目次
Differential Transformer
この論文は、注意メカニズムのノイズをキャンセルし、関連する文脈への注意を強化する「DIFF Transformer」という新しいアーキテクチャを提案し、言語モデルの性能向上を実証しています。
論文:https://arxiv.org/abs/2410.05258
リポジトリ:https://aka.ms/Diff-Transformer
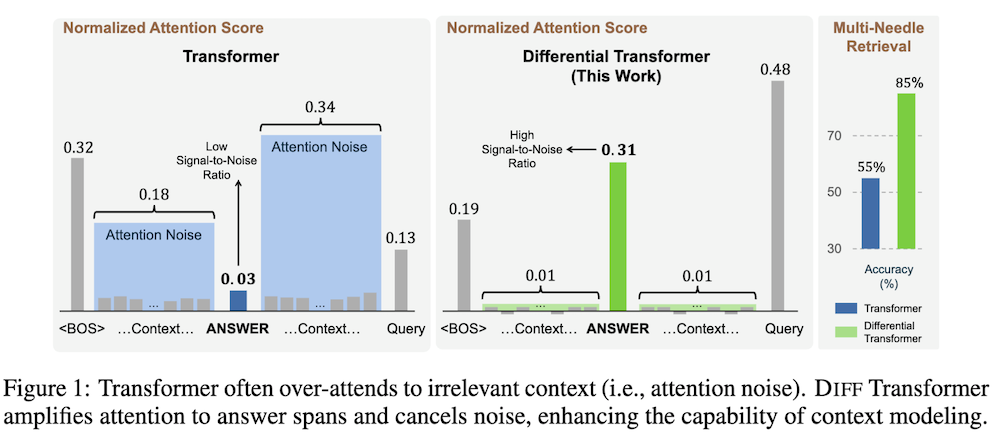
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文では、DIFF Transformerという新しいアーキテクチャを提案しています。このモデルは、関連する文脈への注意を強化し、無関係な情報によるノイズをキャンセルすることを目的としています。具体的には、二つの異なるソフトマックス注意マップの差を計算する差分注意メカニズムを導入しています。実験結果から、DIFF Transformerは、長い文脈のモデリングや重要情報の取得、幻覚の軽減、文脈内学習においてTransformerを上回る性能を示しました。これにより、DIFF Transformerは大規模な言語モデルを進展させるための効果的かつ有望な基盤アーキテクチャとして位置づけられています。
DIFF Transformerは、注意スコアの計算に差分を利用することで、無関係な情報の影響を大幅に低減し、重要な情報の取得精度を向上させる新しいアプローチを提供します。
以下は、Differential Transformerに関する論文の各章ごとの内容をまとめた解説です。
1. Differential Transformerの概要
1.1 はじめに
この章では、従来のTransformerモデルが直面している「注意ノイズ」問題について説明しています。注意ノイズは、無関係なコンテキストに注意を払うことで重要な情報が埋もれてしまう現象です。これに対し、DIFF Transformerは、注意スコアを改善し、重要な情報を強調するアプローチを提案しています。
2. Differential Transformerの構造
2.1 差分注意メカニズム
DIFF Transformerの中心的なメカニズムは、クエリ、キー、バリューのベクトルを二つのグループに分け、それぞれに対して異なるソフトマックス関数を用いて注意スコアを計算することです。この方法により、無関係なノイズを打ち消し、重要な情報に対する注意を増幅します。
2.2 マルチヘッド差分注意
DIFF Transformerはマルチヘッド注意を採用しており、各ヘッドが異なるプロジェクション行列を使用します。スカラーλは同一層内で共有され、各ヘッドの出力を正規化して最終的な結果を得ます。
3. 実験
3.1 言語モデリング評価
DIFF Transformerの性能は、3Bサイズのモデルを1Tトークンで訓練し、従来のTransformerモデルと比較して評価されました。結果として、DIFF Transformerはより優れた性能を示しました。
3.2 スケーラビリティ
モデルサイズや訓練トークン数を増やす際の性能も評価され、DIFF Transformerは約65%少ないパラメータまたはトークンで同等の性能を達成できることが確認されました。
3.3 長文コンテキスト評価
64Kのコンテキスト長を持つモデルを評価し、DIFF Transformerが長文コンテキストを効果的に活用できることが示されました。
3.4 重要情報の抽出
特に深い位置にある重要な情報の取得能力を評価するための「針の山の中の針」テストでは、DIFF Transformerが優れた精度を示しました。
3.5 インコンテキスト学習
多ショットインコンテキスト学習において、DIFF Transformerは一貫して高い精度を示し、サンプルの順序変化に対するロバスト性も確認されました。
3.6 コンテキストの幻覚評価
テキスト要約と質問応答におけるコンテキストの幻覚を評価し、DIFF Transformerは正確な出力を生成する能力が高いことを示しました。
3.7 活性化アウトライヤー分析
DIFF Transformerは、活性化のアウトライヤーを削減し、モデルの量子化の可能性を広げることが示されました。
3.8 アブレーションスタディ
DIFF Transformerの設計選択肢の影響を評価し、差分注意メカニズムがパフォーマンスの改善に寄与していることが確認されました。
4. 結論
DIFF Transformerは、関連するコンテキストへの注意を増幅し、ノイズをキャンセルすることで、従来のTransformerよりも優れた性能を発揮します。特に情報取得、長文コンテキストのモデリング、幻覚の軽減、インコンテキスト学習の強化などにおいて、DIFF Transformerは大規模言語モデルにとって有望な基盤アーキテクチャであることが示されました。
付録
A. 差分注意の実装
差分注意メカニズムの擬似コードと、従来のソフトマックス注意との比較を示しています。
B. 言語モデリング評価
350Bトークンで訓練した3Bサイズの言語モデルの結果を報告しています。
C. ハイパーパラメータ
DIFF Transformer-3Bモデルの詳細なハイパーパラメータを提供しています。
D. スケーラビリティに関するハイパーパラメータ
異なるモデルサイズのDIFF Transformerにおけるハイパーパラメータを報告しています。
E. インコンテキスト学習のロバスト性
DIFF TransformerとTransformerのロバスト性を評価した結果を示しています。
F. DIFF Transformerの勾配フロー
DIFF注意における勾配フローが従来のソフトマックス注意と同様であることを示し、トレーニングの安定性を確保するための詳細な理論的背景を提供しています。
このように、DIFF Transformerは従来のTransformerの課題を克服し、より効率的な情報処理を実現するための有力なアプローチを提供しています。