目次
DeepSeek-V3 Technical Report
この論文は、671Bのパラメータを持つ新しいMixture-of-Experts(MoE)言語モデルDeepSeek-V3を提案し、その効率的なトレーニング手法と優れた性能を示しています。DeepSeek-V3は、671Bのパラメータを持ちながらも、各トークンに対して37Bのみをアクティブにすることで、高効率なトレーニングを実現し、コストを大幅に削減しています。
論文:https://arxiv.org/abs/2412.19437
リポジトリ:https://github.com/deepseek-ai/DeepSeek-V3
以下は、LLMを用いてこの論文の内容を要約したものになります。
1. 概要
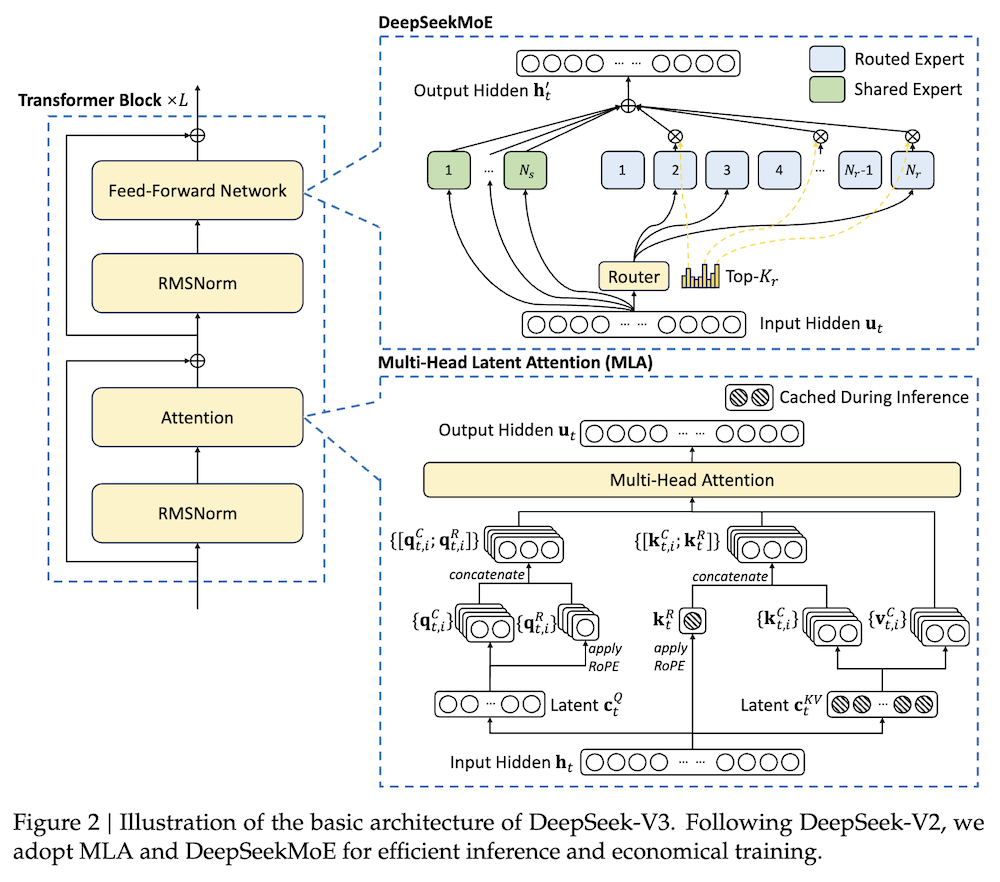
DeepSeek-V3は、合計671Bのパラメータを持つ強力なMixture-of-Experts (MoE) 言語モデルであり、各トークンに対して37Bがアクティブになります。効率的な推論とコスト効果の高いトレーニングを実現するために、DeepSeek-V3はMulti-head Latent Attention (MLA)およびDeepSeekMoEアーキテクチャを採用しています。これらはDeepSeek-V2で徹底的に検証されています。
さらに、DeepSeek-V3は、負荷分散のための補助損失なしの戦略を先駆けて導入し、より強力なパフォーマンスのためにマルチトークン予測トレーニングの目標を設定しています。DeepSeek-V3は148兆の多様で高品質なトークンで事前トレーニングを行い、その後、監視された微調整と強化学習の段階を経て、その能力を最大限に引き出します。
包括的な評価により、DeepSeek-V3は他のオープンソースモデルを上回り、リーディングなクローズドソースモデルと同等のパフォーマンスを達成することが明らかになりました。優れたパフォーマンスにもかかわらず、DeepSeek-V3はフルトレーニングにわずか2.788MのH800 GPU時間を必要とし、トレーニング全体を通じて回復不可能なロススパイクやロールバックを経験することはありませんでした。モデルのチェックポイントは、リポジトリで利用可能です。
2. はじめに
2.1 背景と目的
DeepSeek-V3は、671Bのパラメータを持つMixture-of-Experts (MoE)モデルであり、各トークンに対して37Bのパラメータがアクティブになります。近年の大規模言語モデル(LLM)の進化を背景に、効率的な推論とコスト効果の高い学習を実現するために、Multi-head Latent Attention (MLA)およびDeepSeekMoEアーキテクチャを採用しています。また、マルチトークン予測の学習目標を設定し、トレーニング信号の密度を高めることによってデータ効率を改善しています。
3. アーキテクチャ
3.1 基本アーキテクチャ
DeepSeek-V3は、Transformerフレームワークに基づき、MLAとDeepSeekMoEを使用しています。
3.1.1 Multi-Head Latent Attention (MLA)
MLAは、注意キーと値の低ランク共同圧縮を行い、推論時のKVキャッシュを削減します。具体的には、以下の数式が用いられます:
- \( c_{KV_t} = W_{DKV} h_t \)
- \( k_{C_t} = W_U K c_{KV_t} \)
3.1.2 DeepSeekMoEによる負荷分散
DeepSeekMoEアーキテクチャでは、フィードフォワードネットワーク(FFN)において、共有エキスパートとルーティングエキスパートを使用します。負荷が不均一になるとルーティングが崩壊するため、Auxiliary-Loss-Freeな負荷バランス戦略を導入し、各エキスパートにバイアス項を加えることでトークンごとのエキスパート選択を行います。
3.2 マルチトークン予測
DeepSeek-V3は、次のトークンを予測するだけでなく、複数の未来のトークンを同時に予測するマルチトークン予測(MTP)を採用しています。これにより、トレーニング信号が密になり、データ効率が向上します。
4. インフラストラクチャ
4.1 コンピュートクラスター
DeepSeek-V3は、2048のNVIDIA H800 GPUを搭載したクラスターでトレーニングされます。各ノードはNVLinkおよびNVSwitchで接続され、InfiniBandを使用して異なるノード間の通信が行われます。
4.2 トレーニングフレームワーク
トレーニングはHAI-LLMフレームワークを使用し、16-wayパイプライン並列処理、64-wayエキスパート並列処理、ZeRO-1データ並列処理を実装しています。DualPipeアルゴリズムを利用し、計算と通信のオーバーラップを実現することで、トレーニングの効率を向上させています。
4.3 FP8トレーニング
FP8データフォーマットを使用した混合精度トレーニングフレームワークを導入し、低精度トレーニングの利点を活かしつつ、トレーニングの速度とメモリ使用量を削減します。
5. プレトレーニング
5.1 データ構築
DeepSeek-V3は、14.8兆の多様かつ高品質なトークンで事前トレーニングされています。数学およびプログラミングサンプルの比率を最適化し、多言語対応を強化しました。
5.2 ハイパーパラメータ
トランスフォーマーの層数は61、隠れ次元は7168に設定され、すべての学習可能なパラメータは0.006の標準偏差でランダムに初期化されています。
5.3 評価
DeepSeek-V3は、MMLUやDROPなどのベンチマークで評価され、特に数学問題やコーディングタスクにおいて最先端の性能を示しています。
6. ポストトレーニング
6.1 教師付きファインチューニング
1.5Mのインスタンスからなる指示調整データセットを作成し、各ドメインに特化したデータ生成方法を使用しています。
6.2 強化学習
ルールベースおよびモデルベースの報酬モデルを利用して、さまざまな質問に対するフィードバックを生成しています。
7. 結論および今後の方向性
DeepSeek-V3は、最強のオープンソースモデルとしての地位を確立し、経済的なトレーニングコストで高いパフォーマンスを維持しています。今後は、モデルアーキテクチャの改良、トレーニングデータの質の向上、推論能力の強化を目指す予定です。