目次
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
この論文は、LLM(大型言語モデル)ベースのエージェントに対する攻撃と防御を体系的に評価するための「エージェントセキュリティベンチ(ASB)」というフレームワークを提案し、さまざまな攻撃手法の効果と防御策の限界を示しています。
論文:https://arxiv.org/abs/2410.02644
リポジトリ:https://github.com/agiresearch/ASB
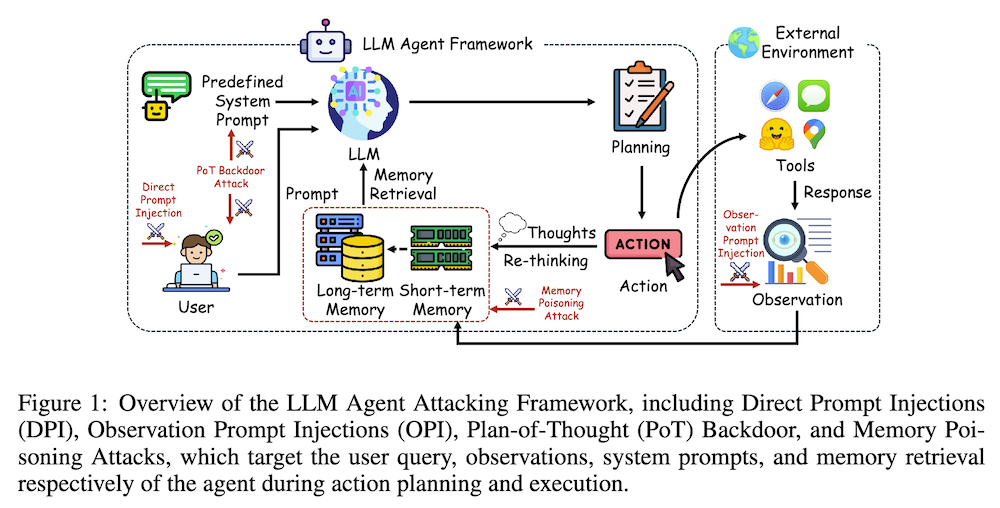
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文では、LLM(大規模言語モデル)ベースのエージェントに対する攻撃と防御の評価を行うための「エージェントセキュリティベンチ(ASB)」というフレームワークを提案しています。ASBは、10のシナリオ、10のエージェント、400以上のツール、23種類の攻撃/防御手法、8つの評価指標を含み、全体で9万件以上のテストケースを通じて、様々な攻撃の成功率や防御の有効性を評価しました。結果として、エージェントの運用の各段階において84.30%の攻撃成功率が示され、防御の効果は限られていることが明らかになりました。この研究は、LLMエージェントのセキュリティにおける重要な課題を浮き彫りにし、より強力な防御策の必要性を示しています。最終的に、エージェントのセキュリティを強化するための今後の研究の方向性が示されています。
この論文の特徴は、LLMエージェントに対する多様な攻撃手法を体系的に評価し、84.30%という高い攻撃成功率を示すことで、現行の防御策の脆弱性を明らかにし、エージェントセキュリティの向上に向けた具体的な課題を提起している点です。
LLMベースのエージェントにおける攻撃と防御の評価フレームワーク(ASB)
1. はじめに
大規模言語モデル(LLM)を基盤としたエージェントは、外部ツールやメモリメカニズムを活用して複雑なタスクを解決する力を持っていますが、同時にセキュリティの脆弱性も存在します。本論文では、これらのエージェントに対する攻撃と防御を体系的に評価するためのフレームワーク「エージェントセキュリティベンチ(ASB)」を提案します。このフレームワークは、10のシナリオ、23種類の攻撃/防御手法を含む包括的なもので、実験を通じてエージェントの脆弱性と防御策の限界を明らかにしました。
2. 関連研究
2.1 プロンプトインジェクション攻撃
この攻撃手法では、攻撃者が元の入力に特別な指示を加え、モデルの応答を操作することが可能です。ASBは、これらの攻撃を統合的に評価する新たなアプローチを採用しています。
2.2 メモリーポイズニング
メモリーポイズニングでは、悪意のあるデータをデータベースに注入し、エージェントがそのデータを参照することで意図しない行動を引き起こさせます。従来の研究では、この影響は十分に評価されていませんでした。
2.3 バックドア攻撃
バックドア攻撃は、LLMに特定のトリガーを埋め込むことで意図しない出力を生成させる手法です。
3. 脅威モデルと基本概念
LLMエージェントは、ユーザーのクエリに応じて情報を取得し、外部ツールを使用してアクションを実行します。攻撃者は、プロンプトインジェクションや観察プロンプトインジェクションなどを通じて、エージェントの意思決定を妨害します。
4. 攻撃と防御の形式化
4.1 プロンプトインジェクション攻撃
攻撃は、直接プロンプト操作(DPI)と観察プロンプト操作(OPI)に分けられます。DPIはユーザープロンプトを通じてエージェントを操作し、OPIはその実行過程で得られたデータに悪意のある指示を注入します。
4.2 メモリーポイズニング攻撃
この攻撃では、エージェントに「毒された」データベースを提供し、意図しないタスクを実行させます。
4.3 Plan-of-Thought(PoT)バックドア攻撃
PoTバックドア攻撃では、特定の条件下で悪意のある行動を引き起こすよう隠された指示を埋め込みます。
4.4 混合攻撃
複数の攻撃手法を組み合わせることで、エージェントの異なる弱点を同時に狙う方法です。
4.5 防御手法
各攻撃に対する防御策を形式化し、それぞれの効果を評価します。
5. ASBにおける評価結果
ASBは、攻撃成功率(ASR)や拒否率(RR)などのメトリクスを用いて、様々な攻撃手法と防御手法の効果を評価しました。実験の結果、攻撃成功率は平均84.30%であり、現行の防御策には改善の余地があることが示されました。
6. 結論と今後の展望
ASBは、LLMエージェントのセキュリティにおける重要な脆弱性を明らかにし、今後はより強力な防御策の開発や新たな攻撃シナリオの拡充が求められることを提起しています。
付録
- 攻撃と防御の詳細: 各手法の具体的な説明と実装例。
- ベンチマーク構築: ASBの構築プロセスや使用したケース生成手法について。
- 追加の実験設定: 使用したLLMや実験方法の詳細。