目次
OPEN SCHOLAR: Synthesizing Scientific Literature with Retrieval-Augmented LMs
この論文は、科学文献の合成を支援するために、大規模言語モデル(LM)を利用した「OPEN SCHOLAR」という新しいリトリーバル拡張型LMの開発と評価を行い、その効果を示すための大規模なベンチマーク「SCHOLAR QABENCH」を紹介しています。
論文:https://arxiv.org/abs/2411.14199
リポジトリ:https://github.com/AkariAsai/OpenScholar
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
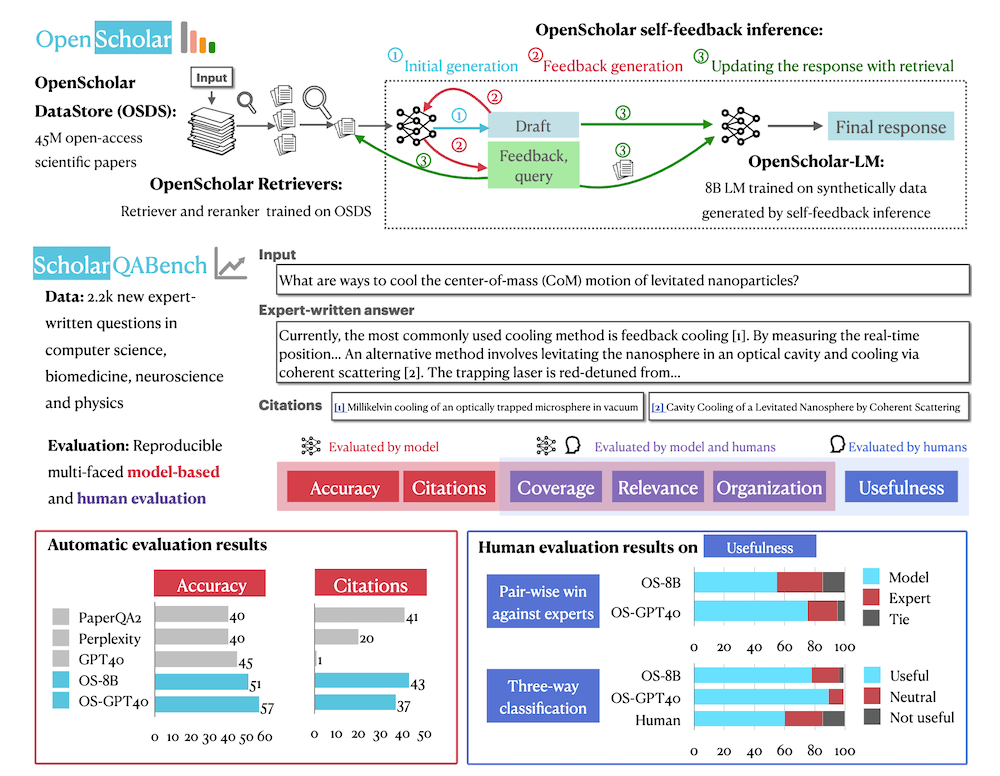
この論文では、科学文献の統合を支援するための新しいリトリーバル強化型言語モデル「OPEN SCHOLAR」を紹介しています。4,500万のオープンアクセス論文から関連するパッセージを特定し、引用に基づいた応答を生成する能力を持っています。評価のために、コンピュータサイエンス、物理学、神経科学、バイオメディスンの分野での2967の専門家による質問と208の長文回答から成る「SCHOLAR QABENCH」ベンチマークを開発しました。実験結果では、OPEN SCHOLARが他のモデルよりも高い正確性を示し、専門家による評価でも高く評価されました。この研究は、科学文献のレビューを自動化する新たな手段を提供し、今後の研究を支援するために、すべてのコード、モデル、データストアをオープンソース化しています。
OPEN SCHOLARは、4,500万のオープンアクセス論文を活用して、科学的な質問に対して引用付きの高精度な応答を生成するリトリーバル強化型言語モデルであり、専門家による評価で他のモデルを上回る性能を示しました。
以下に、提供された情報を基にした論文の解説記事を章ごとにまとめた内容を示します。
1. はじめに
1.1 研究の背景
科学的文献の統合は、新たな研究の方向性を見出し、方法論を洗練させ、証拠に基づく意思決定を支えるために不可欠です。しかし、毎年発表される膨大な論文の量により、研究者が最新の情報を把握することはますます困難になっています。効果的な統合には、正確な情報の取得と引用、最新の文献へのリアルタイムアクセスが必要です。大型言語モデル(LLM)が研究者の支援に期待されていますが、事実と異なる情報の生成や古いデータへの依存、透明性の欠如といった課題もあります。
1.2 目的
本研究では、科学的な問いに答えるために、4500万件のオープンアクセス論文から関連する文章を特定し、引用に基づいた応答を生成する特化型の検索強化型言語モデル「OPEN SCHOLAR」を提案します。このモデルの効果を評価するために、初めての大規模マルチドメインベンチマーク「SCHOLAR QABENCH」を開発しました。
2. OPEN SCHOLAR: 科学文献を統合するための検索強化型言語モデル
2.1 OPEN SCHOLARの構成
OPEN SCHOLARは、科学文献に関する情報探索と統合を促進するために設計されたリトリーバル強化型言語モデルです。データストア、リトリーバー、生成器の3つの主要コンポーネントから構成され、ユーザーの科学的クエリに応じて関連する論文を特定し、それらの知見を統合して応答を生成します。
2.2 リトリーバルパイプライン
OPEN SCHOLARのリトリーバルパイプラインは、次のステップで構成されます:
1. データストアからの初期候補の取得
2. クロスエンコーダを使用した再ランキング
3. 取得したパッセージを基にした応答生成
2.3 自己フィードバックによる反復生成
初期応答を生成した後、OPEN SCHOLARは自己フィードバックを生成し、応答を反復的に改良します。このプロセスにより、出力の質が向上し、引用の正確性が確保されます。
3. SCHOLAR QABENCH: 実用的な文献レビュー評価ベンチマーク
3.1 課題と概要
従来の文献レビューの評価は小規模で単一のドメインに限られていましたが、SCHOLAR QABENCHは、文献レビューの自動化能力を評価するために設計されたベンチマークです。コンピュータサイエンス、物理学、神経科学、バイオメディスンの4つのドメインを対象としています。
3.2 評価メトリクスと評価プロトコル
評価メトリクスは、引用の正確性、事実の正確性、内容のカバレッジ、全体的な質を測定するために設計されています。自動評価と専門家評価を組み合わせた多面的な評価プロトコルを導入し、再現性のある評価を実現しています。
4. 実験と結果
4.1 実験の詳細
OPEN SCHOLARの効果を評価するために、さまざまなオープンモデルやプロプライエタリな言語モデルを使用した実験が行われました。具体的には、Llama 3.1やGPT-4oなどが含まれ、各モデルが生成した回答の正確性を確認しました。
4.2 結果
OPEN SCHOLARは、他のモデルと比較して一貫して高いパフォーマンスを示し、特に引用の正確性や情報カバレッジの面で優れた成績を収めました。この結果は、文献レビューを行う際の効率性を向上させることを示しています。
5. 専門家評価
人間の専門家による評価では、OPEN SCHOLARが生成した応答が専門家の回答よりも優れていることが示されました。具体的には、専門家評価でOPEN SCHOLARは51%の確率で人間の回答を上回る結果が得られました。
6. まとめ
本研究は、OPEN SCHOLARとSCHOLAR QABENCHを通じて、科学文献レビューの自動化を支援するための手法を提案しました。OPEN SCHOLARは、文献の統合において高い性能を示し、特に引用の正確性において従来のモデルを上回る結果を示しています。これにより、科学研究の進展を促進する新たなツールが提供されました。
付録
A. 公開されたアーティファクト
公開デモや関連するコード、データセットが提供されており、今後の研究を加速させるための基盤が整えられています。
B. SCHOLAR QABENCHの詳細
データキュレーションや評価メトリクスの詳細について説明されています。
C. OPEN SCHOLARの詳細
リトリーバルモデルや生成モデルのトレーニングに関する詳細が記載されています。