目次
LLaVA-o1: Let Vision Language Models Reason Step-by-Step
この論文は、LLaVA-o1という新しい視覚言語モデルが、複雑な視覚的質問応答タスクにおいて段階的な推論を自律的に行う能力を向上させることを提案しています。
論文:https://arxiv.org/abs/2411.10440
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
大規模言語モデルは、特に推論時のスケーリングを通じて、推論能力の大幅な進展を示していますが、現在の視覚言語モデル(VLM)は、特に複雑な視覚的質問応答タスクを扱う際に、体系的で構造的な推論を行うのが難しいことが多いです。
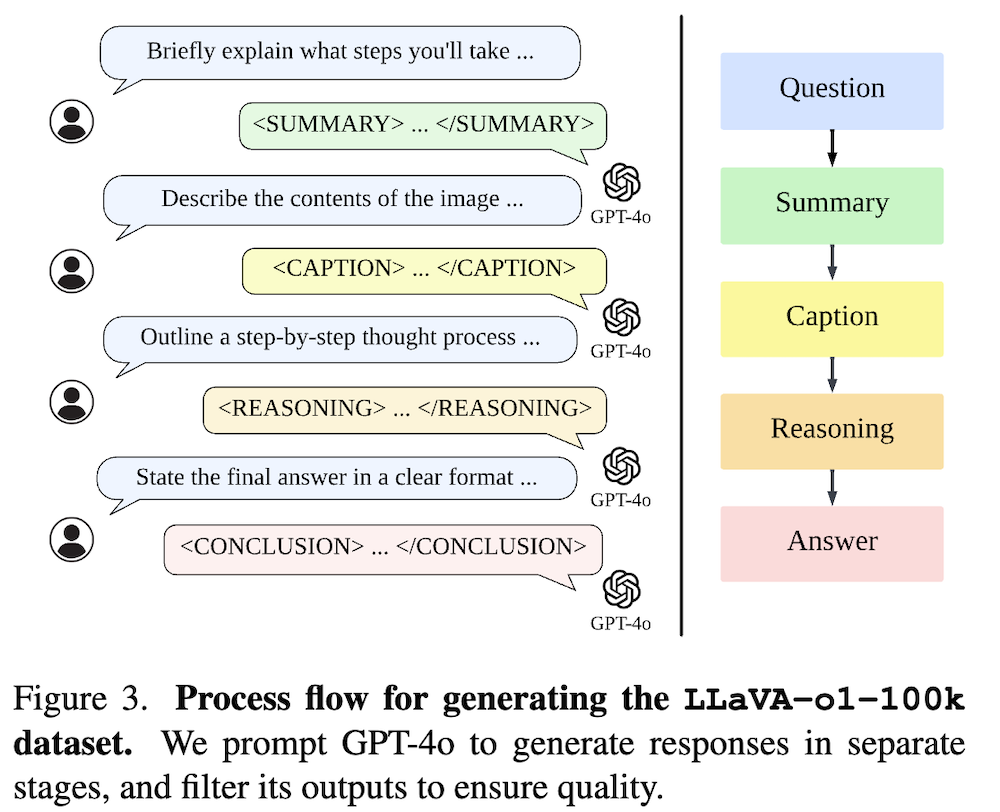
本研究では、独立して段階的な要約、視覚的解釈、論理的推論、結論の生成を行う新しいVLMであるLLaVA-o1を紹介します。この構造化されたアプローチにより、LLaVA-o1は推論集約型タスクにおいて精度を大幅に向上させることが可能となります。さらに、LLaVA-o1-100kデータセットを編纂し、さまざまな視覚的質問応答ソースからのサンプルを統合し、構造化された推論注釈を提供します。
また、効果的な推論時スケーリングを可能にする段階レベルのビームサーチ方法を提案します。驚くべきことに、わずか100kのトレーニングサンプルとシンプルで効果的な推論時スケーリング手法を用いて、LLaVA-o1は広範なマルチモーダル推論ベンチマークで基盤モデルを8.9%上回るだけでなく、Gemini-1.5-pro、GPT-4o-mini、Llama-3.2-90B-Vision-Instructなどのより大きなモデルやクローズドソースモデルの性能も超えています。
LLaVA-o1は、段階的な推論を独立して行う能力を持ち、従来の視覚言語モデルに比べて複雑なタスクにおいて精度を劇的に向上させる新しいアプローチを提供します。
1. LLaVA-o1: 段階的推論を行う視覚と言語モデル
1.1 はじめに
本章では、視覚と言語モデル(VLM)であるLLaVA-o1の背景と目的を説明します。近年の大規模言語モデル(LLM)は推論能力において著しい進展を遂げていますが、従来のVLMは複雑な視覚的質問応答タスクにおいて体系的な推論が難しいという課題があります。LLaVA-o1は、これらの問題を解決するために設計され、独立した多段階の推論を行う能力を持っています。
1.2 既存の課題
従来のモデルは、特に複雑なタスクに対する論理的推論において制約があります。LLaVA-o1は、要約、視覚解釈、論理的推論、結論生成の各段階を独立して実行することで、推論の精度を大幅に向上させることを目指しています。
2. 方法論
2.1 データセットの構築
LLaVA-o1の訓練には、LLaVA-o1-100kデータセットを使用します。このデータセットは、視覚的質問応答に関する多様なソースからサンプルを収集し、構造化された推論アノテーションを提供しています。これにより、モデルはさまざまな推論シナリオに対応できるようになります。
2.2 推論手法
推論時には、段階的なビームサーチ法を導入しています。この手法により、各推論段階の効率的なスケーリングが可能となり、モデルのパフォーマンスを最大化します。各段階の出力を次の段階の入力として使用することで、推論精度が向上します。
2.3 実験設定
LLaVA-o1は、100,000のトレーニングサンプルを用いて訓練され、多様なマルチモーダル推論ベンチマークで基本モデルに対して8.9%の性能向上を達成しました。この実験設定は、モデルの有効性を示す重要な要素です。
3. 結果
3.1 性能評価
LLaVA-o1は、Gemini-1.5-pro、GPT-4o-mini、Llama-3.2-90B-Vision-Instructなどの大規模モデルを超える性能を示しました。この成果は、推論の構造化と段階的なアプローチがVLMの能力を大幅に向上させることを示しています。
4. 結論
LLaVA-o1は、視覚と言語モデルにおける新たな推論手法を提示し、従来のモデルと比較して顕著な性能向上をもたらしました。今後の研究では、このアプローチをさらに発展させ、他の応用分野への適用も探求することが期待されます。