目次
GUI Agents with Foundation Models: A Comprehensive Survey
この論文は、基盤モデルを用いたGUIエージェントの最新の研究を調査し、データ、フレームワーク、アプリケーションに関する知見や今後の課題をまとめた包括的な調査です。
論文:https://arxiv.org/abs/2411.04890
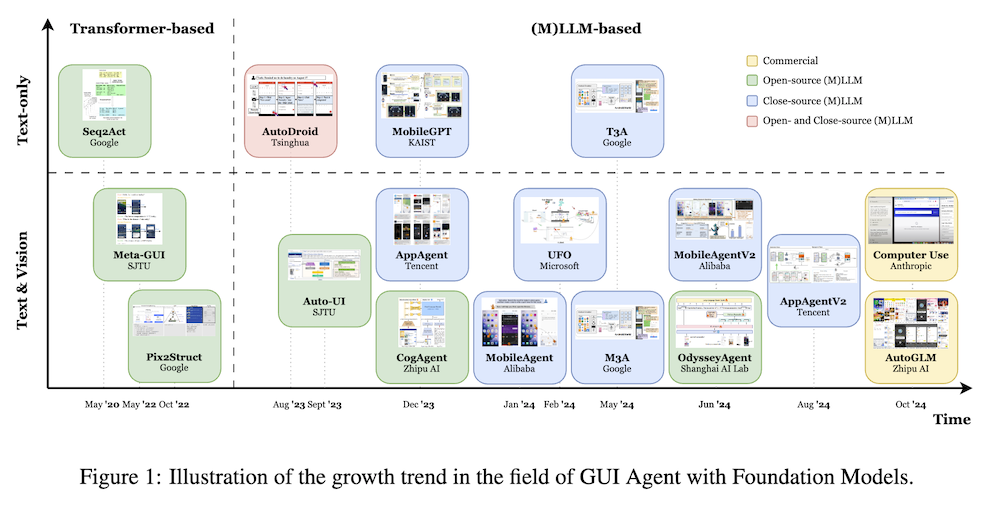
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文は、基盤モデルを用いたGUIエージェントに関する包括的な調査を行っています。近年の大規模言語モデル(LLM)やマルチモーダル大規模言語モデル(MLLM)の進展により、これらのエージェントはユーザーの指示を理解し、自律的に実行する能力を持つようになりました。著者たちは、データセット、フレームワーク、アプリケーションの観点から既存の研究を整理し、主要な課題や将来の研究方向を提案しています。この調査は、GUIエージェントの発展を促進し、さらなる研究を刺激することを目的としています。最終的に、GUIエージェントの研究を進めるための重要なリソースと洞察を提供しています。
この論文の特徴は、基盤モデルを活用したGUIエージェントの研究をデータセット、フレームワーク、アプリケーションの具体的な例を通じて体系的に整理し、今後の研究課題と方向性を明示することで、迅速な技術革新と実用化を促進するための貴重なリソースを提供している点です。
以下は、提供された複数のエージェントの出力を統合し、論文について各章ごとにまとめたものです。
1. GUIエージェントの基礎モデルに関する包括的調査
1.1 背景
GUI(グラフィカルユーザーインターフェース)エージェントは、ユーザーとデジタルデバイスとの主要なインタラクションポイントとして機能します。最近の大規模言語モデル(LLM)およびマルチモーダル大規模言語モデル(MLLM)の進展により、これらのエージェントは複雑なタスクを自律的に実行する能力を獲得しています。
1.2 目的
本論文の目的は、(M)LLMに基づくGUIエージェントに関する最近の研究を総括し、データ、フレームワーク、アプリケーションの観点から整理することです。
2. GUIエージェントのデータソース
2.1 データセットの分類
GUIエージェントの訓練と評価のために開発されたデータセットは、主に静的データセットと動的データセットに分類されます。
- 静的データセット: 例として「Android in the Wild」があり、ユーザーの指示やタスクデモを含む。
- 動的データセット: 「WebArena」や「AndroidWorld」のようなデータセットは、実環境でのインタラクションを通じてデータを生成し、タスクを評価します。
3. (M)LLMベースのGUIエージェント
3.1 構成要素
(M)LLMベースのGUIエージェントは、以下の五つの主要な部分から構成されます。
- GUI Perceiver: ユーザー入力を解釈し、UIの変化を検出します。
- Task Planner: 複雑なタスクを効果的に分解します。
- Decision Maker: 次の操作を決定します。
- Memory Retriever: タスクを実行するための情報を提供します。
- Executor: 出力をデバイス環境にマッピングします。
3.2 分類
GUIエージェントは、入力モダリティと学習モードの二つの次元で分類されます。
- 入力モダリティ: LLMベース(テキストベースの入力)とMLLMベース(画像認識能力を活用)に分けられます。
- 学習モード: プロンプトベース(少ない計算オーバーヘッド)とSFT(自己教師あり学習)ベース(特定のドメインに適応)があります。
4. (M)LLMベースのGUIエージェントの産業応用
具体的な応用例として、Google AssistantやApple Intelligenceがあり、ユーザーの指示に基づいてタスクを自動化します。これらのツールは、ユーザーの操作を効率化し、様々なアプリケーションでの利用が進んでいます。
5. 課題
(M)LLMベースのGUIエージェントには、以下のような課題があります。
- ベンチマークと現実とのギャップ
- 自己進化の実現
- 推論の効率性向上
6. 結論
本論文では、(M)LLMベースのGUIエージェントに関する研究を体系的にレビューし、データソース、構成、アプリケーションの観点から考察を行いました。今後の研究の方向性として、これらの課題を克服するためのアプローチを提案し、さらなる発展を促進することを目指しています。