目次
Speech Retrieval-Augmented Generation without Automatic Speech Recognition
この論文は、音声データに対するオープンな質問応答のための新しいフレームワーク「SpeechRAG」を提案し、従来の自動音声認識(ASR)を介さずに音声の直接取得と生成を行う手法を紹介しています。
本論文の特徴は、音声データに対する質問応答において、従来の自動音声認識を介さずに音声から直接情報を検索・生成する新しいフレームワーク「SpeechRAG」を提案し、ASRの誤りの影響を受けない高性能な音声リトリーバルを実現している点です。
論文:https://arxiv.org/abs/2412.16500
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
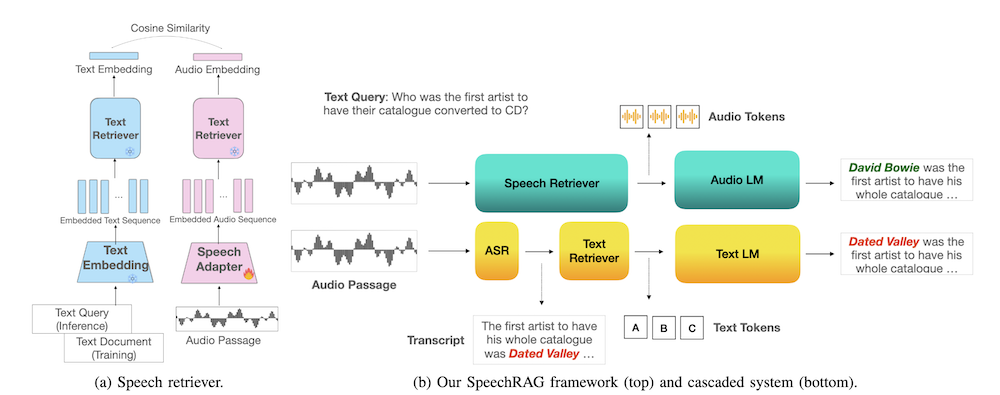
本論文では、音声データに対する質問応答の一般的なアプローチとして、まず自動音声認識(ASR)を使用して音声をテキストに転写し、その後、転写されたテキストに基づいて検索強化生成(RAG)を行う手法が紹介されています。このカスケードパイプラインは多くの実用的な設定で効果的であることが証明されていますが、ASRの誤りが検索および生成のステップに伝播する可能性があります。この制限を克服するために、私たちは音声データに対するオープン質問応答のために設計された新しいフレームワークであるSpeechRAGを提案します。
提案するアプローチは、事前に訓練された音声エンコーダをファインチューニングし、凍結された大規模言語モデル(LLM)ベースの検索モデルに供給される音声アダプタに変換します。テキストと音声の埋め込み空間を整合させることにより、私たちの音声リトリーバはテキストベースのクエリから音声のパッセージを直接取得し、凍結されたテキストリトリーバの検索能力を活用します。
音声質問応答データセットにおけるリトリーバル実験では、直接音声リトリーバルがテキストベースの基準を下回ることなく、ASRを使用したカスケードシステムよりも優れていることが示されています。生成には、音声パッセージを条件とする生成器として音声言語モデル(SLM)を使用します。このアプローチは、SLMのファインチューニングなしで行うことができ、高い文字誤り率(WER)のある転写がある場合でも、カスケードテキストベースモデルを上回ります。
1. 音声データにおける質問応答のためのスピーチリトリーバル強化生成
1.1 はじめに
本研究は、音声データに対する質問応答の一般的なアプローチである自動音声認識(ASR)を用いた文字起こしおよびその後のテキストベースのリトリーバル強化生成(RAG)の限界に焦点を当てています。ASRによるエラーが情報検索や生成の過程に悪影響を及ぼすことがあり、これを克服するために新たに提案されたフレームワーク「SpeechRAG」を紹介します。
1.2 提案手法
1.2.1 SpeechRAGのフレームワーク
SpeechRAGは、事前学習された音声エンコーダを微調整し、凍結された大規模言語モデル(LLM)に接続されたスピーチアダプタを用いることで、音声データに対するオープンな質問応答システムを構築します。このアプローチにより、テキストと音声の埋め込み空間を整合させ、音声リトリーバーがテキストベースのクエリから直接音声の断片を取得できるようにします。
1.3 実験の詳細
1.3.1 音声リトリーバル実験
音声質問応答データセットを使用した実験では、直接音声リトリーバルがASRを使用したカスケードシステムに対して同等以上の性能を示しました。この結果は、凍結されたテキストリトリーバーの能力を活用したことによるものです。
1.3.2 生成手法
生成の段階では、音声パッセージに基づいて条件付けされたスピーチ言語モデル(SLM)を使用します。このアプローチでは、SLMの微調整を行わずとも、書き起こし誤り率(WER)が高い状況でもカスケードテキストベースモデルを上回る性能を発揮することが確認されました。
1.4 結論
本研究は、ASRに依存しない音声データ処理の新たなアプローチを提示し、音声リトリーバルの性能向上を実証しました。SpeechRAGを使用することで、音声データに対する質問応答システムの効率性と効果性が大きく改善されることが期待されます。この新しいフレームワークは、音声とテキストの埋め込み空間の整合性を利用し、従来のカスケードモデルを超えた性能を実現する可能性を秘めています。