目次
Rho-1: Not All Tokens Are What You Need
この論文は、言語モデルの訓練方法において、全てのトークンを均等に扱うのではなく、有用なトークンに選択的に焦点を当てる新しいアプローチ「Rho-1」を提案し、数学タスクにおいて顕著な精度向上を示しています。
Rho-1は、選択的言語モデリングを採用することで、従来の方法に比べて必要なトークンのみを効率的に訓練し、少数ショット学習において最大30%の精度向上を実現した点が特筆されます。
論文:https://arxiv.org/abs/2404.07965
リポジトリ :https://github.com/microsoft/rho
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
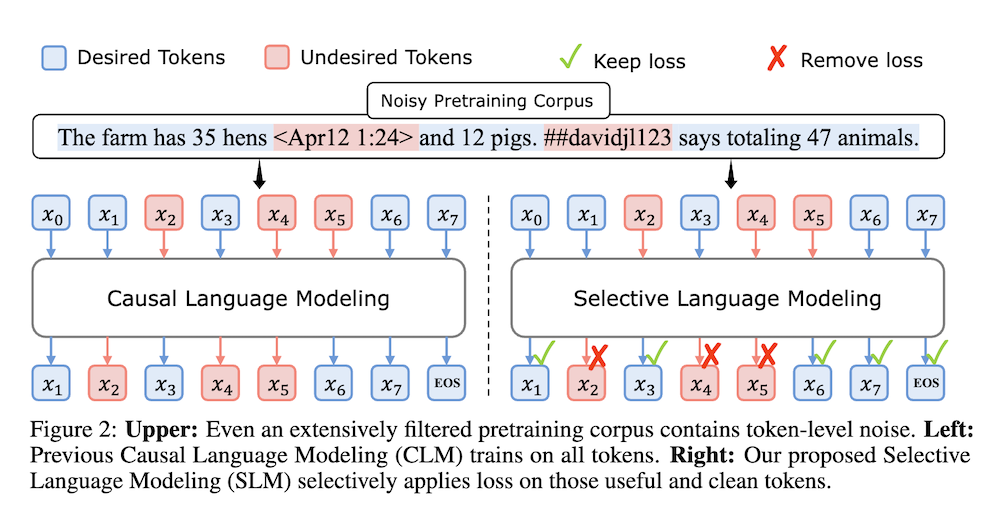
この論文では、従来の言語モデルの事前訓練方法がすべての訓練トークンに対して次のトークン予測損失を一律に適用していることに異議を唱え、「9l訓練」を提案します。初期の分析では、言語モデルのトークンレベルの訓練ダイナミクスを検討し、異なるトークンに対して明確な損失パターンがあることを明らかにしました。
この知見を活用して、Rho-1という新しい言語モデルを導入します。従来の言語モデルがコーパス内のすべての次のトークンを予測するのに対し、Rho-1は選択的言語モデリング(SLM)を採用し、望ましい分布に沿った有用なトークンのみに焦点を当てて訓練します。このアプローチでは、参照モデルを使用して事前訓練トークンにスコアを付け、そのスコアが高いトークンに対して集中的に損失を訓練します。15B OpenWebMathコーパスでの継続的な事前訓練において、Rho-1は9つの数学タスクにおいて最大30%の少数ショット精度の絶対的な改善をもたらしました。
ファインチューニング後、Rho-1-1Bと7BはそれぞれMATHデータセットで40.6%と51.8%の最先端結果を達成し、事前訓練トークンのわずか3%でDeepSeekMathに匹敵しました。さらに、80Bの一般的なトークンでの継続的な事前訓練において、Rho-1は15の多様なタスクで平均6.8%の向上を達成し、言語モデルの事前訓練の効率と性能を向上させました。
Rho-1: すべてのトークンが必要なものではない
1. はじめに
本研究は、従来の言語モデルにおける次トークン予測損失が全てのトークンに均一に適用されるという慣習に挑戦し、トークンレベルでのトレーニングダイナミクスを分析することで、異なるトークンに対する損失パターンの違いを明らかにしています。この分析に基づき、新たに提案されたモデル「Rho-1」は、選択的言語モデリング(SLM)を採用することで、必要なトークンのみに焦点を当てたトレーニングを行います。
2. 方法論
2.1 Rho-1モデルの導入
Rho-1モデルは、事前トレーニングにおいて参照モデルを用いてトークンにスコアを付け、高得点のトークンに対して集中した損失を用いることでトレーニングを行います。このアプローチにより、従来のモデルに比べて効率的に必要な情報を学習し、パフォーマンスの向上を図っています。
2.2 実験設定
Rho-1は、15BのOpenWebMathコーパスに対して継続的な事前トレーニングを行い、9つの数学タスクにおいて最大30%の絶対的な少数ショット精度の改善を達成しました。特に、Rho-1-1Bと7Bモデルは、MATHデータセットにおいてそれぞれ40.6%と51.8%の最先端結果を記録し、これはDeepSeekMathと同等の性能を示していますが、事前トレーニングトークンはわずか3%しか使用していません。
2.3 効率性の向上
さらに、Rho-1は80Bの一般トークンに対しても継続的な事前トレーニングを行い、15の多様なタスクにおいて平均6.8%の改善を達成しました。この成果は、モデルのトレーニング効率と性能の両方を向上させることに成功したことを示しています。
3. 結果と考察
Rho-1は選択的にトークンをトレーニングすることにより、全体的な性能が向上することを示しました。この結果は、トークンの選択が言語モデルの学習において重要な要素であることを強調しています。今後の研究においては、トークンの選択に基づくより効果的なトレーニング手法の模索が期待されます。
本研究は、従来の手法に新たな視点を提供し、Rho-1のアプローチが特定のトークンに焦点を当てることによって、言語モデルの性能と効率性を大幅に向上させる可能性があることを示しています。