目次
UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning
この論文は、ルールベースの強化学習を用いて、マルチモーダル大規模言語モデルのグラフィカルユーザーインターフェース(GUI)におけるアクション予測能力を向上させるためのUI-R1フレームワークを提案しています。
UI-R1は、わずか136の高品質なサンプルを用いて、ルールベースの強化学習を通じてGUIアクション予測タスクの推論能力を向上させる新しいフレームワークを提供し、従来の監視付きファインチューニングよりも効率的かつスケーラブルなアプローチを実現しています。
論文:https://arxiv.org/abs/2503.21620
リポジトリ:https://github.com/lll6gg/UI-R1

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
最近のDeepSeek-R1は、ルールベースの報酬を用いた強化学習(RL)を通じて、LLMにおける推論能力の出現を示しました。言語モデルでの成功にもかかわらず、特にグラフィカルユーザーインターフェース(GUI)エージェントのタスクにおけるマルチモーダル領域での応用は未だ十分に探求されていません。
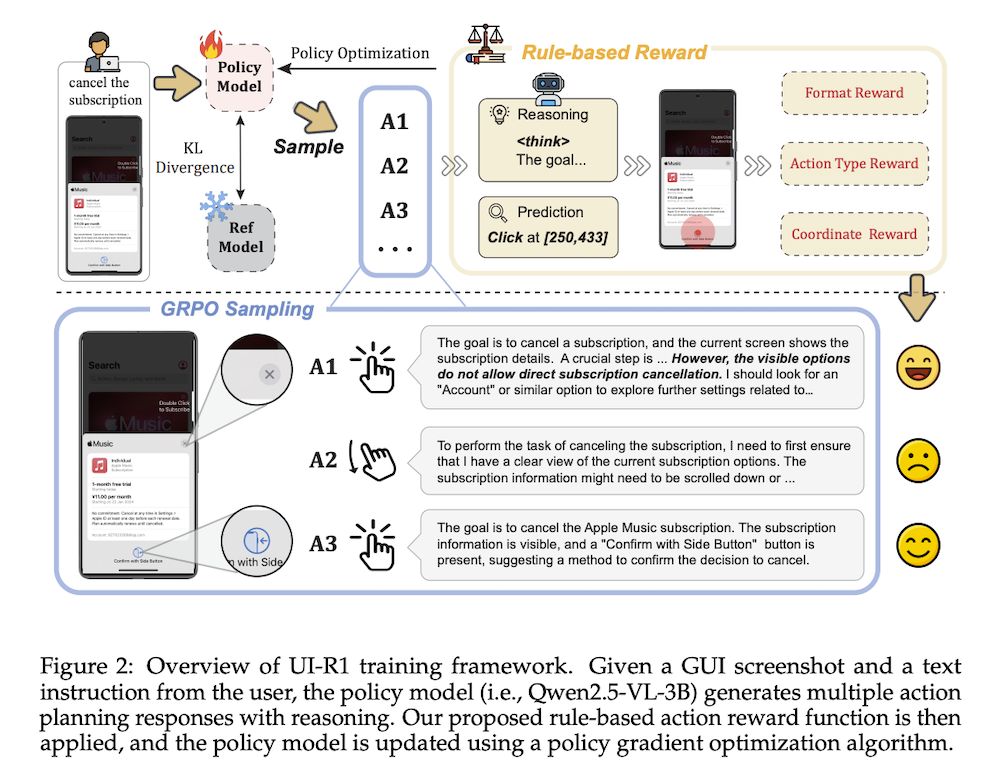
この問題に対処するため、私たちはUI-R1を提案します。これは、GUIアクション予測タスクにおけるマルチモーダル大規模言語モデル(MLLM)の推論能力を向上させるためのルールベースのRLの適用を探る初のフレームワークです。具体的には、UI-R1は新しいルールベースのアクション報酬を導入し、Group Relative Policy Optimization(GRPO)などのポリシーに基づくアルゴリズムを介してモデル最適化を可能にします。
効率的なトレーニングのために、私たちはモバイルデバイス上の5つの一般的なアクションタイプを含む136の難易度の高いタスクから成る小規模でありながら高品質なデータセットをキュレートしました。実験結果は、提案するUI-R1-3Bが、Qwen2.5-VL-3Bというベースモデルに対して、ScreenSpotでの平均精度の向上が22.1%、ScreenSpot-Proで6.0%、ANDROID CONTROLで12.7%といった顕著な改善を達成することを示しています。さらに、UI-R1-3Bは、76Kサンプルを用いて監視付きファインチューニング(SFT)でトレーニングされたより大きなモデル(例:OS-Atlas-7B)と比較しても競争力のあるパフォーマンスを発揮します。これらの結果は、ルールベースの強化学習がGUIの理解と制御を進展させる可能性を強調し、この分野での今後の研究への道を開くものです。
1. UI-R1: GUIエージェントの効率的なアクション予測を強化する強化学習
1.1 概要
本研究は、ルールに基づく強化学習(RL)を用いて、マルチモーダル大規模言語モデル(MLLM)のGUIアクション予測能力を向上させるUI-R1フレームワークを提案する。特に、ポリシー最適化アルゴリズム(GRPO)を介して最適化を行う新たなアクション報酬を導入し、136の高品質なタスクデータセットを用いて訓練を行った。実験結果では、UI-R1-3BがQwen2.5-VL-3Bに対して22.1%の精度向上を記録し、競争力のある結果を示した。
2. 関連研究
2.1 GUIエージェント
MLLMを用いたGUI関連タスクの研究は進展しており、CogAgentやAppAgentシリーズが代表的である。しかし、これらは大規模なラベル付きデータに依存しており、特にOODシナリオでの性能が課題となっている。
2.2 ルールベースの強化学習
ルールに基づく強化学習は、事前定義された報酬関数を用いてモデルの行動を導く効率的な手法である。DeepSeek-R1がこの手法を導入し、視覚的タスクへの適用が進められているが、GUIアクション予測への拡張は未開拓である。
3. 方法
3.1 概要
UI-R1は、低レベルの指示に基づくタスクを遂行するために設計された強化学習の枠組みである。モデルは、GUIスクリーンショットに基づいてアクションを生成し、報酬を評価してポリシーを最適化する。
3.2 ルールベースのアクション報酬
アクション報酬は、アクションタイプ、座標精度、フォーマット報酬の3つのコンポーネントで構成され、GUIエージェントの行動予測能力を向上させる。特に、座標精度報酬はクリックアクションにおける誤差を最小限に抑える。
3.3 高速グラウンディング
UI-R1-E-3Bは、DASTとNOTHINKの2段階で訓練され、迅速で正確なグラウンディングを実現する。DASTはタスクの難易度に応じた報酬を調整する。
3.4 データ選択
データ選択は、品質、難易度、多様性に基づいて行い、136の高品質なモバイルタスクサンプルを選出した。このプロセスにより、データ効率が向上し、モデルの性能を最大化する。
4. 実験
4.1 GUIグラウンディング能力
UI-R1は、ScreenSpotおよびScreenSpot-Proベンチマークを使用して評価され、従来のモデルと比較して大幅な性能向上を示した。特に、UI-R1-3Bは他のモデルを上回る結果を記録した。
4.2 アクション予測能力
低レベルの指示に基づくアクション予測能力を評価し、UI-R1は136のサンプルのみで高精度を実現した。この結果は、データ効率の高い強化学習フレームワークの効果を示している。
4.3 主要因の研究
データサイズや推論の長さがモデルの性能に与える影響を調査し、困難なタスクにおいては強化学習が特に効果的であることが確認された。
4.4 アブレーションスタディ
報酬関数の設計やデータ選択方法の影響を評価し、特にアクション報酬と座標報酬の組み合わせが効果的であることを示した。
5. 結論
UI-R1フレームワークは、GUIアクション予測タスクにおけるルールベースの強化学習を拡張し、従来のスーパーバイズドファインチューニング(SFT)に代わるスケーラブルなアプローチを提供する。限られたデータを用いても顕著な性能向上を実現し、将来の研究における可能性を示している。