目次
Document Image Rectification Bases on Self-Adaptive Multitask Fusion
この論文は、文書画像の歪みを補正するための自己適応型マルチタスク融合ネットワーク「SalmRec」を提案し、タスク間の特徴の相互作用を活用することで、補正性能を向上させることを目的としています。
この論文の特徴は、タスク間の相互作用を考慮した自己適応型の特徴集約モジュールを用いることで、変形した文書画像の補正精度を向上させる点にあります。
論文:https://arxiv.org/abs/2505.06038

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
この論文では、変形した文書画像の補正が、レイアウト分析やテキスト認識などの実世界の文書理解タスクにとって重要であると述べています。しかし、現在のマルチタスク手法は、背景除去、3D座標予測、テキストラインセグメンテーションなどのタスク間の相互作用や補完的な特徴を見落とすことが多いです。
このギャップを解消するために、自己適応型の学習可能なマルチタスク融合補正ネットワークであるSalmRecを提案します。このネットワークは、幾何学的歪みの認識を改善し、特徴の補完性を強化し、負の干渉を減少させるために、タスク間の特徴集約モジュールを組み込んでいます。また、グローバルタスク内およびローカルタスク間の特徴のバランスを効果的に取るためのゲーティングメカニズムも導入しています。
DIR300とDocUNetという2つの英語のベンチマークおよびDocRealという1つの中国語のベンチマークにおける実験結果は、我々の手法が補正性能を大幅に向上させることを示しています。アブレーションスタディは、異なるタスクがデワーピングに与える正の影響と、我々の提案したモジュールの有効性を強調しています。
1. 序論
実世界の文書理解に必要な変形文書画像の矯正において、既存のマルチタスク手法はタスク間の相補的特徴と相互作用を見過ごしています。本研究ではSalmRecという自己適応型マルチタスク融合矯正ネットワークを提案し、タスク間特徴集約モジュールとゲーティングメカニズムを導入しました。これにより、幾何学的歪みの認識向上、特徴の相補性強化、負の干渉減少を実現しています。DIR300、DocUNet(英語)とDocReal(中国語)ベンチマークでの実験結果は、矯正性能の大幅な向上を示しています。
2. 関連研究
2.1. 伝統的手法
ディープラーニング以前の手法は、パラメトリック回帰を採用し、画像表面上の明確な特徴(テキストライン、円筒形表面曲線、文書境界)に依存していました。これらは文書の浅い視覚表現に焦点を当て、3D形状再構築を必要としませんでした。しかし、暗い照明や影、背景と前景の色が近い場合など、実際のシーンでは効果が限られていました。
2.2. ディープラーニングベースの手法
補助情報なしの手法
DocUNet、AGUN、DDCP、FDRNetなどは二次元変形フィールドを直接予測します。DocUNetは積み重ねられたUNet構造を使用し、AGUNは粗から細へのアプローチで複数解像度のアンチ歪みメッシュを予測します。DDCPはスパースコントロールポイントとリファレンスポイント間のマッピングを推定し、FDRNetは構造情報捕捉のためにフーリエ空間の高周波成分に焦点を当てています。
補助情報ありの手法
近年の研究は文書特徴関連の追加情報を導入しています。一部は前処理として背景除去を使用し、軽量ネットワークでバイナリマスクを予測して文書前景のみの画像を取得します。DewarpNetやDocGeoNetなどは補助タスクとして3D座標特徴を導入し、LA-DocFlattenはUVテクスチャ座標と文書レイアウト情報の共同回帰を提案しています。ローカル特徴に焦点を当てた方法もあり、本研究のSalmRecは異なる粒度間の共同学習を通じて特性化しています。
3. 方法論
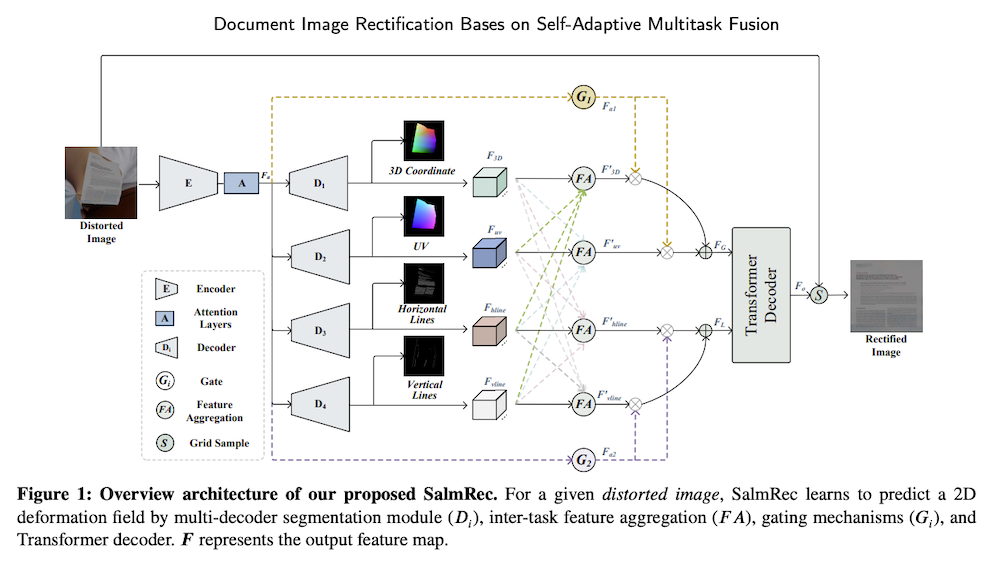
提案したSalmRecは以下の主要コンポーネントから構成されています:
- マルチデコーダセグメンテーションモジュール:エンコーダを共有し、4つの異なる粒度の特徴(3D座標、UVマップ、水平・垂直ライン)をセグメント化
- タスク間特徴集約モジュール(FA):leave-one-out手法でタスク間の相関を学習し、冗長特徴の干渉を減少
- ゲーティングメカニズム:グローバル特徴(3D座標、UVマップ)とローカル特徴(水平・垂直ライン)の重要性を動的に選択
- トランスフォーマーデコーダ:洗練された特徴を入力とし、2D変形フィールド座標を予測
ネットワークはUNet構造をベースとし、各デコーダは独立して学習されます。損失関数としては、グローバル特徴にMSE損失、ローカル情報にBCE損失を使用し、背景・前景ピクセル数の差をバランスさせるためのライン損失も導入しています。これらのコンポーネントが連携することで、歪んだ文書画像の幾何学的歪みを効果的に認識し、補正能力を向上させています。
4. 実験
4.1. データセット
正確な注釈を持つ歪み文書画像データセットDocDewarpHVを使用し、3D座標とUVマップに加えて水平・垂直ラインという2種類のローカル歪み情報で各画像に注釈付けしています。テスト用データセットとして次の3つを使用:
- DIR300:最大かつ最も多様なベンチマークで、照明、影、折り目、曲線などの異なる強度と様々な背景干渉を持つ300枚の自然シーン歪み画像を含む
- DocReal:最大の中国語評価データセットで、契約書、請求書、教科書など200文書画像を含む
- DocUNet:ディープラーニングを初めて適用した広く使用されるベンチマークで、請求書、チラシ、書籍、ポスターなど130の自然環境歪み画像を含む
4.2. 評価指標
MS-SSIM、LD、AD:Multi-Scale Structural Similarityは修正画像と参照画像間のグローバル類似性評価に使用。Local DistortionはSIFTフロー計算でローカル詳細に焦点。Aligned Distortionは、MS-SSIMの微妙なグローバル変化への非感度とLDのテクスチャ欠如領域での不正確さを最適化。
ED、CER:テキスト認識精度評価にEdit DistanceとCharacter Error Rateを使用。EDは挿入、削除、置換後に文字列を参照文字列に変換する最小回数を定義し、CERはEDを参照文字列長で割って計算。DIR300では90の豊富なテキスト文書画像、DocUNetでは50と60画像、DocRealでは全200画像を評価。
4.3. 実装の詳細
Pytorchで実装し、4台の32GB NVIDIA V100 GPUで60エポック、バッチサイズ32、10,000ウォームアップステップでトレーニング。オプティマイザはAdamW、学習率は最大1.2×10^-4、最小5×10^-7のコサイン減衰戦略を採用。評価指標はMatlab R2019aで評価し、OCRパフォーマンスは英語ベンチマークでTesseract v5.0.1、中国語DocRealでは中国語テキスト認識での優れたパフォーマンスを持つPaddleOCRを使用。
4.4. 実験結果
DIR300ベンチマークでのパフォーマンス
4つの評価指標全てで顕著な改善:MS-SSIM(+1.52%)、LD(-9.82%)、AD(-8.72%)、ED(-7.98%)、CER(-20.77%)。特にFTDRと比較してCERで33.81%の大幅な改善を達成し、LA-DocFlattenと比較してもグローバル類似性とローカル詳細測定指標で向上(MS-SSIM/3.08%、LD/9.82%、AD/8.72%)。図4は多様なタイプやシーンの歪み画像に対する堅牢性を示しています。
DocRealベンチマークでのパフォーマンス
中国語ベンチマークでも優れたパフォーマンスを示し、DocReal手法と比較してMS-SSIM、LD、ADでそれぞれ5.36%、14.45%、3.78%の改善。テキストライン注意を採用するRDGR、DocGeoNet、FTDRと比較しても最先端のパフォーマンスを達成。図5は自然シーンの複雑な背景干渉画像や折り畳まれた手書きメモ、アフィン変換特性を持つチケットなどでの優位性を示しています。
DocUNetベンチマークでのパフォーマンス
ライン重視手法(RDGR、FTDR、DocGeoNet)に対して60画像OCR設定でCERとEDで少なくとも12.13%と12.89%の改善。3D座標やUVマップを導入する手法(DewarpNet、Pice-Wise、LA-DocFlatten、UVDoc)に対してもOCRパフォーマンスで大幅な改善(CER/13.33%、ED/15.76%)。図6は文書境界と水平・垂直ラインの明確なセグメンテーション能力を示しています。
4.5. アブレーション研究
異なるタスクまたはグループ化が矯正結果に与える影響
単一タスクではUVマップがOCRパフォーマンスに正の影響を与え、ローカル詳細修正では水平ライン情報が両ベンチマークで最高値に達します。複数タスク組み合わせでは、3D座標とUVマップがグローバル修正に正の貢献をしますが、UVマップに3D特徴を導入するとOCRパフォーマンスが大幅に低下。タスクが必ずしも相互に有益ではなく、効果的な融合モジュールが必要であることを示しています。
特徴集約モジュールとゲートのアブレーション
4つのタスク全て予測下で特徴集約モジュール(FA)とゲーティングメカニズム(Gate)の効果を選択的に検証。これら二つのモジュールが共同で矯正タスクに機能し、ほぼ全ての指標で明らかな改善をもたらします。特徴融合なしの2D変形フィールド直接予測と比較して、3ベンチマークでMS-SSIMは平均3.40%増加し、LDとADもそれぞれ5.05%と4.42%改善。テキスト認識精度ではEDが4.9%、CERは10.3%の向上を達成しました。
5. 結論
SalmRecという適応タスク選択型歪み文書矯正アーキテクチャを提案しました。この手法は異なる粒度間の複数特徴集約を効果的に洗練し、提案したゲーティングメカニズムで類似粒度の情報出力を制御します。複数ベンチマークでの広範な実験は、本ネットワークが複数タスクの利点を集約し、タスク内の相互干渉を軽減できることを示しています。将来の研究では、複雑な背景を持つ歪み文書画像修正のためのより軽量で堅牢なネットワークの探究が可能です。