目次
Recognize Any Regions
この論文は、オープンワールドの物体認識において、位置情報と意味情報を統合する新しいフレームワーク「RegionSpot」を提案し、従来の手法よりも高い性能と効率を実現したことを報告しています。
RegionSpotは、凍結された基盤モデルを活用し、位置情報と意味情報を効率的に統合することで、オープンワールド物体認識において高い性能を達成しながらも、トレーニングコストを大幅に削減する革新的なアーキテクチャです。
論文:https://arxiv.org/abs/2311.01373
リポジトリ:https://github.com/Surrey-UPLab/Recognize-Any-Regions

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
画像の個々の領域やパッチの意味を理解すること、特にオープンワールドの物体検出においては、依然として重要かつ困難な課題です。CLIPのような強力な画像レベルのビジョン・ランゲージ(ViL)基盤モデルの成功を背景に、最近では、広範な領域-ラベルペアのコレクションを用いてコントラストモデルをゼロから訓練するか、検出モデルの出力を領域提案の画像レベルの表現に整合させることによって、これらの能力を活用しようとする試みが見られます。しかし、これらのアプローチは、計算集約的なトレーニング要件、データノイズへの感受性、および文脈情報の不足に悩まされています。
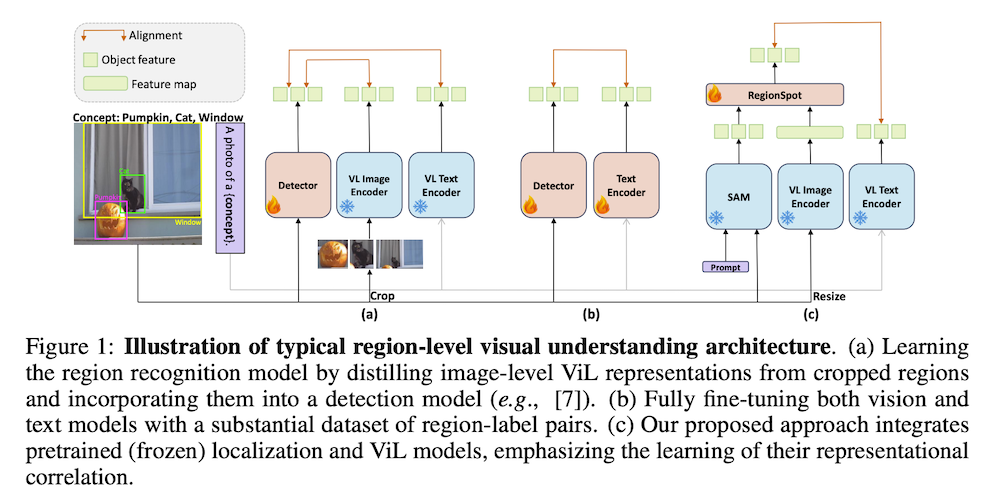
これらの制限に対処するために、私たちは市販の基盤モデルの相乗的な可能性を探求し、それぞれの位置決めと意味に関する強みを活用します。私たちは、位置情報を意識したローカリゼーション知識をローカリゼーション基盤モデル(例:SAM)から、意味情報をViLモデル(例:CLIP)から統合するために設計された新しく、一般的で効率的なアーキテクチャ「RegionSpot」を導入します。事前トレーニングされた知識を最大限に活用しつつ、トレーニングのオーバーヘッドを最小限に抑えるために、両方の基盤モデルを凍結したままにし、最適化の努力を軽量な注意ベースの知識統合モジュールのみに集中させます。
オープンワールド物体認識における広範な実験により、RegionSpotは従来の代替手法に対して大幅な性能向上を達成し、計算コストの大幅な削減も実現しました(例:8つのV100 GPUを使用して1日で300万データでモデルをトレーニング)。RegionSpotは、LVIS検証セットでGLIP-LをmAPで2.9ポイント上回り、より挑戦的で希少なカテゴリについては13.1ポイントの大きなマージンを示し、ODinWでは2.5ポイントのAP増加を達成しています。さらに、LVISミニバルセットの希少カテゴリでは、GroundingDINO-Lを11.0ポイント上回ります。コードは次のURLで利用可能です。
1. 序論
1.1 はじめに
本章では、目的に特化した画像レベルのビジョン・ランゲージ(ViL)表現学習の進展について述べる。CLIPやALIGNのような基盤モデルの成功により、視覚およびマルチモーダルの下流タスクにおいて顕著なパフォーマンス向上が見られた。この進展は、数百万から数十億の豊富な情報を含むデータセットの利用によるものである。研究者たちは、画像の特定の領域(例:オブジェクト)を理解するための普遍的なアプローチを模索しており、これには画像レベルの事前学習モデルを利用した学習が含まれる。特に、切り取った領域を用いてセマンティクスを学習し、表現蒸留を行う手法が注目されている。しかし、個々の切り取った領域を使用すると、重要な文脈情報が失われることがある。これに対処するために、著者たちは、ローカリゼーション基盤モデルとViLモデルの強みを活かした新しいアーキテクチャ「RegionSpot」を提案する。
1.2 研究の目的
RegionSpotは、ローカリゼーションとセマンティクスの知識を統合することで、画像の理解を進めることを目的としている。この新しいアプローチは、既存の大規模な事前学習モデルを活用し、トレーニングオーバーヘッドを最小限に抑えつつ、性能を向上させることを目指している。
2. 方法論
2.1 基盤モデル
ビジョン・ランゲージ基盤モデルは、コントラスト学習を使用して視覚データとテキストデータを共有の埋め込み空間にマッピングする。CLIPは4億のテキスト-画像ペアを使用し、ALIGNは18億ペアを利用している。これらのモデルは、ペアとなった画像とテキストの距離を最小化し、非ペアの距離を最大化することを目的としている。
ローカリゼーション基盤モデルの例としてSAMモデルが挙げられる。SAMは、10億以上の自動生成マスクを含むSA-1Bデータセットで訓練されており、セグメンテーションデータセットの中で前例のないスケールを誇る。このモデルは、画像エンコーダー、プロンプトエンコーダー、マスクデコーダーの3つの主要モジュールから構成されている。
2.2 領域テキストのアラインメント
RegionSpotでは、SAMモデルから位置に敏感なトークンを抽出し、ViLモデルを使用して画像レベルのセマンティック特徴マップを生成する。この二つのモデル間の関連性は、クロスアテンションメカニズムを介して実現される。具体的には、ローカリゼーションモデルからの位置に敏感なトークンを「クエリ」として、ViLモデルから生成されたセマンティック特徴マップを「キー」と「バリュー」として使用する。この関連性により、地域レベルの理解が促進される。
- 位置に敏感なトークンの生成
手動でアノテーションされたオブジェクトバウンディングボックスを用いて、SAMモデルから位置に敏感なトークンを抽出する。これにより、オブジェクトのテクスチャや位置に関する情報をエンコードしたトークンが得られる。 画像レベルのセマンティック特徴マップ
画像全体の特徴マップは、複数のオブジェクトを含むことができ、ViLモデルを用いてリサイズされた画像を入力することで得られる。位置に敏感なトークンとセマンティック特徴マップの関連
クロスアテンションメカニズムを通じて、位置に敏感なトークンと画像レベルのセマンティック特徴マップが関連付けられる。これは、情報融合の手法として広く知られており、RegionSpotにおいても効果的に使用されている。
2.3 損失関数
テキスト特徴を生成するために、カテゴリテキストとプロンプトテンプレートを使用し、ドット積演算を行う。これにより、セマンティックトークンとテキスト特徴のマッチングスコアを計算し、焦点損失を用いて監督可能な形で最適化を行う。
2.4 ゼロショット推論
RegionSpotは、SAMからの人間が注釈を付けたボックスや外部の領域提案生成器を利用して、ゼロショットオブジェクト検出を実現する。この柔軟なプロンプト機能により、地域認識が可能となる。
3. 実験
3.1 トレーニングデータ
多様なデータセットを組み合わせて、約300万枚の画像を使用してモデルをトレーニングした。使用したデータセットには、Objects 365 (O365)、OpenImages (OI)、およびV3Det (V3D)が含まれる。これにより、モデルはさまざまなラベル空間を持つデータを学習することができた。
3.2 ベンチマーク設定
評価には、1203カテゴリと19809枚の画像が含まれるLVISデータセットを用い、Mean Average Precision (mAP)を評価指標とした。COCOデータセットは、一般的なカテゴリのみを含むため、オープンワールド設定での一般化能力を十分に評価できないため、優先されなかった。
3.3 実装の詳細
RegionSpotは、AdamWオプティマイザーを使用してトレーニングされ、初期学習率は2.5×10^-5とした。すべてのモデルは8つのGPUでバッチサイズ16でトレーニングされ、450Kイテレーションで学習を行った。
3.4 結果
実験結果により、RegionSpotはGLIP-Lに対してmAPで2.9の向上を示し、特に複雑で稀なカテゴリにおいては13.1のパフォーマンス向上を達成した。
4. 結論
本研究では、事前学習されたビジョンおよびビジョン・ランゲージ基盤モデルを活用し、ゼロショットの地域認識を実現する新たなフレームワーク「RegionSpot」を提案した。両基盤モデルを固定し、知識統合モジュールに最適化を集中させることで、トレーニングオーバーヘッドを最小限に抑えつつ、効率的なトレーニングを実現した。RegionSpotは、既存の手法と比較して、少ない学習可能なパラメータで優れたパフォーマンスを発揮した。