向推論のための相乗効果のあるLLMとKGなど、様々な将来の研究方向が提示されています。また、KG強化LLM、LLM拡張KG、相乗効果のあるLLM + KGの3つのステージを含むロードマップのマイルストーンが示されています。
結論
この論文では、LLMとKGを統合する最近の研究を包括的に概観し、KG強化LLM、LLM拡張KG、相乗効果のあるLLM + KGの3つのフレームワークに基づいてカテゴリ化しました。さらに、この分野における課題と将来の方向性について議論しています。LLMとKGの統合は、より強力な自然言語処理と人工知能システムの開発につながる重要な研究領域であり、今後さらなる発展が期待されます。