目次
Autoregressive Models in Vision: A Survey
この論文は、視覚分野における自己回帰モデルの進展と応用を包括的に調査し、さまざまな表現戦略や生成タスクへの適用についてまとめたものです。
この論文は、視覚データにおける自己回帰モデルの多様な表現戦略をピクセル、トークン、スケールの3つに分類し、それぞれの特性や応用を詳述することで、視覚生成の新たな可能性を示唆しています。
論文:https://arxiv.org/abs/2411.05902
リポジトリ:https://github.com/ChaofanTao/Autoregressive-Models-in-Vision-Survey
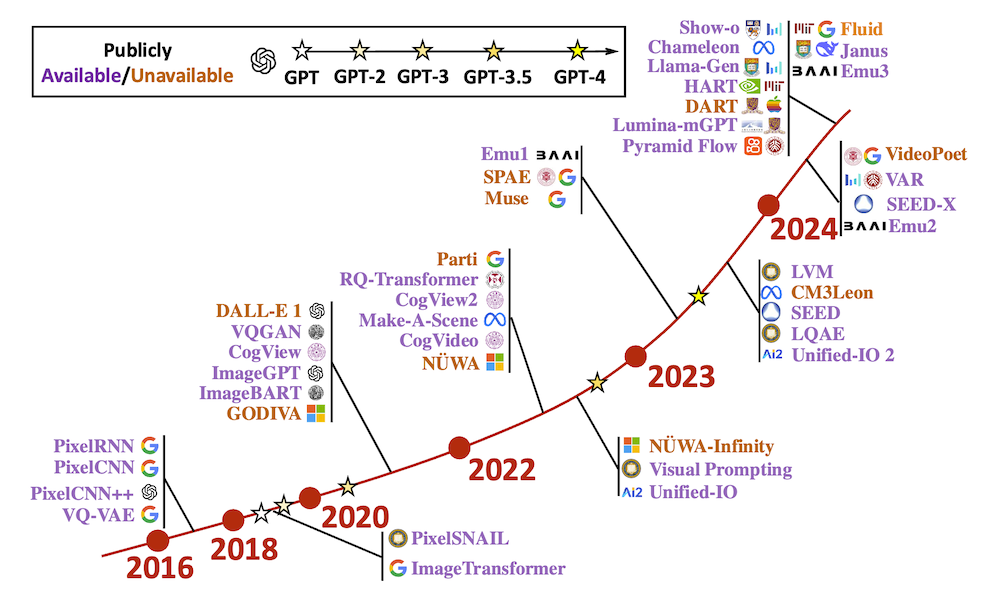
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
自己回帰モデルは自然言語処理(NLP)の分野で大きな成功を収めてきました。最近、自己回帰モデルはコンピュータビジョンにおいても重要な焦点となり、高品質な視覚コンテンツの生成において優れた性能を発揮しています。NLPにおける自己回帰モデルは通常、サブワードトークンに基づいて動作しますが、コンピュータビジョンにおける表現戦略はピクセルレベル、トークンレベル、またはスケールレベルなど異なるレベルで変化し、視覚データの多様で階層的な性質を反映しています。
本調査は、視覚に応用された自己回帰モデルに関する文献を包括的に検討します。異なる研究背景を持つ研究者にとって読みやすくするために、まず視覚における初歩的なシーケンス表現とモデリングから始めます。次に、視覚自己回帰モデルの基本的なフレームワークを、表現戦略に基づいてピクセルベース、トークンベース、スケールベースの3つの一般的なサブカテゴリーに分けて説明します。その後、自己回帰モデルと他の生成モデルとの相互関係を探ります。
さらに、画像生成、動画生成、3D生成、マルチモーダル生成など、コンピュータビジョンにおける自己回帰モデルの多面的な分類を提示します。また、実体AIや3D医療AIなどの新たな分野における応用についても詳述し、約250件の関連文献を引用しています。最後に、視覚における自己回帰モデルの現在の課題を強調し、将来の研究方向について提案します。また、この調査に含まれる論文を整理するためのGithubリポジトリも設けています。
以下は、自己回帰モデルに関する論文の内容を各章ごとにまとめた解説記事です。
1. 自己回帰モデルのビジョンに関する調査
1.1 はじめに
自己回帰モデルは、自然言語処理(NLP)での成功を受けて、コンピュータビジョンにおいても注目されています。この手法は、データ生成において各要素を前の要素に基づいて予測するものであり、高品質な視覚コンテンツの生成において優れた性能を発揮します。特に、視覚データの多様性と階層的特性を考慮し、ピクセルベース、トークンベース、スケールベースの異なる表現戦略を用います。
1.2 自己回帰モデルの重要性と適用範囲
自己回帰モデルは、画像生成、動画生成、3D生成、マルチモーダル生成など幅広いタスクに適用されています。これにより、自己回帰モデルの最新の進展を把握することが重要です。
2. 自己回帰モデルの基礎
2.1 前提
視覚自己回帰モデルは、視覚要素を逐次的に予測する生成モデルであり、各予測は前に生成された要素に条件付けられます。
2.2 一般的なフレームワーク
視覚自己回帰モデルは、以下の3つのカテゴリに分類されます:
- ピクセルベースモデル:視覚データをピクセル単位で直接表現し、PixelRNNやPixelCNNが代表的です。
- トークンベースモデル:画像を離散的なトークンのシーケンスに圧縮し、VQ-VAEがこの手法の一例です。
- スケールベースモデル:VARモデルを用いて粗から細へと視覚コンテンツを生成します。
2.3 他の生成モデルとの関係
自己回帰モデルは、変分オートエンコーダ(VAE)、生成敵対ネットワーク(GAN)、正規化フロー、拡散モデルといった他の生成モデルと関連しており、相互に強化し合う可能性があります。
3. 視覚自己回帰モデル
3.1 画像生成
画像生成は、自己回帰モデルの重要な応用であり、無条件生成と条件生成に分かれます。
- 無条件画像生成:特定の入力なしで画像を生成します。
- 条件画像生成:テキストや他の入力に基づいて画像を生成します(例:DALL·EやCogView)。
3.2 動画生成
動画生成は、時間的な動態を捉えることが求められるタスクで、無条件動画生成と条件動画生成が存在します。
- 無条件動画生成:特定の条件なしに動画を生成します。
- 条件動画生成:特定の入力に基づいて動画を生成します。
3.3 3D生成
3D生成は、ゲームや医療画像の生成に関連し、自己回帰モデルを使って複雑な3D構造を生成します。
3.4 マルチモーダル生成
視覚とテキストデータを統合してよりリッチなコンテンツを生成する手法で、自己回帰型モデルと大規模言語モデル(LLMs)の統合が進んでいます。
4. 評価指標
視覚自己回帰モデルの評価には、再構成の忠実度、視覚的品質、多様性、意味的一貫性、時間的一貫性などが含まれ、PSNR、SSIM、FIDなどの具体的な指標が用いられます。
5. 課題と今後の研究方向
自己回帰モデルの進展には、強力なトークナイザーの設計、離散表現と連続表現の選択、アーキテクチャにおける帰納的バイアスの統合など、多くの課題が存在します。これらを克服することで、性能と応用範囲が拡大することが期待されています。
6. 結論
この調査は、コンピュータビジョンにおける自己回帰モデルの全体像を提供し、ピクセルベース、トークンベース、スケールベースのアプローチを通じて、それぞれの特性と応用を明らかにしました。今後の研究は、これらのモデルの限界を克服し、より効果的な生成手法を開発することに焦点を当てるべきです。