目次
AI Hiring with LLMs: A Context-Aware and Explainable Multi-Agent Framework for Resume Screening
この論文は、大規模言語モデル(LLM)を用いた多エージェントフレームワークによる履歴書スクリーニングの自動化とその効果を検証した研究です。
本論文の特徴は、業界特有の知識や基準を取り入れたリトリーバル拡張生成(RAG)を用いることで、候補者評価の文脈的関連性を向上させ、AIによるパーソナライズされた採用プロセスを実現している点です。
論文:https://arxiv.org/abs/2504.02870
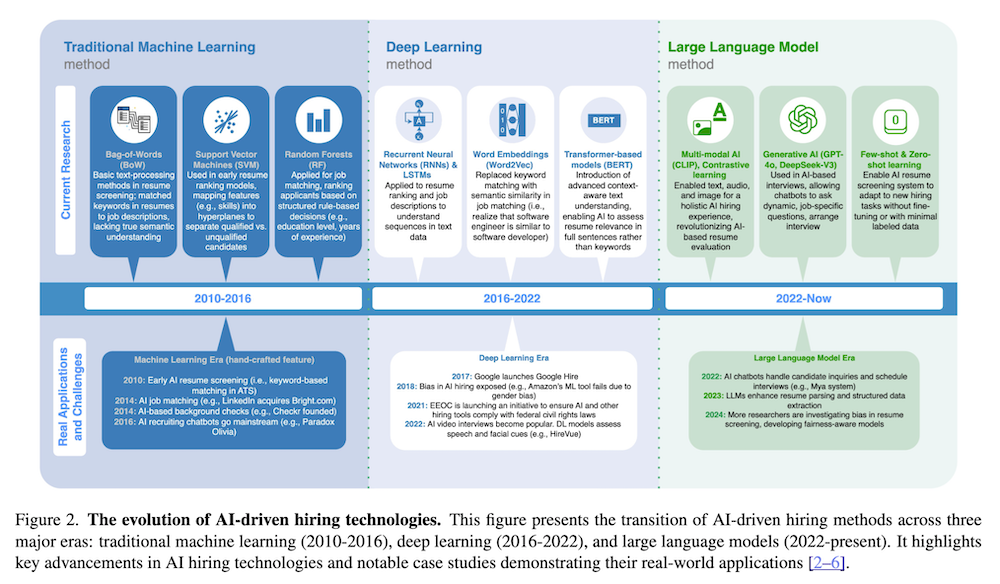

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
履歴書のスクリーニングは、採用において重要でありながら時間を要するプロセスであり、リクルーターは膨大な数の応募書類を分析し、客観的かつ正確、公平である必要があります。大規模言語モデル(LLMs)の進展に伴い、その推論能力と広範な知識ベースは、採用ワークフローを効率化し、自動化する新たな機会を示しています。
本研究では、LLMsを使用して履歴書を体系的に処理・評価するためのマルチエージェントフレームワークを提案します。このフレームワークは、履歴書抽出器、評価者、要約者、スコアフォーマッタの4つのコアエージェントで構成されています。候補者の評価の文脈的関連性を高めるために、履歴書評価者内にリトリーバル拡張生成(RAG)を統合し、業界特有の専門知識、専門資格、大学ランキング、企業特有の採用基準などの外部知識源を取り入れることを可能にします。この動的な適応により、AIの自動化と人材獲得のギャップを埋めるパーソナライズされた採用が実現します。
私たちは、匿名化されたオンライン履歴書のデータセットにおける人事専門家による評価とAI生成スコアを比較することで、アプローチの効果を評価します。結果は、マルチエージェントRAG-LLMシステムが履歴書スクリーニングを自動化し、より効率的でスケーラブルな採用ワークフローを実現する可能性を強調しています。
論文の要約
1. はじめに
1.1 背景
履歴書のスクリーニングは、タレントアクイジションにおいて重要かつ時間を要するプロセスです。採用担当者は、大量の応募書類を客観的、正確に分析する必要があります。本研究は、大規模言語モデル(LLMs)の進展を基に、採用ワークフローの自動化と効率化を図る新しい機会を探ります。
2. 提案するフレームワーク
2.1 マルチエージェントフレームワーク
本研究では、履歴書スクリーニングのためのマルチエージェントフレームワークを提案します。このフレームワークは、以下の4つのコアエージェントから構成されています:
- 履歴書抽出エージェント: 応募者の情報を正確に抽出します。
- 評価エージェント: 抽出された情報に基づきスコアを生成します。
- 要約エージェント: 評価結果を簡潔にまとめます。
- スコアフォーマッター: 最終得点のフォーマットを行います。
2.2 RAGの統合
特に、評価エージェントにはRetrieval-Augmented Generation(RAG)が統合されており、業界特有の専門知識、職業資格、大学ランキング、企業固有の採用基準などの外部知識源を取り入れることで、文脈的関連性を向上させています。この動的な適応により、個別化された採用プロセスが実現されます。
3. 方法論
3.1 実験設定
実験では、105件の完全に匿名化されたオンライン履歴書からなるデータセットを使用しました。このデータセットは人事専門家によって自己評価、スキルと専門性、職務経験、基本情報、学歴の5つの主要側面でスコア付けされています。プライバシー保護のため、氏名や会社名などの個人識別情報はすべて削除されています。データセットの履歴書は主に人事分野のさまざまな職位に対応しており、ジュニアレベル(人事インターンや人事アシスタント)、中堅レベル(人事アソシエイトや人事スペシャリスト)、シニアレベル(人事マネージャーやシニア人事)、リーダーシップ(人事ディレクターや戦略的人事パートナー)の4つのグループに分類されています。
3.2 評価方法
提案した履歴書スクリーニングシステムを評価するために、次の評価指標を採用しました。まず、ピアソン相関は、AI推定スコアと人間の評価者スコア間の線形関係を測定します。この指標は、AIシステムが人間の評価者と同様の方法でスコアを割り当てているかを評価するのに役立ちます。次に、スピアマン相関は、AIと人間の評価者スコア間のランクベースの単調関係を評価します。ピアソン相関とは異なり、スコアをランク付けしてから相関を計算することで非線形関係も捉えることができます。最後に、平均絶対誤差(MAE)はAI予測と人事スコア間の絶対差を測定し、誤差の平均的な大きさを把握します。この指標は、AIの判断が人間の判断からどの程度逸脱しているかを理解するのに特に有用です。
4. 結果と考察
4.1 実験結果
マルチエージェントRAG-LLMの有効性を評価するため、まず単一のLLMとの性能比較を行いました。GPT-4oとDeepSeek-V3を含む複数のLLMバックボーンを使用して結果を分析しました。実験結果は、提案したRAG-LLMフレームワークが良好な性能を示し、一貫して単一LLMを上回ることを確認しました。特に、真値スコアが上位・下位10%、15%、20%パーセンタイル内に収まる候補者に焦点を当てた評価では、DeepSeek-V3を用いたRAG-LLMが最高のピアソン相関(PC10=0.84、p値<0.001)、スピアマン相関(SC10=0.74、p値<0.001)、および最低のMAE(0.90)を達成し、単一LLMのベースラインを上回りました。この傾向は15%および20%の閾値でも同様で、RAG-LLMが上位候補者と下位候補者を正確に区別する一貫した能力を強調しています。
4.2 今後の展望
本研究の結果は、AIを活用した人材採用の新たな方向性を示しており、さらなる実用化が期待されます。今後の研究では、フレームワークの最適化や他の応用可能性についても検討していく必要があります。
5. 結論
本研究は、LLMsを用いた履歴書スクリーニングのための新たなマルチエージェントフレームワークを提案し、その効果を実証しました。これにより、採用プロセスの効率化と拡張性向上が可能であることが示されています。今後の研究では、さらなるフィードバックを通じて、フレームワークの改善を目指します。