目次
Phi-4 Technical Report
この論文は、合成データ生成を通じてデータ品質を重視した14億パラメータの言語モデルphi-4の開発とその性能向上について述べています。
phi-4は、従来のオーガニックデータに依存せず、高品質な合成データを戦略的に活用することで、STEM分野に特化したQA能力を大幅に向上させた140億パラメータの言語モデルです。
論文:https://arxiv.org/abs/2412.08905
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
私たちは、データの質に中心を置いたトレーニングレシピで開発された140億パラメータの言語モデルphi-4を紹介します。ほとんどの言語モデルが主にウェブコンテンツやコードなどのオーガニックデータソースに基づいて事前トレーニングを行うのに対し、phi-4はトレーニングプロセス全体にわたって戦略的に合成データを組み込んでいます。
Phiファミリーの以前のモデルが主に教師モデル(特にGPT-4)の能力を蒸留するのに対し、phi-4はSTEMに焦点を当てたQA能力において教師モデルを大きく上回り、データ生成およびポストトレーニング技術が蒸留を超えていることを証明しています。phi-3のアーキテクチャに対する変更は最小限ですが、phi-4はデータ、トレーニングカリキュラム、ポストトレーニングスキームの革新により、特に推論に焦点を当てたベンチマークに対して、サイズに対して強力なパフォーマンスを達成しています。
以下は、提供された情報を基にした論文「phi-4」に関する解説です。各章の内容を簡潔にまとめ、技術的な詳細を明らかにしています。
1. はじめに
1.1 概要
本論文では、phi-4という14億パラメータの言語モデルを紹介します。phi-4はデータ品質を重視し、合成データを戦略的に取り入れたトレーニング方法を採用しています。このモデルは、特にSTEM分野に特化した質問応答能力において、従来の教師モデルであるGPT-4を上回る性能を示しています。
2. データへのアプローチ
2.1 合成データの目的
phi-4のトレーニングにおいて、合成データは非常に重要です。合成データはトークン間の関係が明確であり、モデルの効率的な学習を支援します。具体的には、以下の原則が考慮されています:
- 多様性: サブトピックやスキルを網羅
- ニュアンスと複雑性: 複雑な例を含む
- 正確性: 知識に基づく
- チェイン・オブ・ソート: 系統的な推論を促進
2.2 プレトレーニングおよびミッドトレーニング
約50種類の合成データセットを生成し、合計で約400Bのトークンを使用しました。主な生成手法には、データ収集と質問-回答ペアの生成が含まれます。
2.3 ウェブおよびQ&Aデータのキュレーション
高品質なオーガニックデータを収集し、推論に富む資料を優先的にトレーニングに利用します。
3. プレトレーニングの詳細
3.1 データ構成
phi-4は、合成データとフィルタリングされたウェブデータを混合して使用します。このデータ構成により、モデルは推論能力を強化し、競争力を持たせています。
3.2 データ混合比率
- 合成データ: 40%
- ウェブおよびリライトデータ: 30%
- コードデータ: 20%
- ターゲット取得データ: 10%
4. ポストトレーニング
4.1 教師ありファインチューニング
多様なデータセットを使用して、約80億トークンでモデルをファインチューニングします。
4.2 直接的な好み最適化
DPOを用いてモデルを人間の好みに調整し、出力の質を向上させます。
5. ベンチマークに関する考慮
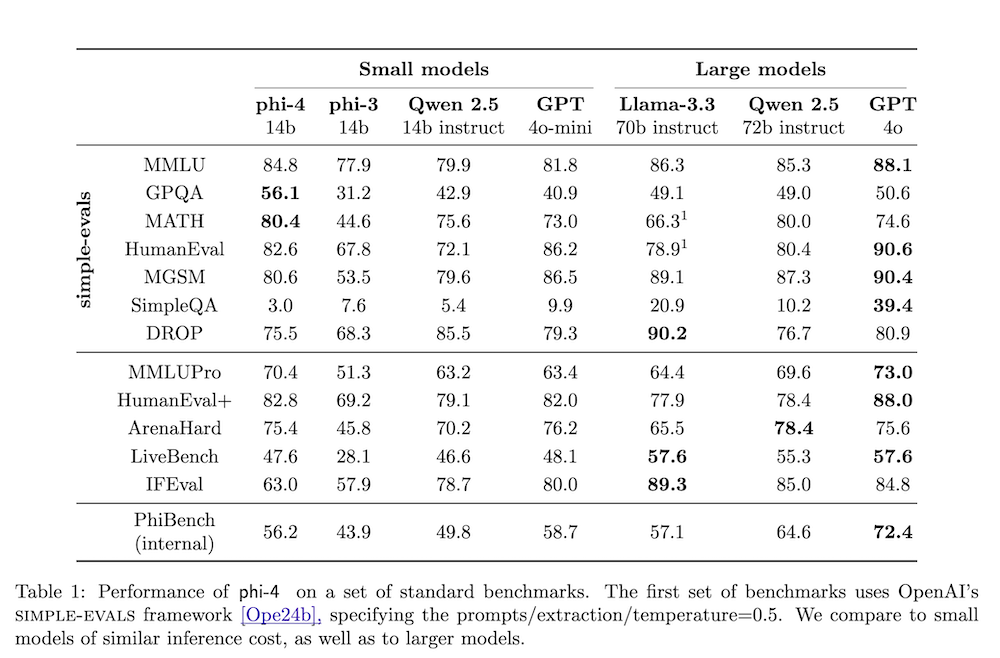
内部ベンチマーク「PhiBench」を使用して、モデルの多様な能力を評価します。これにより、モデルの推論能力を測ることができます。
6. 主要ベンチマークでの性能
phi-4はSTEM関連の質問応答や数学タスクにおいて、特に優れた結果を示しています。
7. 安全性
phi-4はMicrosoftの責任あるAI原則に従い、安全性の調整やリスクテストを行っています。
8. 課題
phi-4には、タスクにおけるサイズの制約や幻覚の生成といった限界があります。これらの課題克服にはさらなるデータ強化が必要です。
A. 付録
A.1 幻覚を避けるためのデータ生成
難問に対しては「わからない」と返答するようトレーニングされています。
A.2 データ処理
データのデコンタミネーションプロセスが整備されており、トレーニングとテストデータの間の不正な影響を最小限に抑えています。