目次
DocMMIR: A Framework for Document Multi-modal Information Retrieval
この論文は、異なる形式の文書(Wikipedia記事、科学論文、プレゼンテーションスライドなど)を統合して、マルチモーダル情報検索を実現するための新しいフレームワーク「DocMMIR」を提案しています。
DocMMIRは、ウィキペディア、科学論文、スライドプレゼンテーションなどの多様なドキュメント形式を統一的に扱い、ドキュメントレベルでのマルチモーダル情報検索を実現するために設計された新しいフレームワークであり、その大規模クロスドメインベンチマークは450Kサンプルを含み、テキストと視覚情報を効果的に統合しています。
論文:https://arxiv.org/abs/2505.19312
リポジトリ:https://github.com/J1mL1/DocMMIR

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
急速な無監督表現学習と大規模な事前学習された視覚-言語モデルの進展は、クロスモーダル検索タスクを大幅に改善しました。しかし、既存のマルチモーダル情報検索(MMIR)研究は、ドキュメントレベルの検索に関する包括的な探求が不足しており、この粒度でのクロスドメインデータセットが欠如しています。この制限に対処するために、私たちはDocMMIRを導入します。これは、ウィキペディアの記事、科学論文(arXiv)、プレゼンテーションスライドなど、多様なドキュメント形式とドメインを統一するために設計された新しいマルチモーダルドキュメント検索フレームワークです。
私たちは、テキスト情報と視覚情報を体系的に統合した450Kサンプルを含む大規模なクロスドメインマルチモーダルベンチマークを構築しました。私たちの包括的な実験分析は、CLIP、BLIP2、SigLIP-2、ALIGNなどの現在の最先端MLLM(マルチモーダル言語モデル)の重要な限界を明らかにし、CLIPのみが合理的なゼロショット性能を示しました。さらに、クロスモーダル融合方法や損失関数を含むトレーニング戦略の体系的な調査を行い、私たちのベンチマークでCLIPをトレーニングするための特別なアプローチを開発しました。これにより、ゼロショットベースラインに対してMRR@10が31%向上しました。
1. はじめに
教師なし表現学習と大規模事前訓練済み視覚言語モデルの急速な発展により、クロスモーダル検索タスクが大幅に改善された。しかし、既存の多モーダル情報検索(MMIR)研究は、文書レベルの検索の包括的な探求が不足しており、この粒度でのクロスドメインデータセットが欠如している。本研究では、Wikipedia記事、科学論文(arXiv)、プレゼンテーションスライドなど、多様な文書形式とドメインを統合する新しい多モーダル文書検索フレームワークDocMMIRを導入する。450Kサンプルからなる大規模クロスドメインマルチモーダルベンチマークを構築し、テキストと視覚情報を体系的に統合した。
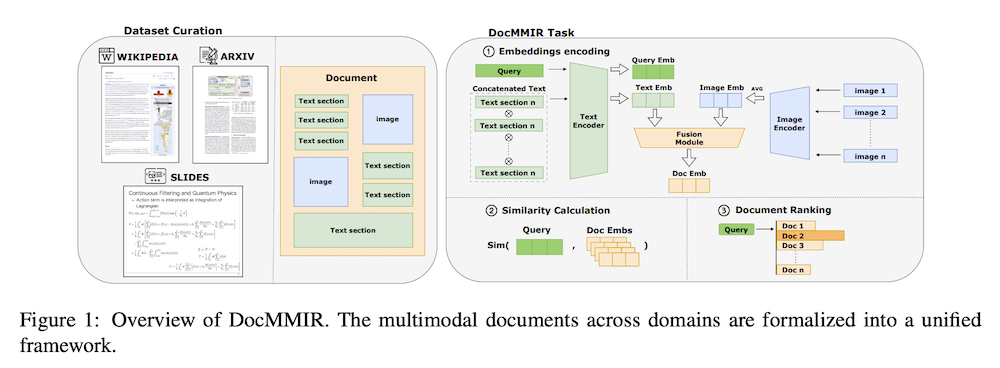
2. タスク定義
DocMMIRタスクは、Wikipedia記事、arXiv論文、プレゼンテーションスライドにまたがるヘテロジニアスなコレクションから、意味的に関連する文書を検索することを目的とする。各文書は、テキスト(段落、箇条書き、セクションヘッダー)と視覚要素(図、図表)を組み合わせている。大規模言語モデルによって生成され、文書とペアになったテキストクエリが与えられた場合、システムはすべての文書をランク付けし、正しいものを特定する必要がある。形式的には、D = {D1, D2, …, DN}をクロスドメイン文書コレクションとし、各文書Dkはテキストセグメント{ti}と画像{ij}で構成される。
3. データキュレーションパイプライン
本研究では、Wikipedia記事、arXiv科学論文、Slideshareプレゼンテーションから構成される大規模データセット(488,467文書)を構築した。各ドメインに対してドメイン特有の前処理を実施:
- Wikipedia: 1画像以上・300トークン以上でフィルタリング、画像とテキストの意味的アライメント強化
- arXiv: LaTeX数式除去、図-テキストペアの意味的関連性保持
- Slideshare: OCR適用、パープレキシティベースフィルタリングで文字化けコンテンツ除去
統一表現として、cl100k_baseトークナイザーによるテキストブロック、アライメント画像、自然言語クエリを採用し、Qwen2.5-VLで生成したクエリの87.5%が高品質基準を満たした。
4. 手法
DocMMIRは、デュアルエンコーダアーキテクチャと後期融合により文書レベルマルチモーダル検索を実行する。テキストセグメントは連結後、事前訓練済みトランスフォーマーで[CLS]トークン抽出、画像は独立エンコード後平均化処理を行う。統一文書表現は重み付き和融合で実現:Edoc = α·Etext + (1-α)·Eimg。
訓練には対称的バッチワイズ二値交差エントロピー(BCE)損失を採用し、クエリ-文書とその逆方向を等しく最適化する。この設計により、コサイン類似度による効率的な推論時検索を可能にし、大規模バッチ要件を回避しつつ安定した性能を実現した。
5. 実験設定
ゼロショット評価として、CLIP、BLIP-2、SigLIP-2、ALIGNなど最先端視覚言語モデルを検証し、ファインチューニング戦略ではViT-L/14バックボーンのOpenCLIPを使用した。訓練設定は以下の通り:
- 最適化: AdamW(学習率2e-5、重み減衰0.01)
- スケジュール: 初期10%で線形ウォームアップ、その後コサイン減衰
- ハードウェア: 8×H100、自動混合精度(AMP)
- 早期停止: 検証MRR劣化2エポック後
評価指標としてMRR@10を主要指標とし、NDCG@10とHIT@{1,3,10}で補完評価を実施した。フルコレクション検索パラダイムを採用し、実際の展開環境を反映した厳密な評価を行った。
6. 結果分析
ゼロショット評価では、既存モデルの多くがほぼゼロ性能を示し、CLIP(ViT-L/14)のみがWikipediaで部分的成功(MRR@10: 0.3247)を達成した。ファインチューニング後は劇的改善を示し、全体MRR@10が0.6993に到達した。
重要な知見:
- 重み付き和融合+BCE損失が最適(MRR@10: 0.6566)、MLP融合を大幅上回る
- Wikipedia訓練モデルが最強クロスドメイン性能(重み付き平均0.8758)
- テキストがドミナント信号だが、視覚情報が重要な補完的価値を提供
- マルチモーダル融合により単モーダルを上回る性能実現
t-SNE可視化により、ファインチューニングがクロスモーダルアライメントとドメイン特有セマンティックコヒーレンスを大幅改善することを確認した。
7. 関連研究
一般的な情報検索において、マルチモーダルベンチマークはCLIPのような対比的視覚言語事前訓練の基盤を築き、後のBLIP-2のような凍結画像エンコーダーと言語モデルのパラメータ効率的な融合を実証するアーキテクチャに発展した。文書中心の設定では、SciMMIRが500K以上の科学図表とキャプションペアをゼロショットおよびファインチューニング評価に提供し、MMDocIRがページレベルとレイアウトレベルの検索タスクを導入したが、限られたデータで行われた。DSEパラダイムはMLLMsで文書スクリーンショット全体をエンコードし、WikipediaとスライドコレクションでExcellingし、DocCVQAは14,362スキャンページでVQAを検索としてキャストする。
8. 結論
DocMMIRは、クロスドメインマルチモーダル検索において多様な文書形式を統合するためのシンプルで効果的なフレームワークを提案する。実験により、BCE損失を伴う重み付き和融合がドメイン間の堅牢性を向上させ、マルチドメイン訓練が一般化と特殊化をバランスさせることが示された。Wikipediaで訓練されたモデルが優れた適応性を示した。今後の研究では、レイアウト認識動的融合、現実的なクエリ構築、ドメインバランス訓練の探求により、DocMMIRタスクのさらなる改善が期待される。フレームワークにはいくつかの制限があり、後期融合手法はSlidesのようなレイアウト重視文書には効果的でない可能性がある。