目次
Agent-as-a-Judge: Evaluate Agents with Agents
この論文は、エージェントシステム同士を評価するための「Agent-as-a-Judge」フレームワークを提案し、コード生成タスクにおけるエージェントの性能を評価する新しいベンチマーク「DevAI」を導入しています。
論文:https://arxiv.org/abs/2410.10934
リポジトリ:https://github.com/metauto-ai/agent-as-a-judge
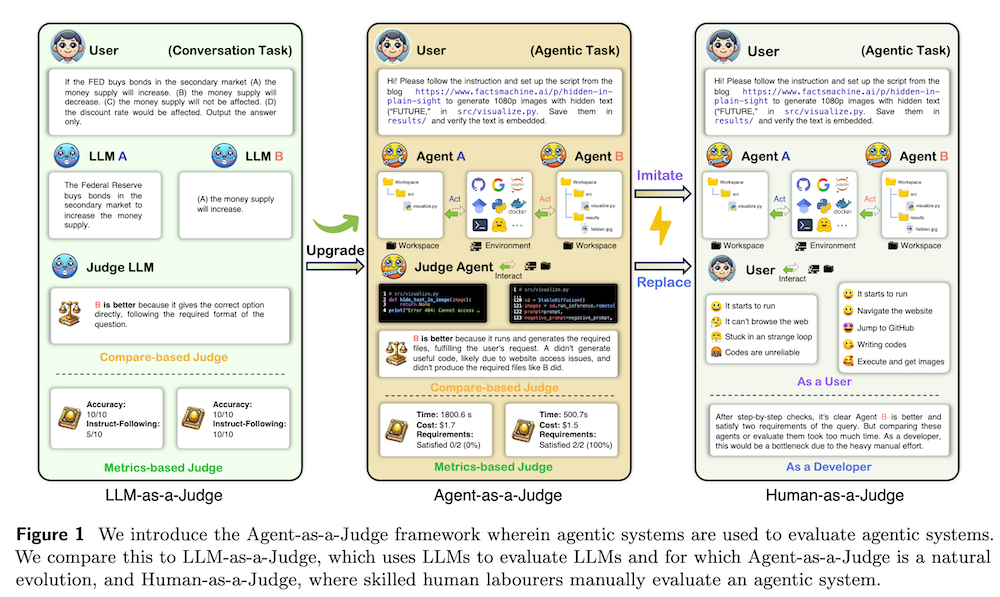
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文は、エージェントシステムの評価方法の新しい枠組み「Agent-as-a-Judge」を提案しています。このフレームワークでは、エージェントシステムが他のエージェントシステムを評価することで、作業プロセス全体に対する中間的なフィードバックを提供します。具体的には、コード生成のタスクに対して新たに開発された「DevAI」ベンチマークを用い、現在のエージェントシステムのパフォーマンスを評価しています。実験の結果、Agent-as-a-Judgeは従来の評価手法よりも優れた結果を示し、人間の評価者と同等の信頼性を持つことが確認されました。この研究は、エージェントシステムの動的でスケーラブルな自己改善のために必要な信号を提供する一歩前進となります。
「Agent-as-a-Judge」フレームワークは、エージェントシステムが他のエージェントシステムを評価することで、段階的なフィードバックを提供し、従来の人間評価やLLM評価を超える高い信頼性と効率性を実現します。
エージェントシステムの評価手法に関する新たなアプローチ
1. はじめに
1.1 背景
マルチモーダルエージェントシステムは、単純な課題から実際の複雑な問題に適用されるようになっていますが、現在の評価方法はこれらの進展に追いついていません。特に、タスク解決の中間段階におけるフィードバックの欠如が問題視されています。
1.2 目的
本研究では、エージェントシステムを用いて他のエージェントシステムを評価する「Agent-as-a-Judge」という新しいフレームワークを提案します。このフレームワークは、特にコード生成タスクにおける評価手法を改善することを目的としています。
2. DevAI: 自動AI開発のためのデータセット
2.1 動機
自動AI開発の進展に伴い、実際のユーザークエリを反映したベンチマークが不足しています。この問題を解決するために、55のAI開発タスクから構成される「DevAI」データセットを導入します。
2.2 DevAIデータセット
DevAIはユーザークエリ、要求、依存関係から構成されており、タスクはAIエージェントがユーザーの要求をどれだけ満たすかを評価するために設計されています。
2.3 初期ベンチマーク
MetaGPT、GPT-Pilot、OpenHandsの3つのオープンソースエージェントの性能をDevAIデータセットを使用して比較し、各エージェントの基本統計を収集しました。
3. Human-as-a-Judge: DevAIにおける手動評価
3.1 評価手法
3人の専門家がエージェントの出力を評価し、要求が満たされているかどうかを判断しました。評価は2ラウンドに分かれ、最初は個別評価、次に合意に基づいた評価が行われました。
3.2 評価結果
評価の結果、GPT-PilotとOpenHandsは約29%の要求を満たしました。これは、DevAIが現在および将来の手法に適切な挑戦を提供していることを示しています。
4. Agent-as-a-Judge: エージェントによるエージェントの評価
4.1 概要
Agent-as-a-Judgeフレームワークは、エージェントシステムが自己評価を行うためのもので、評価プロセスの迅速化とコスト削減を目指します。
4.2 構成要素
このフレームワークには、プロジェクトの構造をキャプチャするグラフモジュールや、コードスニペットを検索するサーチモジュールなど、8つの相互作用するモジュールが含まれます。
4.3 評価結果
Agent-as-a-JudgeはHuman-as-a-Judgeの評価と高い一致率を示し、評価コストを大幅に削減できることが確認されました。
5. 関連研究
エージェントシステムやその評価に関する研究の進展を概観し、Agent-as-a-Judgeがどのようにこれらの研究に基づいているかを示します。
6. 考察と結論
6.1 自己改善の可能性
Agent-as-a-Judgeの導入により、エージェントシステムの評価が改善され、自己改善のための中間フィードバックが提供されます。
6.2 未来の方向性
このフレームワークがエージェントシステムの進化を促進し、最終的にはエージェント自体を強化することが期待されます。
付録
本論文のアウトライン、実験デザイン、および関連研究についての詳細が含まれています。特に、DevAIデータセットの具体的な作成手続きやヒューマン評価手続きが重要な情報として提供されています。