目次
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
この論文は、AIエージェントが現実の職場での業務にどの程度自律的に対応できるかを評価するためのベンチマーク「TheAgentCompany」を提案し、その実験結果を示しています。
TheAgentCompanyは、AIエージェントの真の業務能力を評価するために、実際の職場環境を模倣した多様なタスクを含む自己完結型のベンチマークを提供し、エージェントの自律性とコミュニケーション能力を包括的にテストする点が特に革新的です。
- 論文:https://arxiv.org/abs/2412.14161
- Webサイト:https://the-agent-company.com/
- リポジトリ:https://github.com/TheAgentCompany/TheAgentCompany
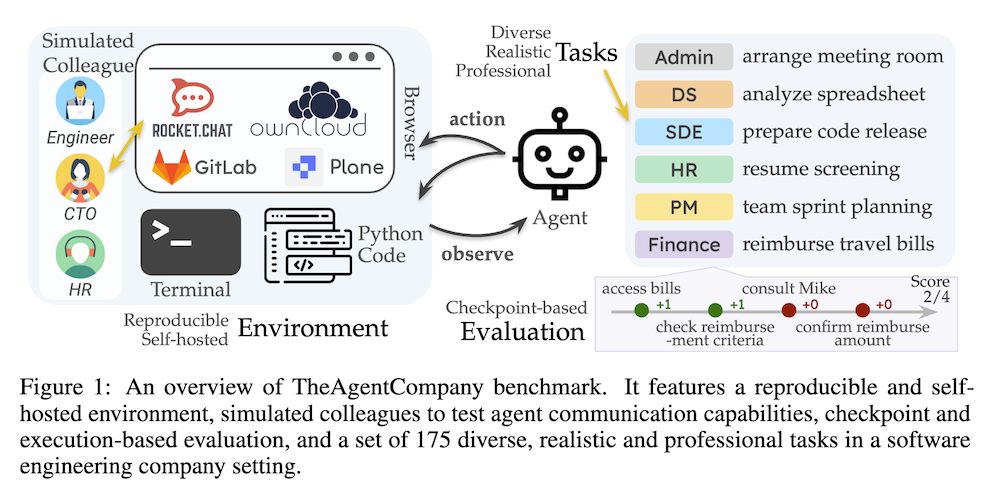
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
私たちは日常生活や仕事においてコンピュータと頻繁に相互作用しており、仕事の多くの側面はコンピュータとインターネットにアクセスすることで完全に行うことができます。同時に、大規模言語モデル(LLM)の改善により、周囲の環境と対話し、変化をもたらすAIエージェントの急速な発展が見られます。しかし、AIエージェントは仕事関連のタスクを加速させたり、さらには自律的に実行するのにどれほど効果的なのでしょうか。この問いの答えは、AIを業務フローに取り入れようとする産業や、AIの採用が労働市場に与える影響を理解しようとする経済政策にとって重要な意味を持ちます。
本論文では、LLMエージェントが実世界の専門的なタスクをどれだけ効果的に実行できるかを測定するために、TheAgentCompanyという拡張可能なベンチマークを提案します。このベンチマークは、ウェブを閲覧し、コードを書き、プログラムを実行し、他の同僚とコミュニケーションを取ることで、デジタルワーカーと類似の方法で世界と対話するAIエージェントを評価するためのものです。私たちは、小規模なソフトウェア会社の環境を模倣した自己完結型の環境を構築し、そのような会社の従業員が実行可能なさまざまなタスクを作成しました。
私たちは、閉じたAPIベースのモデルとオープンウェイトの言語モデルの両方によって動かされるベースラインエージェントをテストし、最も競争力のあるエージェントによって24%のタスクが自律的に完了できることがわかりました。これは、LMエージェントによるタスクの自動化に関する微妙な状況を描いています—実際の職場を模擬した設定では、比較的単純なタスクのかなりの部分が自律的に解決できる可能性がありますが、より難易度の高い長期的なタスクは依然として現在のシステムでは達成できません。
論文要約
1. はじめに
本研究では、AIエージェントが実世界の職務タスクを自律的に実行する能力を評価するためのベンチマーク「TheAgentCompany」を提案しています。このベンチマークの目的は、AIエージェントがどの程度自律的にタスクを行うかを測定し、産業界や経済政策への影響を評価することです。特に、大規模言語モデル(LLM)の進展により、AIの職務における自動化の可能性は増しているものの、その実用性には疑問が残っています。
2. ベンチマークの要件と他のベンチマークとの比較
TheAgentCompanyは、以下の要件を満たすように設計されています:
- 多様な職務タスクのカバレッジ: ソフトウェアエンジニアリングやプロジェクト管理など、現実的で多様なタスクを含んでいます。
- 相互作用の要求: エージェントが人間とコミュニケーションを取る能力を評価するためのテスト環境を提供します。
- チェックポイントを持つ長期タスク: 複数のステップを必要とするタスクを含み、進捗を評価するためのチェックポイントが設定されています。
3. TheAgentCompany環境の設定
- ローカルワークスペース: Dockerを使用し、エージェントはブラウザ、コードエディタ、Linuxターミナルを利用してタスクを実行します。
- イントラネット: プロジェクト管理ソフトウェアやコミュニケーションツールをホストし、リアルな業務データにアクセスできるようにします。
- シミュレートされた同僚とのコミュニケーション: RocketChatを通じてシミュレートされた同僚と情報をやり取りします。
4. タスク構造
タスクは以下の要素で構成されています:
- タスクの意図: エージェントが実行すべき明確な指示を含む説明。
- チェックポイント: タスクを進捗を測るために分割し、各チェックポイントにスコアを割り当てます。
- 評価者: 環境の状態やエージェントの行動を分析し、評価を行います。
5. タスクの作成
O*NETデータベースを参考にしながら、実務に即した多様なタスクを設計しました。タスクには具体的な成功基準が設定され、職務に関連した内容が選定されています。
6. ベースラインエージェント
OpenHandsエージェントを利用し、ブラウジング、ターミナル操作、プログラムの記述と実行を行います。このエージェントは、さまざまなインターフェースを通じて環境と相互作用します。
7. 実験結果
Claude 3.5 Sonnetモデルは、全タスクの24%を成功裏に完了し、34.4%の得点を得ましたが、特にRocketChatやownCloudのタスクではパフォーマンスが低下しました。また、エージェントの共通の失敗として、常識の欠如や社会的スキルの不足が挙げられました。
8. 結論と今後の方向性
TheAgentCompanyは、現実の職務タスクに焦点を当てた新しいベンチマークを提供しますが、AIエージェントが人間の労働を完全に自律的に行うにはまだ大きなギャップがあります。今後は、より複雑なタスクや他の産業におけるタスクの評価を拡張する方向が期待されます。
付録
TheAgentCompanyの概要、社員名簿、四半期目標、内部文書のリストなどが提供され、全体の背景や環境の詳細が示されています。