目次
Fine-Tuning Without Forgetting: Adaptation of YOLOv8 Preserves COCO Performance
この論文は、YOLOv8モデルを微調整する際の深さが、特定のタスクに対する性能を向上させる一方で、元の一般的な能力を損なわないことを示した研究です。
YOLOv8モデルの中〜後期のバックボーン層をより深くファインチューニングすることで、特化した物体検出タスクのパフォーマンスを大幅に向上させつつ、元のCOCOベンチマークでの性能低下をほぼ無視できるレベルに抑えています。
論文:https://arxiv.org/abs/2505.01016

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
大規模な事前学習済みオブジェクト検出器の成功は、多様な下流タスクへの適応性に依存しています。ファインチューニングは標準的な適応方法ですが、これらのモデルを困難な細かいドメインに特化させるには、特徴の粒度について慎重に考慮する必要があります。重要な問いは、元の一般的な能力の壊滅的な忘却を招くことなく、特化したタスクの最適化のために事前学習済みのバックボーンをどの程度までファインチューニングすべきかということです。
本研究では、この問いに対処するため、ファインチューニングの深さが与える影響を評価する体系的な実証研究を提示します。標準的なYOLOv8nモデルをカスタムの細かい果物検出データセットに適応させ、バックボーン層を段階的にアンフリーズ(層22、15、および10でのフリーズポイント)してトレーニングを行いました。パフォーマンスは、ターゲット果物データセットおよび二重ヘッド評価アーキテクチャを使用して元のCOCO検証セットでも厳密に評価されました。結果は明確に、より深いファインチューニング(層10までアンフリーズ)が、ヘッドのみをトレーニングした場合と比較して、細かい果物タスクで大幅なパフォーマンス向上(例えば、+10%の絶対mAP50)をもたらすことを示しています。
驚くべきことに、この重要な適応と特化は、すべてのテストされたフリーズレベルでCOCOベンチマークに対してわずかなパフォーマンスの劣化(<0.1%の絶対mAP差)をもたらしました。私たちは、中〜後期のバックボーン特徴を適応させることが、細かい特化に対して非常に効果的であると結論付けます。重要なことに、私たちの結果は、この適応が一般的に期待される壊滅的な忘却のペナルティなしに達成できることを示しており、特に複雑なドメインを対象とする場合や、特化したパフォーマンスを最大化することが重要な場合に、より深いファインチューニング戦略を探求することの説得力のある根拠を提示します。
1. 序論
物体検出は現代のコンピュータビジョンの基盤的技術であり、YOLOのような深層学習モデルの進歩により大きく発展しました。これらのモデルはCOCOなどの大規模汎用データセットで事前学習され、多様なタスクに適用できます。しかし、植物種の識別や小売製品の認識などの特定の細粒度ドメインにはさらなる特殊化が必要です。このような特殊化には、事前学習モデルの微調整が標準的なアプローチですが、微調整の最適な深さ(最終分類層のみ、あるいはバックボーンの一部を含めるべきか)についての課題が残ります。より深く微調整すれば特殊タスクでの性能向上が期待できますが、計算コストや破滅的忘却のリスクが高まります。本研究では、微調整の深さと特殊性能向上・破滅的忘却のバランスを実証的に調査します。
2. 関連研究
2.1 物体検出における転移学習
転移学習は、ImageNetやCOCOなどの大規模データセットで事前学習されたモデルを利用し、下流タスクのデータとリソース要件を削減する基盤となっています。適応戦略として、事前学習モデルを固定特徴抽出器として使い新しいタスク固有のヘッドのみを訓練する方法と、事前学習ネットワークの一部または全層を微調整する方法があります。全層を微調整すると高性能が得られますが、小規模データセットでは過学習のリスクがあります。一方、バックボーン全体を凍結すると計算コストは低減しますが、ターゲットドメインが元のドメインと大きく異なる場合には適応性が制限される可能性があります。
2.2 細粒度視覚カテゴリ化
細粒度視覚カテゴリ化は、クラス間の微妙な違いとクラス内の大きな変動により独自の課題があります。鳥の種類や車のモデル、本研究の果物を区別するには、一般的な分類モデルでは見落とされがちな、局所的で判別的な特徴をとらえる必要があります。注意機構や高次特徴相互作用などの専門手法も提案されていますが、本研究では新しいアーキテクチャを提案するのではなく、標準的なYOLOv8nの既存層を制御的に微調整することで細粒度タスクへの適応能力を分析します。
2.3 破滅的忘却と継続学習
事前学習されたネットワークが新しいタスクに微調整されると、元のタスクでのパフォーマンスが大幅に低下する「破滅的忘却」が生じることがあります。この問題に対処するために、損失関数に制約を追加する正則化ベース手法、以前のタスクからのサンプルを保存・再生する再演ベース手法、異なるタスクに動的にモデルパラメータを割り当てるアーキテクチャベース手法などが開発されています。本研究では明示的な忘却軽減技術を使用せずに、標準的な微調整でも元のCOCOタスクでの性能低下が最小限に抑えられるという興味深い結果を示します。
2.4 YOLO物体検出モデル
YOLOファミリーは、Redmonらによる最初の提案以来、リアルタイム物体検出の影響力のあるシリーズとなっています。その後のバージョンでは、特徴ピラミッド、アンカーボックス、改良されたバックボーンなどのアーキテクチャの改善を通じて精度と柔軟性を向上させています。YOLOv8はこの進化を継続し、CSPDarknetバックボーン、アンカーフリー検出ヘッド、最適化されたトレーニング戦略を組み込んでいます。広く採用され強力なベースライン性能を持つ最小バージョンのYOLOv8nを実用的な転移学習シナリオ研究のための基本モデルとして選択しました。
3. 方法論
3.1 基本モデル
YOLOv8nを基本物体検出モデルとして使用しました。このモデルは効率的な特徴抽出のためのCSPDarknetベースのバックボーン、スケール間の特徴集約のためのPANetに触発されたネック、そしてデカップルされたアンカーフリー検出ヘッドを特徴としています。使用したモデルは大規模なCOCOデータセットで事前学習され、80の一般的な物体カテゴリに関連する堅牢な汎用視覚表現を備えています。
3.2 ターゲットデータセット:細粒度果物
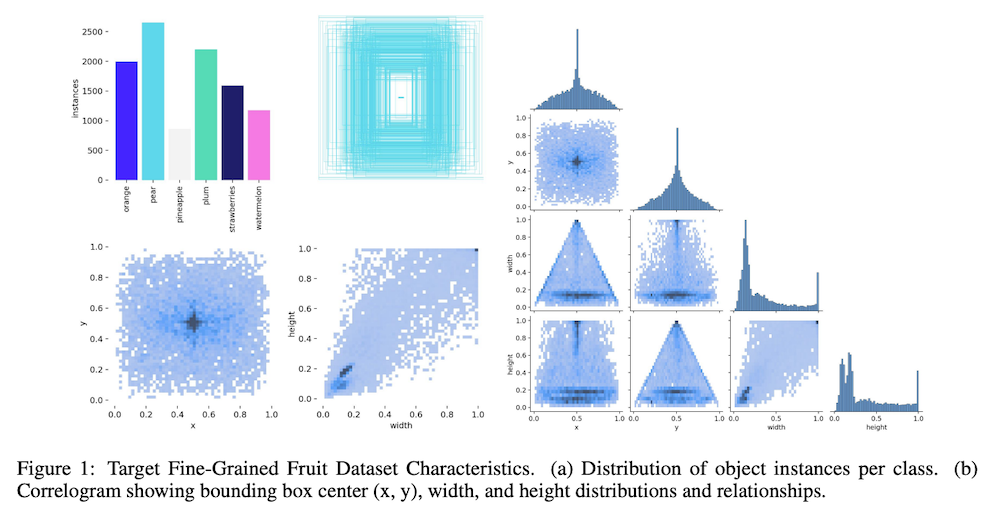
ドメイン特化が必要なリアルなアプリケーションシナリオをシミュレートするため、基本モデルを細粒度果物検出タスクに適応させます。自動冷蔵庫内容分析や小売チェックアウトシステムなど多くの実世界アプリケーションでは、COCOなどの一般データセットの対象範囲を超えた物体クラスの認識が必要です。実験のために、公開されているwhatsInYourFridgeデータセットから選択・フィルタリングした6クラスの果物データセット(オレンジ、梨、パイナップル、プラム、イチゴ、スイカ)を作成しました。このセレクションは視覚的に類似した果物の区別を要求する細粒度の課題を提示します。
3.3 微調整プロトコル
YOLOv8nバックボーンの訓練可能な層数を系統的に変化させることで、微調整の深さの影響を調査しました。Ultralyticsフレームワーク内のfreezeパラメータを使用して、3つの実験条件を作成しました:
- Freeze=22:最終検出ヘッド層(標準アーキテクチャのレイヤー22に相当)のみが訓練され、バックボーンとネック全体(レイヤー0-21)は元のCOCO事前学習の重みで凍結されました。
- Freeze=15:レイヤー15〜21(バックボーン/ネックの後期段階)と検出ヘッドが微調整されました。レイヤー0-14は凍結されました。
- Freeze=10:レイヤー10〜21と検出ヘッドが微調整されました。レイヤー0-9(初期バックボーン)は凍結されました。
微調整中、凍結されたネットワークセグメント内のバッチ正規化層は、実行統計が更新されないように評価モードに保たれました。すべてのモデルは640×640の画像サイズで100エポック、果物データセットで微調整されました。UltralyticsライブラリからのデフォルトハイパーパラメータとAdamWオプティマイザを使用し、NVIDIA Tesla T4 GPUで訓練を行いました。
3.4 評価戦略
各微調整プロトコルから得られたモデルを2つの異なるタスクで評価しました:
- ターゲットタスク(果物検出):各凍結条件(Freeze=10、15、22)の最良モデルチェックポイントを果物データセットの指定された検証スプリットで評価しました。標準的な物体検出メトリクス(mAP@0.5およびmAP@0.5:0.95)を計算しました。
- ソースタスク(COCO – 破滅的忘却):微調整がモデルの元の能力に与える影響を測定するため、標準COCO 2017検証セット(val2017)でパフォーマンスを評価しました。各凍結条件に対して、元のCOCO検出能力と新しく微調整された果物検出能力を統合した統一推論モデルを使用しました。
4. 実験と結果
4.1 実験セットアップとメトリクス
第3節で概説した通り、freezeパラメータを22、15、10に設定して3つの微調整構成で実験を行い、徐々により多くのバックボーン層を解凍しました。ターゲット果物データセットでのパフォーマンスはIoUしきい値0.5(mAP@0.5)および0.5:0.95(mAP@0.5:0.95)での平均精度で測定しました。ソースCOCOデータセット(val2017)でのパフォーマンスはpycocotoolsを使用して計算された標準COCOメトリクス、主にAP/mAP@0.5:0.95で測定しました。
4.2 果物検出性能
YOLOv8nバックボーンのより深い層を解凍して微調整することで、この特殊タスクの検出精度が大幅に向上するという明確な傾向が表れました。レイヤー10以降の適応を可能にするFreeze=10構成が最高のパフォーマンスを達成し、mAP@0.5で77.3%、mAP@0.5:0.95で54.1%に達しました。これは最終ヘッド層のみを訓練したベースラインFreeze=22構成と比較して、mAP@0.5で約+10%、mAP@0.5:0.95で+10%の絶対的な向上を示しています。この性能向上は、Freeze=10のPrecision-Recall曲線が一貫してFreeze=15およびFreeze=22よりも上に位置していることでも視覚的に確認されました。これは細粒度の果物データセットに必要な微細な視覚的区別を捉えるために中期〜後期のバックボーン特徴を適応させることの利点を強調しています。
4.3 COCO検出性能(忘却分析)
微調整がモデルの元の能力に与える影響を評価するため、マージされたモデル(COCOと微調整された果物ヘッドの両方を組み込んだ)のCOCO 2017検証セットでのパフォーマンスを評価しました。ベースラインパフォーマンスは、実験セットアップでのFreeze=22構成(バックボーンとCOCOヘッドが実質的に変更されていない)で、mAP@0.5:0.95が36.7%でした。驚くべきことに、評価結果はバックボーンをより深く微調整しても(Freeze=15およびFreeze=10)、COCOタスクでのパフォーマンス低下は測定できないことを示しました。すべての構成が実質的に同一のmAPスコアを示しました。これは、実験セットアップ内で、特殊な細粒度タスクでの大幅な性能向上が、事前訓練中に獲得したモデルの一般的な物体検出能力の破滅的忘却を引き起こすことなく達成できることを示しています。
4.4 重み検証サマリー
観察された忘却の欠如がモデルの保存と読み込みプロセスを通じて微調整された重みが持続しないことによるアーティファクトではないことを確認するため、バックボーン重み(レイヤー0-21)の直接比較を実施しました。読み込まれたマージドモデル(例:merged_freeze_15.pt)から抽出された重みを、元のベースyolov8n.ptの重みと比較しました。この比較により、微調整範囲内のレイヤー(例:Freeze=15モデルではレイヤー15-21)の重み値に多数の重要な違いが明らかになった一方で、この範囲外のレイヤーは同一のままでした。これは微調整中に学習された修正が確かに保存され読み込まれたことを確認し、表2に報告されたCOCOパフォーマンス結果を検証しています。
5. 議論と分析
5.1 特徴の粒度とターゲットタスク性能
より深いバックボーン層を解凍するにつれて観測された果物検出性能の著しい向上は、効果的な細粒度認識には最終分類ヘッドを超えた適応が必要だという仮説を強く支持しています。事前学習されたモデルは特徴の階層を学習します:初期層は一般的な低レベルパターン(エッジ、テクスチャ)をキャプチャし、中間層はより複雑なモチーフと部品を組み立て、後期層は典型的に事前学習クラスに関連する高レベルの意味情報をエンコードします。微調整の深さによる果物検出の性能向上は、形状、テクスチャ、部品の表現の精緻化が果物クラスの特定の識別要件によりよく適合するよう調整されたことを示しています。
5.2 破滅的忘却の不在
おそらく本研究の最も驚くべき結果は、元のCOCOタスクで観測された破滅的忘却の欠如です。特に最高の果物性能を示したFreeze=10およびFreeze=15構成で微調整中にバックボーン重みに著しい修正があったにもかかわらず、モデルは元のCOCO検出性能(約36.7%のmAP@0.5:0.95)を維持しました。この結果は、新しいタスクにネットワークを適応させると、特に深い微調整を通じて、元のソースタスクでのパフォーマンスが測定可能に低下するという一般的な期待と対照的です。モデル容量とパラメータ冗長性、タスクの相違と特徴の専門化、最適化ダイナミクス、アーキテクチャと評価などの要因がこの回復力に貢献している可能性があります。
5.3 実用的な意味
これらの発見は転移学習の適用に直接的な実用的意味を持ちます。実務者はしばしば破滅的忘却を緩和し訓練時間を短縮するためにバックボーンのほとんどを凍結するデフォルト設定を使用します。研究結果は、少なくともいくつかのシナリオでは、忘却のリスクが予想よりも低い可能性があることを示唆しています。特殊化された、複雑な、または細粒度のターゲットドメインで最大のパフォーマンスが優先される場合、より深い微調整戦略の探索(例:中期〜後期のバックボーン層の解凍)は十分に検討する価値があり、一般的な能力に大きなペナルティをもたらさない可能性があります。ターゲットタスクにおける潜在的なパフォーマンス向上(ここで示された+10%のmAP)は大きい可能性があります。
5.4 限界
この研究は明確な結果を提供する一方で、その結論の一般化可能性を制限する制約があります:単一の基本アーキテクチャ(YOLOv8n)と特定の細粒度果物データセットに基づいており、適応と忘却のバランスは他のアーキテクチャ、事前学習データセット、またはターゲットドメインでは異なる可能性があります。COCO評価は特定の二重ヘッド推論アプローチに依存しており、評価戦略が異なると正確なパフォーマンスの相互作用も若干異なる可能性があります。また、凍結点の変化を探索しましたが、学習率スケジュール、正則化技術、代替最適化アルゴリズムなど、微調整の他の側面は調査しませんでした。
6. 結論
本研究では、YOLOv8nモデルを細粒度果物認識タスクに適応させる際の微調整深度の影響を分析しました。バックボーンの中期〜後期層(レイヤー10まで)の微調整により、細粒度果物検出の精度が大幅に向上(+10%のmAP)しました。驚くべきことに、この特殊化は元のCOCOデータセットでのパフォーマンスにほとんど影響を与えませんでした。この発見は、特定の転移学習シナリオにおいて、一般に懸念される破滅的忘却のリスクなしに深い特徴適応が可能であることを示唆しています。モデルアーキテクチャの固有の回復力についてさらなる研究を促す結果となりました。