目次
OneLLM: One Framework to Align All Modalities with Language
この論文は、異なる8つのモダリティを統一フレームワークで言語に整合させる「OneLLM」というマルチモーダル大規模言語モデルの提案をしています。
OneLLMは、視覚エンコーダと大規模言語モデルを効果的に接続するための画像投影モジュールを活用し、8つの異なるモダリティを統一的に整合させる新しいアプローチを提案しています。
論文:https://arxiv.org/abs/2312.03700
リポジトリ:https://github.com/csuhan/OneLLM
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
マルチモーダル大規模言語モデル(MLLM)は、その強力なマルチモーダル理解能力により大きな注目を集めています。しかし、既存の研究はモダリティ固有のエンコーダに大きく依存しており、これらは通常アーキテクチャが異なり、一般的なモダリティに限定されています。
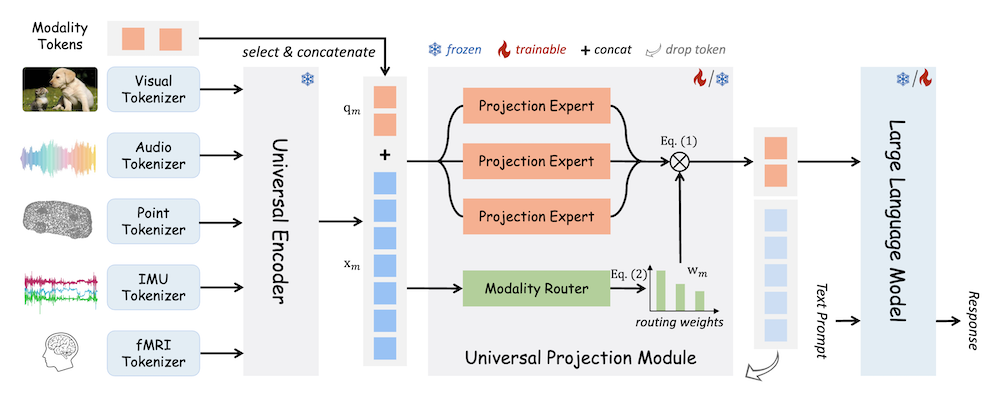
本論文では、言語に対して8つのモダリティを統一フレームワークで整合させるMLLMであるOneLLMを提案します。これは、統一されたマルチモーダルエンコーダと進行的なマルチモーダル整合パイプラインを通じて実現しています。具体的には、まず視覚エンコーダとLLMを接続する画像投影モジュールをトレーニングします。次に、複数の画像投影モジュールと動的ルーティングを混合して普遍的な投影モジュール(UPM)を構築します。最後に、UPMを用いてより多くのモダリティをLLMに進行的に整合させます。
OneLLMの指示に従う潜在能力を十分に活用するために、画像、音声、動画、点群、深度/法線マップ、IMU、fMRI脳活動からなる200万件のアイテムを含む包括的なマルチモーダル指示データセットも策定しました。OneLLMは、マルチモーダルキャプショニング、質問応答、推論といったタスクを含む25の多様なベンチマークで評価され、優れたパフォーマンスを発揮します。
OneLLM: 言語と全てのモダリティを統合するフレームワーク
1. はじめに
本論文では、マルチモーダル大規模言語モデル(MLLM)の重要性とその課題を背景に、従来のモダリティ特有のエンコーダに依存するアプローチの限界を指摘しています。これにより、異なるモダリティ間の整合性が欠如し、アーキテクチャの違いによって一般的なモダリティへの制限が生じることが問題視されています。
2. OneLLMの提案
OneLLMは、言語と八つの異なるモダリティを統一的に整合させるためのフレームワークを提供します。このフレームワークは、以下の重要な要素を含みます。
2.1 統一されたマルチモーダルエンコーダ
最初に、画像プロジェクションモジュールを訓練し、視覚エンコーダと大規模言語モデル(LLM)を接続します。このプロセスは、視覚情報をLLMが理解できる形式に変換するために不可欠です。
2.2 ユニバーサルプロジェクションモジュール(UPM)の構築
次に、複数の画像プロジェクションモジュールと動的ルーティングを組み合わせ、UPMを構築します。このUPMにより、LLMに対してさらに多くのモダリティを段階的に整合させることが可能となります。
3. データセットの構築
OneLLMの指示に従う能力を最大限に引き出すために、著者らは包括的なマルチモーダル指示データセットを作成しました。このデータセットには、画像、音声、動画、点群、深度/法線マップ、IMU、fMRI脳活動からの200万アイテムが含まれています。
4. 実験と評価
OneLLMは、マルチモーダルキャプショニング、質問応答、推論など、25の多様なベンチマークにおいて評価されました。これにより、モデルの性能が優れていることが確認され、特にマルチモーダルデータに対する応答生成の精度が重視されました。評価には、タスクごとに定義された基準に基づいて、定量的および定性的な分析が行われました。
5. 結論
OneLLMは、異なるモダリティを統合するための新たなアプローチを提供し、MLLMの限界を克服することに成功しました。これにより、マルチモーダル理解の可能性が大きく広がることが期待されます。提供されたコード、データ、モデル、オンラインデモは、さらなる研究や実装に向けてアクセス可能です。