目次
AssistRAG: Boosting the Potential of Large Language Models with an Intelligent Information Assistant
この論文は、知能情報アシスタントを統合することで大規模言語モデルの情報検索と意思決定能力を向上させる「AssistRAG」という手法を提案しています。
論文:https://arxiv.org/abs/2411.06805
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文「AssistRAG: 大規模言語モデルの可能性をインテリジェントな情報アシスタントで強化する」は、自然言語処理における大規模言語モデル(LLMs)の進展を背景に、これらのモデルが生成する事実誤認(ハルシネーション)に対処するための新しいアプローチを提案しています。従来の情報検索強化生成(RAG)手法では複雑な推論タスクに対応できず、プロンプトベースのRAG戦略や監視付きファインチューニング(SFT)も頻繁な再学習が必要でした。そこで、AssistRAGはインテリジェントな情報アシスタントをLLMsに統合し、記憶管理や知識構築を行い、情報検索と意思決定を強化します。実験結果は、AssistRAGが特に発展途上のLLMに対して優れた推論能力と正確な応答を提供し、ベンチマークを大きく上回ることを示しています。
AssistRAGは、インテリジェントな情報アシスタントを導入することで、従来の大規模言語モデルの誤情報生成を抑制し、特に発展途上のモデルにおいて高い推論能力と正確性を実現する点が特徴です。
以下に、各章ごとに内容をまとめた解説を示します。
1. はじめに
1.1 背景
大規模言語モデル(LLMs)の進展により、自然言語処理の分野は大きく進化しました。しかし、これらのモデルは「ハルシネーション」と呼ばれる問題、つまり事実と異なる情報を生成する傾向があり、特に複雑な推論タスクにおいてはその性能が不十分であることが指摘されています。
1.2 従来のアプローチの限界
初期の情報検索を強化した生成(RAG)手法である「Retrieve-Read」フレームワークは、複雑な推論において効果が不十分でした。その後のプロンプトベースのRAG戦略や監視付きファインチューニング(SFT)手法は性能向上に寄与しましたが、頻繁な再訓練が必要であり、基盤となるLLMの能力を変えてしまうリスクが存在します。
2. AssistRAGの提案
2.1 AssistRAGの概要
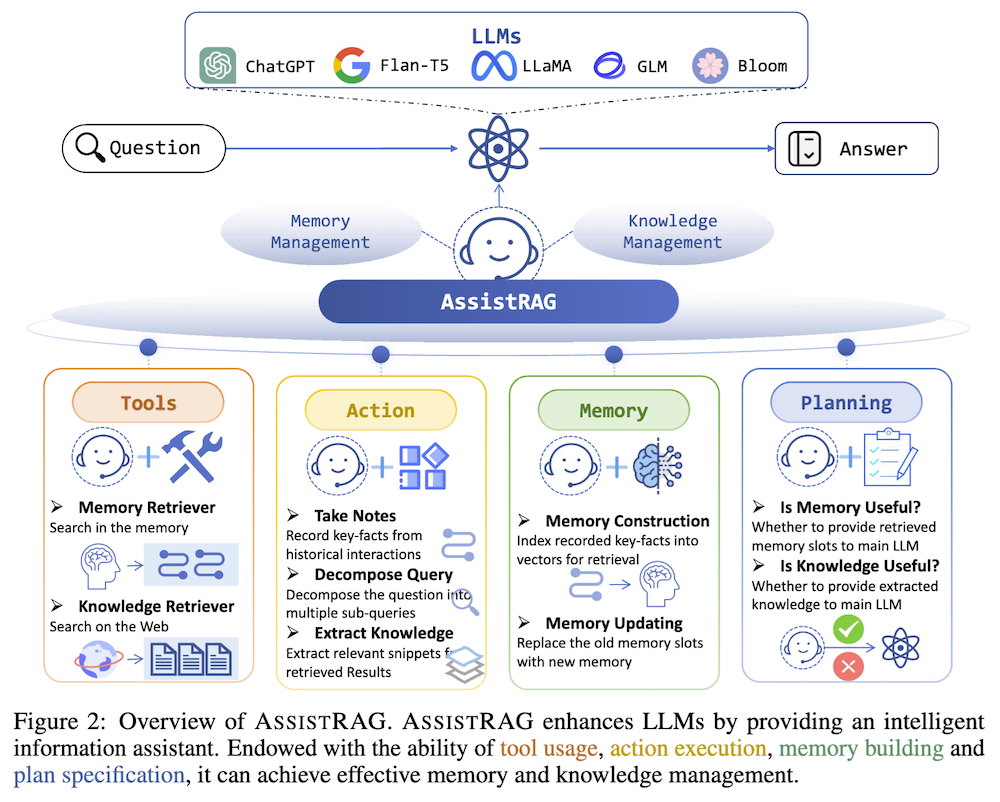
AssistRAGは、LLM内にインテリジェントな情報アシスタントを統合することで、情報の取得と意思決定を向上させる新たな手法です。このアシスタントは、ツールの使用、アクションの実行、記憶の構築、計画の仕様を通じて知識を管理します。
2.2 トレーニング手法
AssistRAGは二段階のトレーニングアプローチを採用しています。第一に「カリキュラムアシスタント学習」を用いて段階的に難易度を上げることでモデルの学習効率を高め、第二に「強化された嗜好最適化」によりアシスタントの行動を最適化し、利用者の意図に沿った情報提供を実現します。
3. 実験と結果
3.1 実験設定
AssistRAGの有効性を評価するために、様々なベンチマークに対して実験が行われました。これにより、AssistRAGが従来の手法と比較して優れた推論能力と正確な応答を提供することが実証されました。
3.2 結果と考察
実験の結果、AssistRAGは特に複雑な推論を要するタスクにおいて他の手法と比べて大幅に性能が向上しました。この改善は、アシスタントによる情報管理が情報取得の精度を高めることに寄与していることを示唆しています。
4. 結論
4.1 研究の意義
AssistRAGは、LLMの能力を最大限に引き出す新しいアプローチを提供し、特に情報取得や推論タスクにおける性能向上が期待されます。
4.2 今後の展望
今後の研究では、AssistRAGのさらなる最適化や、異なるドメインや言語への適用可能性を探求することが重要です。これにより、より広範な利用が見込まれます。