目次
A Survey on Knowledge Distillation of Large Language Models
この論文は、大規模言語モデル(LLM)の知識蒸留に関する包括的な調査であり、プロプライエタリモデルからオープンソースモデルへの能力移転や、データ拡張を利用した性能向上の手法を探求しています。
この論文の特徴は、知識蒸留とデータ拡張を組み合わせることで、オープンソースの大規模言語モデルがプロプライエタリモデルの高度な性能を効率的に模倣し、特定のスキルやドメインに適応できるようにする新たな枠組みを提案している点です。
論文:https://arxiv.org/abs/2402.13116
リポジトリ:https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
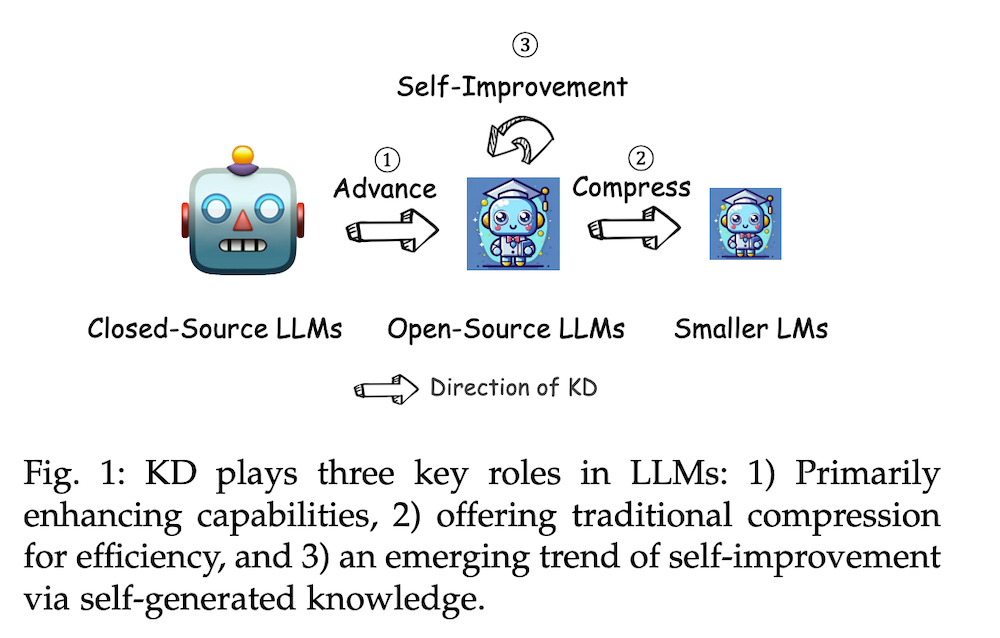
本論文では、大規模言語モデル(LLM)の時代における知識蒸留(KD)の役割について包括的な調査を行います。知識蒸留は、GPT-4などの先進的なプロプライエタリLLMから、LLaMAやMistralなどのオープンソースのモデルに高度な能力を移行するための重要な手法として浮上しています。また、オープンソースのLLMが発展する中で、KDはこれらのモデルの圧縮と自己改善を促進する上でも重要な役割を果たします。
本論文は、LLMの分野におけるKDの重要性を強調し、小型モデルへの高度な知識の伝達やモデル圧縮、自己改善におけるその有用性を紹介します。調査は、アルゴリズム、スキル、垂直化という三つの基盤となる柱に基づいて構成され、KDメカニズム、特定の認知能力の向上、さまざまな分野における実用的な影響について詳細に検討します。特に、データ拡張(DA)とKDの相互作用を考察し、DAがKDの枠組み内でLLMの性能を向上させる強力なパラダイムとしてどのように機能するかを示します。DAを活用して文脈に富み、スキルに特化したトレーニングデータを生成することで、KDは従来の境界を超え、オープンソースのモデルがプロプライエタリなモデルに特有の文脈適応力、倫理的整合性、深い意味的洞察を近似できるようにします。
この研究は、研究者や実務者に対して、知識蒸留の現在の手法についての詳細な概要を提供し、今後の研究の方向性を提案することを目指しています。プロプライエタリなLLMとオープンソースのLLMのギャップを埋めることで、この調査は、よりアクセス可能で効率的かつ強力なAIソリューションの可能性を強調しています。最も重要なのは、LLMのKDの倫理的かつ合法的な適用を確保するために、LLMの使用に関する法的条件に従うことを強く支持します。
知識蒸留の大規模言語モデルに関する調査
1. はじめに
本章では、知識蒸留(KD)の重要性と背景について述べています。大規模言語モデル(LLM)、特にプロプライエタリモデル(例:GPT-4やGemini)からオープンソースモデル(例:LLaMA、Mistral)への知識移転が求められています。これにより、コスト削減やモデルの圧縮が可能になり、自己改善が促進されます。
2. 知識蒸留の概要
2.1 伝統的手法との比較
知識蒸留は、教師モデルから学生モデルへ知識を移転するプロセスです。従来の手法は特定のタスクに特化していましたが、LLMの導入により、知識の引き出しと移転が新たな焦点となっています。
2.2 データ拡張(DA)との関係
データ拡張は、特定のスキルやドメインに特化したトレーニングデータを生成し、KDの効果を高める重要な手法です。これにより、オープンソースモデルはプロプライエタリモデルに近づくことが可能になります。
3. 知識蒸留アルゴリズム
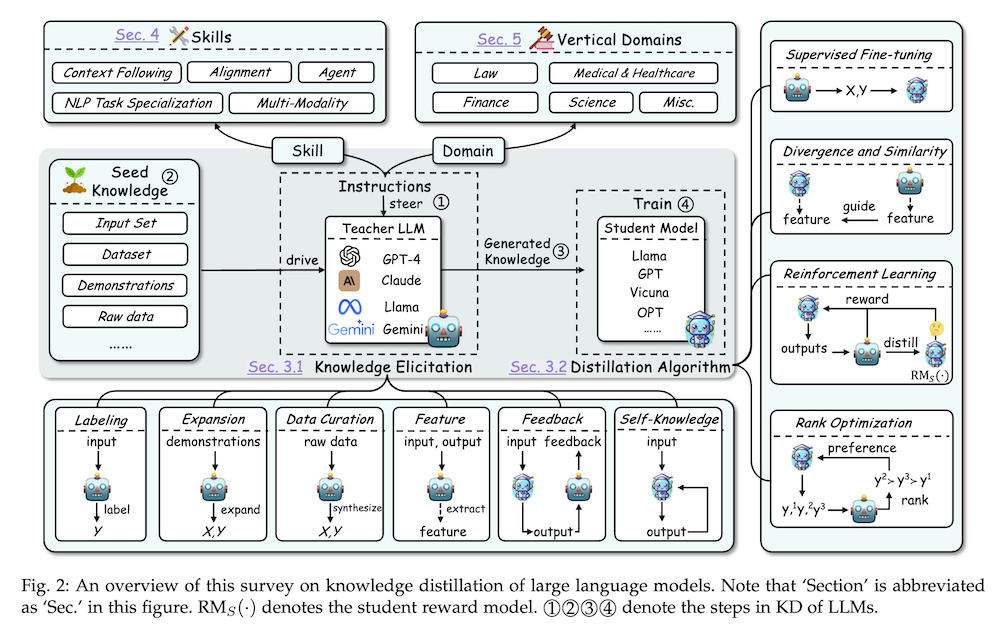
3.1 知識の引き出し
- ラベリング: 教師モデルを使用した出力の生成。
- 拡張: 教師モデルに基づいて新しいデータを生成。
- データキュレーション: メタ情報を活用して高品質データを生成。
3.2 知識の蒸留
- 監視型ファインチューニング: 教師モデルの出力を基に学生モデルを最適化。
- ダイバージェンスと類似性: 確率分布の差異を最小化。
- 強化学習: 教師からのフィードバックを活用した最適化。
4. スキル蒸留
4.1 コンテキストフォローイング
学生モデルが複雑なコンテキストを理解し応答する能力を移転します。指示に従う能力やマルチターン対話に関する知識が含まれます。
4.2 アライメント
学生モデルが教師モデルの応答と一致する能力を強化します。思考パターンや人間の好みを模倣する手法が重要です。
5. ドメイン特化型垂直蒸留
特定の分野(法律、医療、金融、科学)におけるKDの応用について探ります。これにより、専門的な知識を持ったモデルの開発が可能となります。
6. オープンな問題
今後の研究では、KDの効率化や信頼性向上、自己アラインメントの実現が求められます。特に、蒸留コストの削減や多教師蒸留に関する課題が重要です。
7. 結論と議論
本調査を通じて、LLMsにおけるKDの技術と応用、課題について明らかにしました。KDは、先進的なLLMの能力へのアクセスを広げ、効率的で責任あるAIの発展に寄与する重要な手法です。今後の研究は、KDの効率性、透明性、倫理性を重視しつつ、その発展を促進する必要があります。