目次
A Survey on Large Language Models in Multimodal Recommender Systems
この論文は、大規模言語モデル(LLM)を用いたマルチモーダル推薦システムの最新の研究を包括的にレビューし、統合手法や評価指標、今後の研究方向を提案するものです。
この論文は、大規模言語モデル(LLMs)がマルチモーダル推薦システム(MRS)において意味的推論や動的入力処理を可能にし、特に冷スタート問題や異なるドメイン間での適応を支援する新しいプロンプト戦略やファインチューニング手法を提案する点が特徴的です。
論文:https://arxiv.org/abs/2505.09777

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
マルチモーダル推薦システム(MRS)は、テキスト、画像、構造化情報などの異種ユーザーデータとアイテムデータを統合して、推薦性能を向上させることを目的としています。大規模言語モデル(LLMs)の出現は、意味的推論、コンテキスト学習、動的入力処理を可能にすることでMRSに新たな機会をもたらします。従来の事前訓練済み言語モデル(PLMs)と比較して、LLMsはより高い柔軟性と一般化能力を提供しますが、スケーラビリティやモデルへのアクセスに関する課題も生じます。
この調査では、LLMsとMRSの交差点における最近の研究を包括的にレビューし、プロンプト戦略、ファインチューニング手法、データ適応技術に焦点を当てます。私たちは、統合パターンを特徴づけるための新しい分類法を提案し、関連する推薦分野からの移転可能な技術を特定し、評価指標やデータセットの概要を提供し、将来の方向性について指摘します。私たちの目的は、マルチモーダル推薦におけるLLMsの新たな役割を明確にし、この急速に進化する分野の今後の研究を支援することです。
1. 序論
マルチモーダル推薦システム(MRS)は、テキスト、画像、構造化情報などの異種ユーザーおよびアイテムデータを統合して推薦性能を向上させています。大規模言語モデル(LLM)の出現により、意味的推論、文脈内学習、動的入力処理を可能にする新たな機会が生まれました。以前の事前学習済み言語モデル(PLM)と比較して、LLMはより柔軟性と汎用性を提供しますが、スケーラビリティとモデルアクセシビリティに関する課題も生じています。本調査では、LLMとMRSの交差点における最近の研究を包括的にレビューし、プロンプト手法、微調整方法、データ適応技術に焦点を当てています。
1.1 調査戦略
この調査はLLM固有の能力—推論、プロンプティング、モダリティ適応—がMRSの設計をどのように形作るかに焦点を当てています。モダリティ固有のエンコーダーなどの伝統的な構造コンポーネントへの注目を意図的に減らし、テーブルデータや数値データなどの未探索のモダリティに注目します。また、シーケンシャル推薦や知識対応型推薦など、関連する推薦システムの分野からLLMベースの手法を含めることで、分析の関連性を広げています。
1.2 他のMRS調査との違い
以前のMRSに関する調査は通常、モダリティ固有のエンコーダーなどのアーキテクチャコンポーネントに焦点を当てたエンコーダー中心の分類法を採用しています。対照的に、本論文はLLMの変革的影響に焦点を当て、これは従来のエンコーダーパイプラインを超えて拡張します。LLMはプロンプトエンジニアリングを通じて柔軟な入力処理を可能にし、マルチモーダルサマリーや構造化フォーマット(JSON、テーブルテキストなど)上で直接操作します。
1.3 分類法
本調査では、マルチモーダル推薦システムにおけるLLMの統合に合わせた新しい分類法を導入しています。この分類法は次の主要カテゴリに分類されます:
- LLM手法(2.1-2.3節):プロンプト技術、トレーニング戦略、データタイプ適応など
- MRS固有の技術(3.1-3.3節):分離、アライメント、融合など
- 主要なトレンドと将来の方向性(4節):この分野における新興パターンと推薦パイプライン内でのLLMの進化する役割を統合
1.4 調査の貢献
本調査の貢献は以下の通りです:
- MRSにおけるLLMのための新しい分類フレームワークの提案
- ドメインの統合と境界拡張
- 現在のトレンドのマッピングとギャップの特定
- メトリクスとデータセットに関する拡張されたリソース
2. LLM手法
2022年末のChatGPTの登場はNLP分野における転換点となりました。GPT-3などのLLMが既に存在していたものの、強化学習による人間のフィードバック(RLHF)の統合により、推論と会話能力が大幅に向上し、人間の期待により一致するようになりました。この能力の飛躍的向上は、検索や公平性を考慮した推薦などのタスクに対してLLMを探求する研究者の関心を急速に集めました。
しかし、LLMの推薦システムへの統合には重要な制限も明らかになりました。これらのモデルは相当な計算リソースを必要とし、アクセスは多くの場合ブラックボックスの入出力APIに制限されています。さらに、LLM推論によって導入される遅延は、リアルタイムのユーザーエンゲージメントを必要とする推薦コンテキストでは問題になる可能性があります。
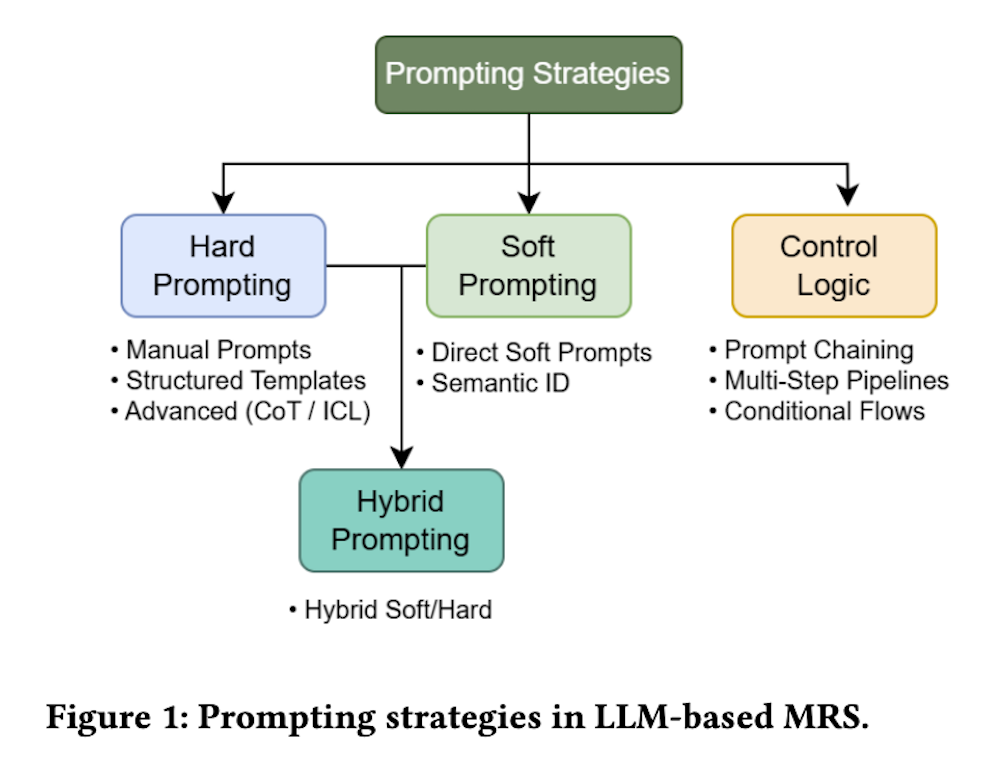
2.1 プロンプティング
マルチモーダル推薦におけるLLMの統合において、プロンプティングは中心的な戦略として浮上しています。プロンプティングを使用すると、モデル全体を再訓練することなく、様々なタスクにモデルを適応させることができ、特にコールドスタートおよびマルチタスクシナリオで有用です。微調整とは異なり、プロンプティングはLLMの内部重みを更新する必要がなく、ブラックボックスAPIや制限されたコンピューティング環境で作業する場合に軽量で解釈可能な代替手段になります。実世界のシナリオでは、大規模LLMの更新やホスティングが実現不可能な場合があり、コスト効果的な選択肢となります。
- 2.1.1 ハードプロンプティング: LLMの内部重みを更新せずに、固定入力テンプレートを使用して推論時のLLMの動作を導く手法。
- 2.1.2 ソフトプロンプティング: トレーニング可能な連続埋め込み(ソフトトークン)を入力に前置するパラメータ効率の良い適応技術。
- 2.1.3 ハイブリッド技術: 解釈可能性と適応性のバランスを取るために、固定ハードプロンプトと学習可能なソフトコンポーネントを組み合わせる方法。
- 2.1.4 制御ロジック: 複数のLLM呼び出しを調整するための構造化されたプログラム的戦略で、複雑なタスクを順次サブタスクに分解する手法。
2.2 トレーニング
推薦システム用のLLMのトレーニングまたは適応は、そのスケールと、ドメイン固有のマルチモーダル事前トレーニングの限られた利用可能性によって課題が生じます。ほとんどの研究は、フルのスクラッチからの事前トレーニングを避け、代わりにパラメータ効率の良い微調整、ブラックボックスプロンプティング、または事前トレーニングされたマルチモーダルLLM(MLLM)の活用を選択しています。推薦のために特別にスクラッチから事前トレーニングされた唯一のLLMはP5で、これはT5フレームワークを拡張し、評価、レビュー生成、シーケンシャル推薦、ゼロショット予測などの複数のタスクを統一されたテキストからテキストへの形式に変換します。
- 2.2.1 パラメータ適応: LLMのパラメータのサブセットまたは外部の補完ネットワークを変更して、ダウンストリームの推薦タスクに特化させる戦略。
- 2.2.2 ゼロチューニング使用法: LLMまたはモダリティエンコーダを凍結状態で使用し、固定表現を抽出したり、ブラックボックスLLMとプロンプトを介して対話する手法。
- 2.2.3 事前訓練されたMLLM: テキスト、視覚的、構造化データを共同で処理するためのマルチモーダル言語モデルで、強力なゼロショットと少数ショット一般化を提供。
- 2.2.4 エージェント: LLMが推論、ユーザーのシミュレーション、または環境との対話が可能な自律エージェントとしてインスタンス化される新興トレンド。
2.3 データタイプ適応
LLMに多様な推薦信号を統合するために、既存のアプローチは非テキストモダリティをLLM互換のテキストのような表現に適応させています。これらには構造化変換(グラフ、テーブルデータなど)、要約技術(画像や行動など)、直接マルチモーダルプロンプティングが含まれます。適応により、アーキテクチャ変更を必要とせずにLLMが異質な入力を超えて推論することが可能になり、ゼロショットプロンプティングと微調整戦略の両方をサポートします。しかし、このような変換はリッチモダリティをテキストに圧縮する際に、アライメントエラーや情報損失を導入する可能性があります。コストはさまざまです:KG構築とアダプターベースの融合は多くの場合、高いエンジニアリング努力を必要としますが、プロンプトベースの戦略はより軽いオプションを提供します。
- 2.3.1 KGベースの変換: ナレッジグラフを使用して異質なデータを統一し、マルチモーダル入力とLLM間の適応レイヤーを提供する手法。
- 2.3.2 セマンティックID変換: ユーザー/アイテムIDを自然言語プロンプトまたは学習された埋め込みを通じて意味的トークン空間にマッピングする方法。
- 2.3.3 テーブルからテキストへの変換: テンプレート、In-Context Learning、特徴ベースの戦略を使用して構造化テーブルデータを自然言語プロンプトに変換する技術。
- 2.3.4 LLM入力のための画像要約: MLLMまたはビジョン言語モデルを使用して視覚的入力をテキストの要約または説明に変換する方法。
- 2.3.5 行動からテキストへの要約: クリック、ビュー、シーケンスなどの構造化ユーザーインタラクションログを自然言語要約に変換する手法。
- 2.3.6 プロンプトベースの融合: In-Context Learning、Chain of Thought、テンプレートを使用してマルチモーダル信号をLLM互換のテキストに整合させる方法。
- 2.3.7 適応されたマルチモーダル融合: 事前訓練されたエンコーダ、アダプタ、または投影モジュールを使用して、LLMに入力を渡す前に複数のモダリティを統合する技術。
3. MRS手法
このセクションでは、LLMをマルチモーダル推薦システム(MRS)のニーズに適応させるために特別に設計された戦略に焦点を当てています。一般的なLLM技術とは異なり、ここで議論される方法は、MRSの核心的な課題に対処しています:異種モダリティの組み合わせ、異なるモダリティの意味の保存、有意味な推薦へのユーザーアイテムインタラクションの融合です。これらのアプローチを3つのカテゴリに整理します:Disentangle(分離)、Alignment(調整)、Fusion(融合)。
3.1 Disentangle(分離)
マルチモーダル学習における分離(Disentangle)は、異なるデータタイプの表現内で共有モダリティ固有の情報を分離することを目的とした重要なプロセスです。目的は、モダリティ間で関連する特徴と個々のモダリティに固有の特徴を明確に区別することです。様々な分離方法が提案されており、それぞれが異なるメカニズムを通じてこの分離を追求しています。このセクションでは、推薦タスクにおけるマルチモーダルシステムでの適用について分析します。
- 3.1.1 対照的方法: モダリティ固有の共有表現を正/負サンプル構築を通じてモダリティまたはビュー間で整合または分離するために、対照学習を使用する手法。
- 3.1.2 注意ベースの方法: 知識蒸留または因果分析と組み合わせて、動的にモダリティの寄与を再重み付けまたは分離するために注意メカニズムを適用するアプローチ。
- 3.1.3 クラスタリングベースの方法: モダリティまたはサブグループ全体で共有および発散する興味を捉えるために、トークン、アイテム、またはユーザーに対してクラスタリングメカニズムを使用するモデル。
- 3.1.4 VAEベースの方法: (変分)オートエンコーダーを使用して潜在因子を学習し、コンテンツ、コラボレーティブ、およびモダリティ固有の表現間の構造的独立性を強制する手法。
- 3.1.5 アーキテクチャ駆動型方法: モダリティまたは意図固有の信号を分離および制御するために、専用エンコーダ、ルーティングモジュール、または専門家混合セットアップなどの構築的コンポーネントを構築する方法。
3.2 アライメント
アライメント戦略は、異質なモダリティ表現間の一貫性を強制することで、マルチモーダル学習において中心的な役割を果たします。これらは、共有意味空間にマッピングするか、モデル推論またはトレーニング中の相互作用を調整することで行われます。最終的な目標は、モダリティ固有の表現が共有意味をキャプチャし、一貫したクロスモーダル推論を可能にすることを保証することです。これは推薦システムで特に重要であり、整合された埋め込みは異なるデータタイプ全体でのユーザー選好、アイテムコンテンツ、インタラクション動作の共同モデリングを容易にします。
- 3.2.1 最適化ベースのアライメント: 対照学習、VAE、注意ベースの手法を使用してモダリティ表現を近づける
- 3.2.2 アダプターと投影ベースのアライメント: 軽量ニューラルコンポーネントでモダリティ固有入力を共有空間にマッピング
- 3.2.3 事後的アライメント: 初期モデリング後に表現を洗練し、マルチモーダル空間間の一貫性を向上
- 3.2.4 RL強化と外部アライメント: 強化学習と外部推論メカニズムを活用してマルチモーダル情報とユーザー意図を整合
- 3.2.5 NLPベースのアライメント: 微調整や指示チューニングを通じてLLM内部でマルチモーダル特徴を整合
3.3 融合分類
マルチモーダル推薦システム(MRS)では、ユーザーとアイテムに関連する膨大で多様なマルチモーダル情報が、推薦タスク用の包括的な特徴ベクトルを生成するための効果的な融合技術を必要としています。歴史的に、融合手法は単純なネットワークからモダリティを結合する単純な連結から、注意メカニズムへと進化し、粗粒度から細粒度のアプローチへと進化してきました。この進化は以前のMRSに関する調査で重要な焦点でした。
- 3.3.1 融合の位置: LLMを中心としたシステムでは、モダリティはLLMの前または並行して統合され、早期・中間・後期融合の概念が変化
- 3.3.2 融合のタイプ: 初期の連結や専門家の組み合わせから、Bahdanau注意機構や乗法的注意へと進化し、最終的に粗粒度から細粒度の融合技術へと発展
4. 主要なトレンドと将来の方向性
マルチモーダル推薦システム(MRS)分野が進化し続けるにつれて、いくつかの主要なトレンドがモデル統合と表現学習の未来を形作っています。これらの新たな方向性は、マルチモーダル相互作用の最適化、効率性の向上、およびデータ融合、プロンプティング、モデル適応のためのより洗練された技術の活用に焦点を当てています。
- マルチモーダル統合のためのブリッジとしてのKG:ナレッジグラフ(KG)は、テキスト、画像、テーブルデータ、地理空間情報など、異種モダリティを統一表現に整合させるための構造化中間体を提供します。
- 標準融合方法としてのソフトプロンプティング技術とアダプター(LoRA、QLoRA)の組み合わせ:ソフトプロンプティングとLoRAやQLoRAなどのアダプターベースの微調整技術を組み合わせることは、モジュラーかつ効率的なマルチモーダル融合のための有望な方向性を提供します。
- 重要なトピックに基づいた粗粒度と細粒度の注意メカニズムの組み合わせた使用の拡張:将来の研究は、粗粒度と細粒度の注意メカニズムをより動的な方法で組み合わせ、各マルチモーダルタスクの特定のニーズに適応させることを探求する可能性があります。
- マスキングは時代遅れではなく、刷新されただけ:MLMなどのマスキング技術は、LLMベースの推薦においても価値を保持しており、特にマルチモーダルデータに適応された場合に効果的です。
- 要約を通じたアライメントのためのLLM:YeらとLuoらの研究では、LLMとモダリティを整合させるために画像からテキストへの要約を使用しています。
- 推薦のためのMLLM:VIP5、UniMP、Molarなどの多くの研究が、融合メカニズムやエンドツーエンドパイプラインを通じて多様なモダリティをモデル化するためのMLLMの有望性を示しています。
- LLMベースの評価:人間による評価は、有用性、一貫性、ユーザー満足度などの主観的品質を評価するためのゴールドスタンダードであり続けていますが、コストが高く拡張が困難です。
- LLM推論のための構造化JSON入力:95やKRなどの最近の研究では、多様なデータタイプ(ユーザープロファイル、アイテム属性、インタラクションログなど)をLLMベースの推薦システムに導入するための構造化JSON形式の使用を探求しています。
- 構造化推論のためのPythonクラスベースのプロンプト:一部の最近のNLP研究では、プロンプト内でPythonクラス定義を使用してスキーマや構造化入力を表現することを提案しています。
- エージェントとRAG:エージェントをマルチモーダル推薦システムで使用すること、特に検索拡張生成(RAG)を通じて、エキサイティングかつ未探索の将来の方向性を示しています。