目次
AutoPrep: Natural Language Question-Aware Data Preparation with a Multi-Agent Framework
この論文は、自然言語の質問に基づいたデータ準備を行うためのマルチエージェントフレームワーク「AutoPrep」を提案しており、特に表形式データに対する質問応答を効率化する手法について述べています。
AutoPrepは、異なるデータ準備タスクに特化した複数のエージェントを活用することで、自然言語質問に対してより精度の高い応答を実現する新しいマルチエージェントフレームワークを提案している点が特徴です。
論文:https://arxiv.org/abs/2412.10422
リポジトリ:https://github.com/fmh1art/AutoPrep
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
この論文では、自然言語(NL)質問に対するテーブルの回答、いわゆるタブラー質問応答(TQA)が重要である理由について述べています。これは、ユーザーが構造化データから迅速かつ効率的に意味のある洞察を抽出できるようにし、人間の言語と機械可読形式とのギャップを効果的に埋めるものです。多くのテーブルはウェブソースや現実のシナリオから派生しており、正確な応答を確保するためには、綿密なデータ準備(データ準備)が必要です。
しかし、このようなテーブルをNL質問に対して準備することは、従来のデータ準備を超えた新しい要件をもたらします。この質問認識データ準備は、特定の質問に合わせたカラムの拡張やフィルタリング、質問認識の値の正規化や変換などの特定のタスクを含み、この文脈でのより微妙なアプローチの必要性を際立たせています。これらのタスクはそれぞれ独自であるため、単一のモデル(またはエージェント)がすべてのシナリオで効果的に機能することは難しいです。
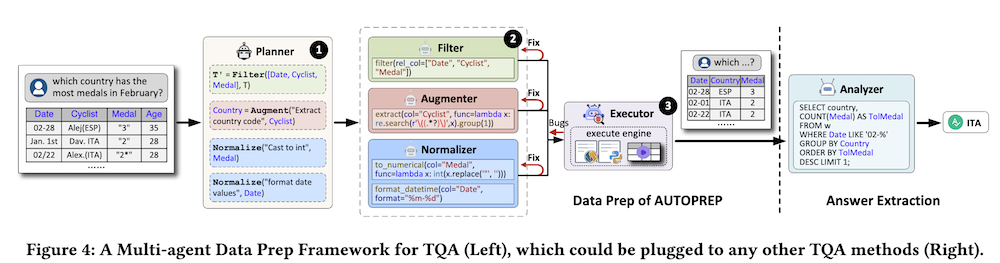
本論文では、複数のエージェントの強みを活かす大規模言語モデル(LLM)ベースのマルチエージェントフレームワークであるAutoPrepを提案します。AutoPrepは、特定のデータ準備に特化したエージェントを利用することで、より正確で文脈に関連した応答を保証します。テーブルに対するNL質問が与えられた場合、AutoPrepは次の三つの主要コンポーネントを通じてデータ準備を行います。プランナー:論理的な計画を立て、高レベルの操作のシーケンスを概説します。プログラマー:この論理的な計画を物理的な計画に変換し、対応する低レベルのコードを生成します。エグゼキューター:生成されたコードを実行してテーブルを処理します。このマルチエージェントフレームワークをサポートするために、高レベルの操作提案のための新しいChain-of-Clauses推論メカニズムと、低レベルのコード生成のためのツール強化手法を設計しました。
AutoPrep: 自然言語質問に基づくデータ準備のためのマルチエージェントフレームワーク
1. 概要
本論文では、タブラー質問応答(Tabular Question Answering: TQA)における自然言語質問に対するデータ準備の重要性を強調し、特にウェブソースや現実世界から得られるテーブルに対して正確な応答を保証するための新しいアプローチ「AutoPrep」を提案しています。従来のデータ準備手法では対応が難しい新たな要件が存在し、質問に応じたデータ準備が求められます。
2. 問題設定
自然言語質問に基づくデータ準備は、特定の質問に合わせたカラムの拡張やフィルタリング、値の正規化や変換など、従来の手法では対応しきれない多様なタスクを含みます。これにより、より精緻なアプローチが必要とされています。
3. 提案手法: AutoPrepフレームワーク
AutoPrepは、複数のエージェントから構成されるマルチエージェントフレームワークであり、各エージェントが特定のデータ準備タスクに特化しています。これにより、より正確で文脈に即した応答を確保することができます。
3.1 AutoPrepの構成要素
AutoPrepは、以下の三つの主要コンポーネントから成り立っています。
- プランナー(Planner): 論理的な計画を決定し、高レベルの操作のシーケンスを概説します。
- プログラマー(Programmer): 論理的な計画を物理的な計画に翻訳し、対応する低レベルのコードを生成します。
- エグゼキューター(Executor): 生成されたコードを実行し、テーブルを処理します。
4. 実験と評価
著者は、AutoPrepの有効性を評価するために、さまざまなテーブルおよび自然言語質問を用いた実験を行いました。実験の結果、AutoPrepは従来の手法に比べ、質問意識のあるデータ準備において優れたパフォーマンスを示しました。具体的には、プランニングとコード生成の精度が向上し、最終的な回答の質も改善されました。
5. 結論および今後の展望
本研究は、自然言語質問に応じたデータ準備の新たなアプローチを示しました。今後は、さらに多様なタスクに対応できるよう、エージェントの専門性を拡張し、フレームワークの汎用性を高めることが期待されます。