目次
UICopilot: Automating UI Synthesis via Hierarchical Code Generation from Webpage Designs
この論文は、ウェブページデザインから階層的なコード生成を通じてユーザーインターフェースの合成を自動化する新しいアプローチ「UICopilot」を提案し、その有効性を実証しています。
UICopilotは、ウェブページデザインからのHTMLコード生成を二段階に分解することで、複雑な構造情報を効率的に捉えつつ、長大なコード生成の課題を克服する新しいアプローチを提供しています。
論文:https://arxiv.org/abs/2505.09904
リポジトリ:https://github.com/CGCL-codes/naturalcc/tree/main/examples/uicopilot

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
ユーザーインターフェース(UI)の合成を自動化することは、生産性を向上させ、開発ライフサイクルを加速させる上で重要な役割を果たし、開発時間と手作業の努力を削減します。最近のマルチモーダル大規模言語モデル(MLLM)の急速な発展により、ウェブページデザインからフロントエンドのハイパーテキストマークアップ言語(HTML)コードを直接生成することが可能になりました。しかし、実際のウェブページは多様なHTMLタグだけでなく、複雑なスタイルシートも含まれており、結果として非常に長いコードが生成されます。この長いコードは、MLLMの性能および効率に対して課題をもたらし、特にUIデザインの構造情報を捉えることが難しくなります。
これらの課題に対処するため、本論文では、ウェブページデザインからの階層的コード生成を通じてUI合成を自動化する新しいアプローチであるUICopilotを提案します。UICopilotの核心的なアイデアは、生成プロセスを二段階に分解することです。まず、粗粒度のHTML階層構造を生成し、次に細粒度のコードを生成します。
UICopilotの効果を検証するために、我々は実世界のデータセットであるWebCode2Mを用いて実験を行い、実験結果はUICopilotが自動評価指標および人間評価の両方において既存のベースラインを大幅に上回ることを示しています。特に、統計分析により、ほとんどの人間の評価者がUICopilotによって生成されたウェブページをGPT-4Vによって生成されたものよりも好むことが明らかになりました。
1. はじめに
ウェブページデザインをコードに直接変換することは、フロントエンド開発を効率化し、開発時間と手作業を大幅に削減します。この自動化はデベロッパーの生産性を向上させるだけでなく、コード生成におけるヒューマンエラーのリスクも最小限に抑えます。初期の取り組みとしては、pix2codeがニューラルネットワークを訓練してDSLコードを生成し、Sketch2codeが手描きスケッチからコードを生成するアプローチがありました。近年は、マルチモーダル大規模言語モデル(MLLM)の急速な発展により、高品質なUIコードをウェブページデザイン(スクリーンショットなど)から生成することがますます可能になってきています。
1.1 課題と動機
一段階生成アプローチには、主に二つの課題があります:
C1:生成する必要があるコードの長さが膨大であること。既存のコード生成タスクは主に数百トークン以下の短いコードスニペットや関数に焦点を当てていますが、実際のウェブページはHTMLだけでなく複雑なCSSも含み、コード長が大幅に増加します。Common Crawlデータセットのウェブページは数万トークンを含み、広範なクリーニング後でも平均5,000トークン以上あります。
C2:深くネストされた構造を生成する複雑さ。ウェブページは通常、複数層のネスト要素で構成されており、高解像度のデザイン図からこれらの複雑な構造を生成することは特に困難です。先行研究ではGPT-4Vでさえ構造情報を正確に捉えるのに苦労することが示されています。
2. 予備知識
2.1 ウェブページデザインの階層構造
ウェブページコードは通常、HTML、CSS、JavaScriptの主要3コンポーネントから構成されます。本研究では静的ウェブページの生成に焦点を当て、JavaScriptは除外しています。ウェブページデザイン図の構造情報は主に要素間の階層関係と、それらのサイズと位置で構成されます。まず、ウェブページコードはHTML DOMツリー(図1(c))によって表される階層的でネストされた構造に従います。次に、ウェブページ要素のサイズと位置はバウンディングボックス(BBox)(図1(b))によって捉えられ、主要なレイアウト構造を定義します。
2.2 MLLMによる画像からコードへの変換
最近、MLLMはテキスト、画像、音声など多様なモーダルコンテンツの理解と生成において大きな進歩を遂げています。本研究では、階層構造予測用の構造モデルとしてPix2Struct-1.3Bを、コード生成エージェントとしてGPT-4Vを導入しています。Pix2StructはViTベースの画像エンコーダとアスペクト比保存スケーリング戦略を採用しており、極端なアスペクト比に対してより堅牢で、様々なシーケンス長と解像度に適応できます。
3. UICopilot
3.1 タスク説明
高解像度のウェブページデザイン(既存ウェブページのスクリーンショットなど)が与えられた場合、UICopilotは対応するHTMLとCSSコードを自動的に生成することを目的としています。レンダリングされた結果のウェブページは、レイアウト、スタイリング、コンテンツの面で入力デザインに密接に類似している必要があります。このプロセスの重要な側面は、ページの構造要素(コンポーネントの種類、寸法、位置など)を正確に定義することです。
3.2 概要
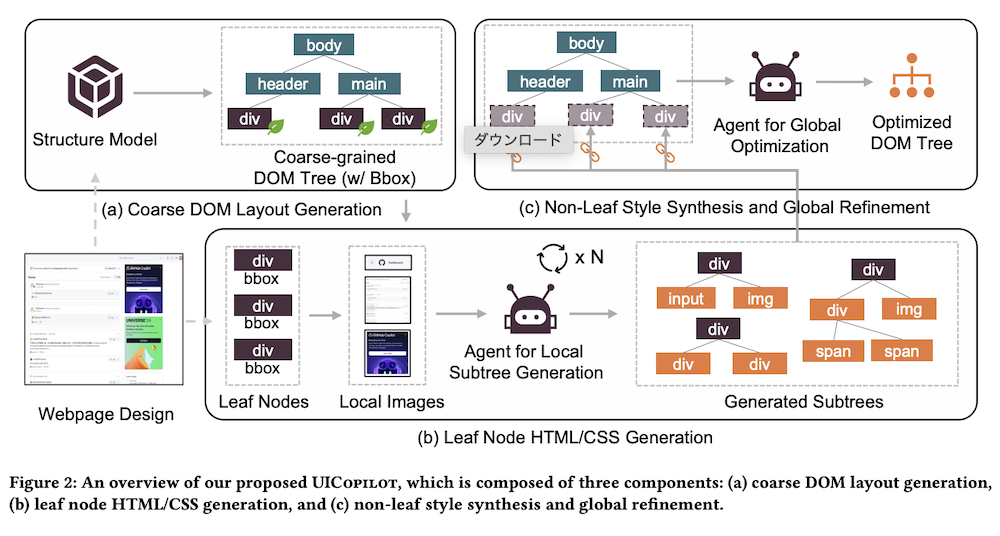
図2に示すように、ウェブページ生成プロセスを粗粒度のDOMレイアウト生成(図2(a))と細粒度のコード合成(図2(b&c))の2段階に分解しています。このアプローチは「デザイン内の要素と構造が十分にシンプルである場合、MLLMは構造と詳細の両方を捉えたウェブページコードを効果的に生成できる」という仮定に基づいています。
3.3 粗粒度DOMレイアウト生成
ウェブページの構造情報をより正確かつ効率的に生成するために、ノードタイプ、階層、ノードのバウンディングボックス(BBox)のみを捉えたHTML DOMツリーの粗粒度バージョンを予測するために特別に設計された構造モデルを導入し、訓練しています。また、パフォーマンスを最適化するためにデータ枝刈りと訓練手順を慎重に設計しています。
ViTベースのPix2Structモデルを核として採用し、様々な解像度のウェブページデザインを処理します。高解像度の画像を直接クロップまたはリサイズすると重要な詳細が失われることが多いため、ViTのアプローチを採用し、画像を複数のパッチに分割して可能な限り多くの情報を保持しています。
また、BBoxベースのデータ枝刈り戦略を適用しています:
- 合計面積の3%未満のBBoxを削除
- 単色ピクセルのみを含むBBoxを削除
- 全ページで合計10個未満のBBoxを持つウェブページサンプルを破棄
3.4 細粒度コード合成
生成された粗粒度DOMツリーにはノードタイプと階層は含まれていますが、2つの重要な側面が欠けています:
- リーフノードのローカル領域の構造とスタイルコード
- 粗粒度DOMツリー内の非リーフノードの属性とスタイル
これらの欠けている要素に対処するために、以下の2つのステップを考案しました:
リーフノードのHTML/CSS生成:GPT-4Vをローカルコード生成エージェントとして活用し、予測された粗粒度DOMツリー内のリーフノードのBBoxを使用して、対応するサブリージョンの画像を元の画像からクロップします。これらのセグメント化された画像を個別にコード生成エージェントに供給し、各サブリージョンに対応するHTML/CSSコードを予測します。
非リーフスタイル合成とグローバル洗練:前のステップからのコードと完全なデザイン画像をエージェントに提供し、粗粒度DOMツリーの非リーフノードにスタイルやその他の属性を追加するよう指示します。エージェントはグローバルレイアウトとビジュアル要素を分析して、フォント、色、マージン、パディングなどのスタイリングの詳細を推測し、最終的なコードが構造階層と元のデザインの視覚的な美しさの両方を反映するようにします。
4. 実験と分析
4.1 データセット
訓練データセット:構造モデルの訓練にWebSight v0.1とWebCode2Mの2つのデータセットを使用しています。表1に示すように、WebSight比較してWebCode2Mのデータはより複雑で、スタイルやタグタイプのバリエーションが豊富で、長さも大幅に長く、実世界のHTMLコードに近いものです。また、WebCode2MはページのBBox情報を直接提供しており、構造モデルの訓練に不可欠です。
テストデータセット:WebCode2Mテストデータセットを使用して評価を行っています。このテストデータセットは3つのサブセットで構成されています:WebCode2M-Short、WebCode2M-Mid、WebCode2M-Longです。これらのサブセットは、正解HTMLコードの長さの範囲によってデータを分割して作成されています。
4.2 評価指標
CLIP類似度、SSIM(構造類似性インデックス)、ビジュアルスコアの3つの自動評価指標を使用しています。CLIPは対照的な目標を使用してトレーニングされたマルチモーダルモデルで、入力のセマンティック情報をキャプチャするベクトルを生成します。SSIMは画像内の構造的、輝度、コントラスト情報の変化を考慮します。ビジュアルスコアはブロックレベルの色、テキスト、位置、テキスト色、CLIP類似度情報などの5つのサブ指標で構成される複合指標です。
4.3 ベースライン
ベースラインは2つのカテゴリに分類されます:
- ウェブページ生成に特化したMLLM:WebSight VLM-8B、Design2Code-18B
- 汎用MLLM(プロンプトベース):CogAgent-Chat-18B、GPT-4V、LLaVA-v1.5-7B
4.4 UICopilotの有効性
全体的なパフォーマンス:表2はUICopilotとベースラインのWebCode2Mテストデータセットでのパフォーマンス内訳を示しています。UICopilotのビジュアルスコアとCLIP類似度は、すべてのベースラインを3つのテストデータセット全体で大幅に上回っています。特筆すべきことに、UICopilotはGPT-4Vを使用して細粒度コードを生成していますが、3つのテストデータセットでビジュアルスコアがそれぞれ23%、27%、48%向上しており、特にウェブページサンプルの長さが長くなるほどUICopilotのGPT-4Vに対する優位性が大きくなっています。
4.5 min_areaとmax_depthの影響
3.3節で説明したように、min_area(BBoxの最小面積)とmax_depth(DOMツリーの最大深さ)の2つのパラメータに基づいて構造モデルによって生成された結果を枝刈りしています。グリッドサーチを実施して最適な値を探索した結果、max_depth=4とmin_area=10%がビジュアルマッチングのバランスの取れたローカル最適値を達成することが分かりました。
4.6 人間による評価
表2ではUICopilotとGPT-4VのCLIP類似度とSSIMの差は最小限ですが、「どちらのモデルが元のデザインに近いウェブページを生成するか」という問いに答えるために人間による評価研究を実施しました。UICopilotとGPT-4Vによって生成されたウェブページのペアを6人のアノテーターに提示し、各ペアのサンプルをシャッフルしてバイアスを排除しました。図9に示すように、選択の60%以上がUICopilotを支持しており、元のデザインにより近いウェブページを生成する効果を強く証明しています。
4.7 ケーススタディ
図10に代表的な例を示しています。左から順に、元のウェブページ、GPT-4Vによって生成されたもの、UICopilotによって生成されたものを示しています。GPT-4VとUICopilotの両方がフッター、本文、ヘッダーをキャプチャし、テキスト内容も元のものに近いですが、GPT-4Vは右側の小さなブロックを簡略化している一方、UICopilotはこれらの構造的詳細を正確に複製しています。
5. 関連研究
5.1 画像表現学習
画像キャプション、画像からコードへの変換、画像分類など様々なコンピュータビジョンタスクの基盤となる効果的な画像表現の学習について説明しています。自己教師あり学習を通じて特徴抽出を改善するための対照学習の活用、固定サイズのパッチに画像を分割してTransformerベースのアーキテクチャで処理するViTの革新的なパラダイム、画像表現と視覚データ生成のための強力なツールとして登場した拡散モデルなど、様々な戦略が探究されています。
5.2 コード生成
コード要約、コード検索、コード生成など、コードインテリジェンスの主要タスクにおけるニューラル言語モデルの顕著な進歩について説明しています。テキスト生成におけるLLMの急速な進化により、CopilotやCodeWhispererなどの生産ツールを強化する多数のコード特化型LLMが登場し、コーディングワークフローを効率化し開発者の生産性を向上させています。
5.3 画像からコードへの変換
画像から直接コードを生成する先行研究について説明しています。Sketch2Codeはコンピュータビジョンベースと深層学習ベースの補完的アプローチを使用してワイヤフレームスケッチからウェブサイトコードを生成し、Pix2Structはマスクされたウェブサイトスクリーンショットから簡略化されたHTMLコードを予測するよう事前トレーニングされています。また、UI生成におけるMLLMの能力を向上させるための特殊なトレーニングデータセットの作成や、これらのモデルを評価するためのベンチマークと評価指標の確立も行われています。
6. 結論
本論文ではUICopilotを提案し、ウェブページデザインからのコード生成プロセスを粗粒度DOMツリー予測と細粒度コード合成の2段階に分解しています。具体的には、BBoxベースのデータ枝刈り戦略によって強化されたViTベースの構造モデルを採用してDOMツリーを予測しています。構造モデルによって生成された粗粒度DOMツリーとバウンディングボックスを使用して、コード生成をさらに2つのサブステップに簡略化しています:まず入力画像のセグメント化されたサブリージョンのコードスニペットを生成し、次にこれらのスニペットを最終コードにアセンブルします。この分解により、1ステップでの長いコードシーケンスの生成に関連する複雑さが効果的に削減されます。広範な実験評価と人間のアノテーターからのフィードバックにより、アプローチの有効性が確認されました。