目次
Baichuan-Omni Technical Report
この論文は、画像、動画、音声、テキストを同時に処理できる初のオープンソースの7Bマルチモーダル大規模言語モデル「Baichuan-Omni」を紹介し、そのトレーニング手法や性能評価について詳述しています。
論文:https://arxiv.org/abs/2410.08565
リポジトリ:https://github.com/westlake-baichuan-mllm/bc-omni
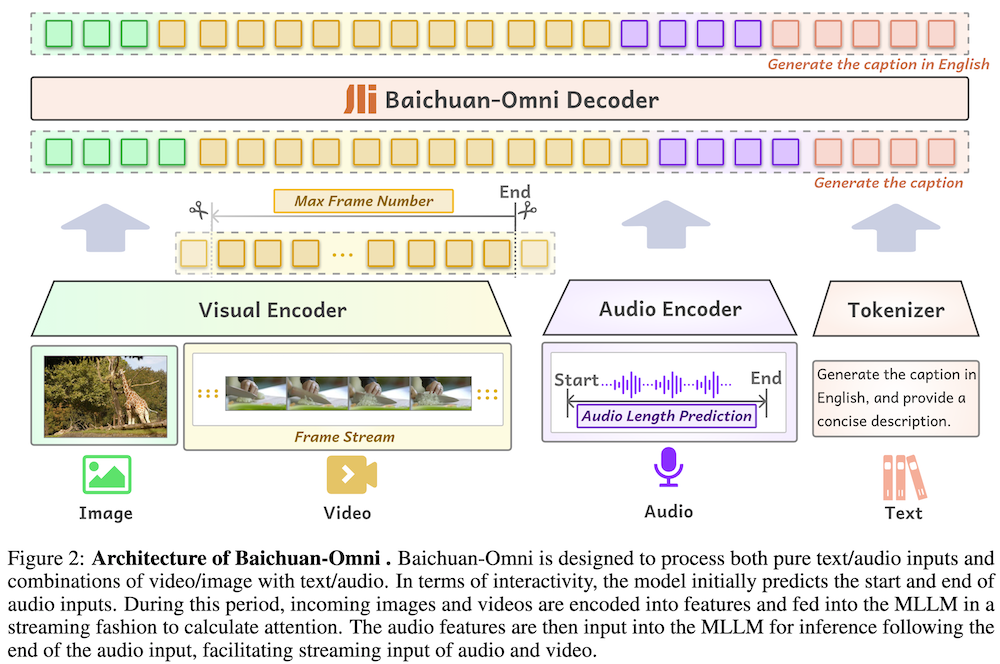
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文では、画像、動画、音声、テキストの複数のモダリティを同時に処理できる初のオープンソースの7Bマルチモーダル大規模言語モデル(MLLM)「Baichuan-Omni」を紹介しています。Baichuan-Omniは、高度なマルチモーダルインタラクティブ体験を提供し、多様なベンチマークで優れた性能を示しています。モデルは、マルチモーダルアライメントとマルチタスク微調整の2段階の訓練スキームを採用しており、視覚データや音声データを効果的に処理できます。この研究は、オープンソースコミュニティにおけるマルチモーダル理解とリアルタイムインタラクションの発展に寄与することを目的としています。最終的に、Baichuan-Omniは、さまざまな実用的応用において人間とコンピュータの相互作用を新たな次元に引き上げることを目指しています。
Baichuan-Omniは、7Bパラメータのオープンソースマルチモーダルモデルであり、音声、画像、動画、テキストを統合的に処理できる能力を持ち、多様なデータセットを用いてマルチモーダルアライメントとタスク特化型微調整を行い、リアルタイムインタラクションを実現しています。
Baichuan-Omniに関する解説
1. はじめに
1.1 背景
近年、人工知能の進展に伴い、大規模言語モデル(LLMs)やマルチモーダル大規模言語モデル(MLLMs)の発展が顕著に見られます。これにより、機械がテキストだけでなく、画像、音声、動画を理解し、相互作用する能力が向上しています。本論文では、新たに提案されたオープンソースのMLLM「Baichuan-Omni」を紹介します。
1.2 目的
Baichuan-Omniは、7Bのパラメータを持ち、画像、動画、音声、テキストを同時に処理する能力を有しています。このモデルは、マルチモーダルな理解とリアルタイムインタラクションを促進するための効果的なトレーニングスキームを提案しています。
2. 関連研究
2.1 MLLMの進展
最近のLLMsの進展により、AIはテキストを超えて画像や音声、動画にまで理解を拡張できるようになりました。特に、視覚と言語の統合が進んでおり、従来のオープンソースモデルにはその能力において大きなギャップが存在します。
3. トレーニング
3.1 高品質マルチモーダルデータ
Baichuan-Omniのトレーニングには、様々なソースから集めた高品質のマルチモーダルデータが使用されています。
- 画像データ: キャプション、インタリーブ画像-テキスト、OCRデータなどから構成され、オープンソースデータと合成データを利用しています。
- 動画データ: アクション認識や質問応答データを基に収集され、最大48フレームの処理を行います。
- 音声データ: 多様な言語やアクセントの音声を含むデータが集められ、ASRシステムを用いて品質向上が図られています。
3.2 マルチモーダルアライメントの事前学習
各モダリティのアライメントを強化するための事前学習が行われています。
- 画像-言語ブランチ: Siglip-384pxを用いて画像キャプション生成タスクを通じて初期アライメントを確立します。
- 動画-言語ブランチ: 動画フレームをサンプリングし、言語とのアライメントを強化します。
- 音声-言語ブランチ: Whisper-large-v3モデルを使用し、音声信号を自然言語空間にマッピングします。
3.3 マルチモーダル監視ファインチューニング
600,000以上のデータペアを用いて、多様なタスクに対するモデルの能力を強化するファインチューニングが実施されました。
4. 実験
4.1 言語性能
MMLU、CMMLU、AGIEval、C-Evalなどのベンチマークで性能を評価し、特に中国語のベンチマークで優れた結果を示しました。
4.2 画像理解
13のビジョン-言語ベンチマークでの評価を行い、優れたパフォーマンスを発揮しました。
4.3 動画理解
一般的な動画理解タスクおよびオープンエンドな動画質問応答において、Baichuan-Omniの能力を確認しました。
4.4 音声理解
音声認識(ASR)や音声からテキストへの翻訳(S2TT)に関する評価を行い、高い性能を示しました。
4.5 アブレーションスタディ
各モダリティにおける異なる要因がモデルのパフォーマンスに与える影響を調査しました。
5. 結論
Baichuan-Omniは、マルチモーダルな理解を実現するための重要なステップを示しており、画像、動画、音声、テキストを統合した能力において先進的な成果を上げています。今後の研究では、さらなる性能向上が期待されます。