目次
Small Language Models: Survey, Measurements, and Insights
この論文は、小規模言語モデル(SLM)の技術革新、能力、トレーニングコストを包括的に調査し、特にデバイス上での実行における効率性を評価したものです。
論文:https://arxiv.org/abs/2409.15790
リポジトリ:https://github.com/UbiquitousLearning/SLM_Survey
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文は、小型言語モデル(SLM)に関する包括的な調査を行い、59の最先端オープンソースSLMの技術革新をアーキテクチャ、トレーニングデータセット、トレーニングアルゴリズムの3つの軸で分析しています。また、一般的な推論能力や、数学、コーディングにおける性能を評価し、デバイス上での実行コストをベンチマークして、SLMの研究の進展を図るための貴重な洞察を提供しています。具体的には、SLMは小型デバイスでの利用を目指し、デモクラティゼーションを実現することが期待されています。最近のSLMは、品質の高いトレーニングデータセットを使用することで性能を向上させており、今後の研究においてもその重要性が増すと考えられています。
この論文の特徴は、高品質なトレーニングデータセットの使用が小型言語モデル(SLM)の性能向上に寄与し、その結果としてSLMが大規模モデルに近づく進展を示している点です。
以下は、提供された情報を基にした論文の解説記事の章ごとのまとめです。
1. 小型言語モデル(SLM)の調査、測定、および洞察
1.1 はじめに
本章では、小型言語モデル(SLM)の進化とその重要性について述べています。SLMは、デスクトップやスマートフォン、ウェアラブルデバイスなど、リソースが限られた環境での効率的な利用を目指しています。SLMの目標は、機械知能をより多くの人々が日常的に利用できるようにすることです。
1.2 SLMの重要性
SLMは、学術界では大規模言語モデル(LLM)に比べて注目度が低く、文献や実行コストに関する研究が不足しています。しかし、SLMは実用的なタスクを効率的に処理する能力を持ち、商用デバイスで広く利用されています。
1.3 調査の目的
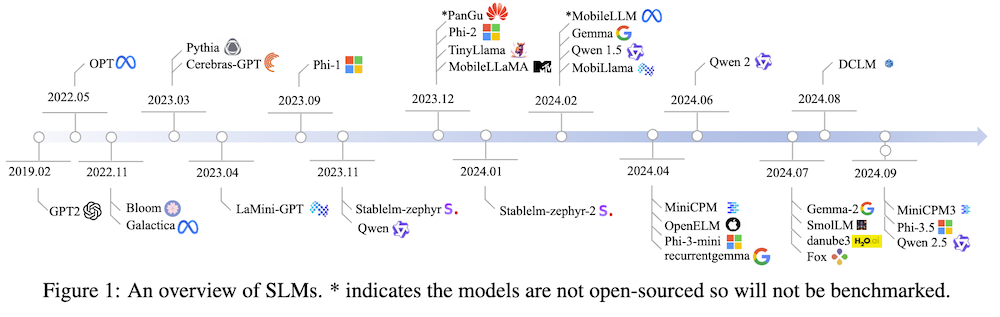
本研究は、100Mから5Bパラメータを持つトランスフォーマーベースのデコーダ専用モデルに焦点を当て、59の最先端オープンソースSLMを調査し、アーキテクチャ、トレーニングデータセット、トレーニングアルゴリズムにわたる技術革新を分析します。
2. SLMのアーキテクチャ、データセット、およびトレーニング
2.1 SLMの概要
SLMはトランスフォーマーアーキテクチャを基盤としており、自己注意機構やフィードフォワードネットワークを使用しています。これにより、モデルは入力データの異なる部分に同時に焦点を当てることができます。
2.2 アーキテクチャの詳細
SLMの自己注意機構には、マルチヘッド注意(MHA)、マルチクエリ注意(MQA)、グループクエリ注意(GQA)などのバリエーションがあります。また、フィードフォワードネットワークには、標準FFNとゲート付きFFNの2タイプがあり、最近はゲート付きFFNが多く採用されています。
2.3 トレーニングデータセット
SLMのトレーニングには、12種類のオープンソースデータセットが使用されており、「The Pile」などが広く利用されています。データセットの質は、モデルの性能に大きな影響を与えるため、重要な要素となります。
2.4 トレーニングアルゴリズム
知識蒸留や二段階トレーニング戦略など、さまざまなトレーニング手法がSLMの性能向上に寄与しています。
3. SLMの能力
3.1 評価データセットとメトリクス
SLMの性能を評価するために、共通知識推論、問題解決、数学のタスクに関連する12のデータセットを使用しています。正確性が主要な評価指標です。
3.2 全体的な能力
SLMは2022年から2024年にかけて、さまざまなタスクで重要な性能向上を示しています。特に、共通知識推論や問題解決において顕著な成果を上げています。
3.3 インコンテキスト学習能力
SLMのインコンテキスト学習能力は、モデルのサイズが大きくなるほど強化される傾向があります。
4. SLMの実行時コスト
4.1 レイテンシの測定
SLMのレイテンシは、モデルのサイズやアーキテクチャによって変化し、推論の遅延はこれらの要因に依存します。
4.2 ハードウェアの影響
異なるデバイス(例:GPUとCPU)での性能を比較し、ハードウェアがSLMの実行コストに与える影響を解説しています。
4.3 メモリ使用量の分析
SLMのレイテンシとメモリ使用量の内訳を分析し、特にマトリックス-ベクトル乗算が実行時間の主要な要因であることが示されています。
5. 結論と今後の方向性
5.1 研究の総括
本研究の成果をまとめ、SLMの進化、トレーニング戦略、アーキテクチャの革新についての洞察を提供しています。
5.2 今後の研究の方向性
今後の研究においては、SLMのアーキテクチャとデバイスの共同設計、高品質な合成データセットの構築、持続的なオンデバイス学習の実現が重要なテーマとして挙げられています。