目次
AutoPatent: A Multi-Agent Framework for Automatic Patent Generation
この論文は、初期ドラフトに基づいてフルレングスの特許を自動生成するためのマルチエージェントフレームワーク「AutoPatent」を提案し、その実験結果を報告しています。
AutoPatentは、初期ドラフトから17Kトークンのフルレングス特許を生成する新しいタスク「Draft2Patent」を確立し、特許生成におけるマルチエージェントアプローチの有効性を示した点が特徴です。
論文:https://arxiv.org/abs/2412.09796
リポジトリ :https://github.com/QiYao-Wang/AutoPatent
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
この論文では、Large Language Models(LLMs)の能力が進化し続ける中、特許処理分野が自然言語処理コミュニティ内で注目を集めていることについて述べています。しかし、これまでの研究の大半は、特許の分類や審査といった分類タスク、あるいは特許の要約やクイズのような短文生成タスクに集中していました。
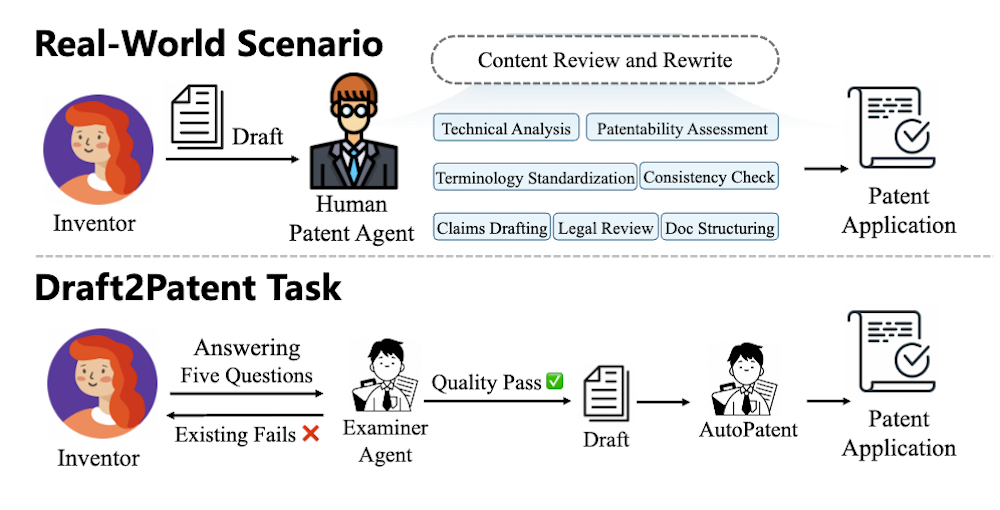
本論文では、Draft2Patentと呼ばれる新しく実用的なタスクと、その対応するD2Pベンチマークを紹介します。このタスクは、初期ドラフトに基づいて平均17Kトークンのフルレングス特許を生成することをLLMsに挑戦させるものです。特許はその専門性、標準化された用語、そして長大さのためにLLMsにとって大きな挑戦となります。
私たちは、LLMベースのプランナーエージェント、ライターエージェント、PGTreeとRRAGを用いた審査エージェントを活用した、AutoPatentというマルチエージェントフレームワークを提案します。実験結果は、AutoPatentフレームワークがさまざまなLLMsにおいて包括的な特許を生成する能力を大幅に向上させることを示しています。
さらに、Qwen2.5-7Bモデルに基づいてAutoPatentフレームワークのみで生成された特許が、GPT-4o、Qwen2.5-72B、LLAMA3.1-70Bといったより大きく強力なLLMsによって生成された特許を、客観的な指標と人間評価の両方で上回ることを発見しました。私たちは、受理後にデータとコードを提供する予定です。
自動特許生成のためのマルチエージェントフレームワーク
1. はじめに
本論文では、特許処理における自然言語処理(NLP)の進展とともに、新たに提案された「Draft2Patent」タスク及びその評価基準であるD2Pベンチマークについて述べています。このタスクは、初期ドラフトを基に平均17,000トークンの完全な特許を生成することを目指しています。特許文書は専門的な用語を使用し、長文で構成されるため、従来の自然言語生成タスクとは異なる難しさがあります。
2. AutoPatentフレームワーク
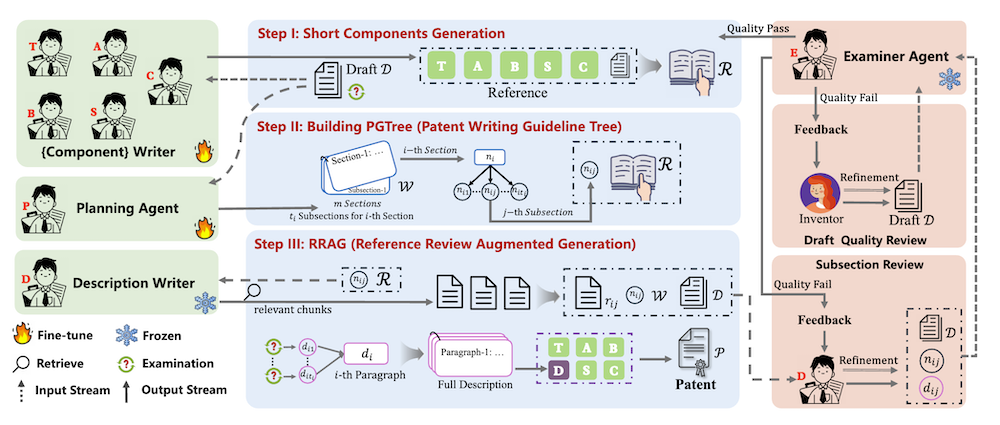
本研究では、「AutoPatent」というマルチエージェントフレームワークを導入しています。フレームワークは以下のエージェントで構成されています:
- プランナーエージェント:特許文書の生成計画を立案。
- ライターエージェント:実際に特許文書を生成。
- 審査エージェント:生成物の品質を評価。
これらのエージェントは、PGTree(パラメトリック生成木)およびRRAG(リファレンス・リーニング・エージェント・グループ)を利用し、高品質な特許文書の生成を実現します。
3. 方法論
3.1 Draft2Patentタスクの定義
Draft2Patentタスクは、特許の初期ドラフトから完全な特許を生成することを目的とし、特許の特性や長さを考慮した上でLLMに挑戦を与えます。
3.2 実験設定
実験は、D2Pベンチマークを用いて、AutoPatentフレームワークに基づくQwen2.5-7Bモデルを含む複数の大規模言語モデル(LLM)を比較しました。評価は客観的なメトリクス(BLEUスコア、ROUGEスコア)と人間評価の両方で行われ、生成された特許の専門性や文書構造の整合性が重視されました。
4. 実験結果
実験結果は、AutoPatentフレームワークが特許生成において他のモデルと比較して優れた性能を発揮することを示しています。特に、Qwen2.5-7Bモデルで生成された特許は、GPT-4oやQwen2.5-72B、LLAMA3.1-70Bなどの大型モデルに対して、一貫した品質と専門性を保ちながら、客観的なメトリクス及び人間評価において高い評価を得ました。
5. 課題と今後の展望
本研究は特許生成の自動化の利点を強調しつつ、今後の研究課題として、特許法や規制への適応、エージェント間の協力の強化を挙げています。また、使用したデータセットやコードは、論文受理後に公開される予定であり、これにより他の研究者が本研究を再現し、さらなる研究を進めることが期待されます。