目次
HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems
この論文は、Retrieval-Augmented Generation(RAG)システムにおいて、取得した知識の形式としてプレーンテキストの代わりにHTMLを使用することが、情報の構造と意味をより豊かに保持できることを示す研究です。
論文:https://arxiv.org/abs/2411.02959
リポジトリ:https://github.com/plageon/HtmlRAG
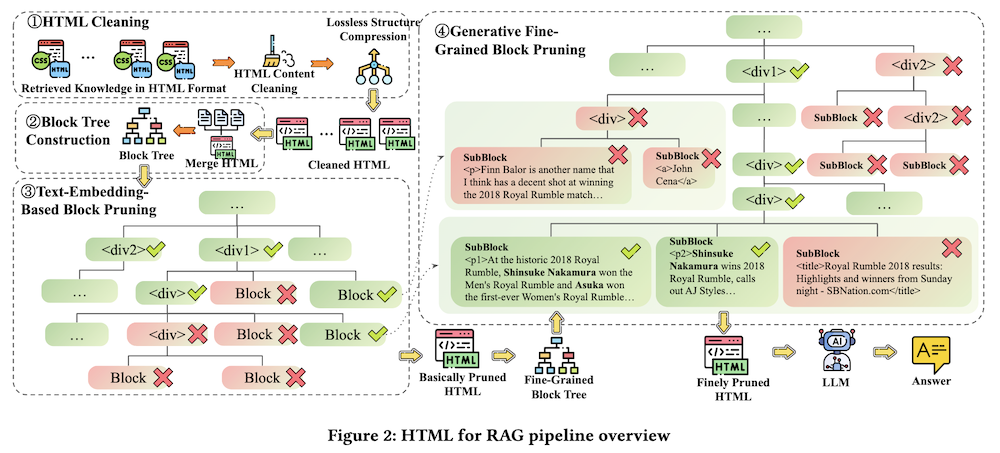
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文では、Retrieval-Augmented Generation(RAG)システムにおいて、取得した知識をプレーンテキストの代わりにHTML形式でモデル化する「HtmlRAG」を提案しています。従来のRAGシステムではHTMLからプレーンテキストが抽出されるため、構造的および意味的情報が失われていました。HtmlRAGは、HTMLの特性を活かしつつ、不要なトークンやノイズを減らすためにHTMLのクリーニング、圧縮、プルーニングを行います。実験結果は、HTMLを使用することでRAGシステムの性能が向上することを示しています。この研究は、HTMLを外部知識の形式として利用する新たな方向性を開き、RAGシステムにおける知識処理の改善を目指しています。
HtmlRAGは、HTMLの構造と意味的情報を保持することで、従来のプレーンテキストベースのRAGシステムに比べて情報の損失を大幅に減少させ、生成された応答の質を向上させる新しいアプローチを提供します。
1. はじめに
1.1 背景
大規模言語モデル(LLMs)は、自然言語処理の多様なタスクにおいて顕著な性能を発揮しますが、長期的な知識の忘却や誤情報生成(幻覚)が問題とされています。このような課題を克服する手法として、Retrieval-Augmented Generation(RAG)が注目されています。RAGは、外部知識を活用することでLLMの性能を向上させることを目的としています。
1.2 問題提起
従来のRAGシステムは、HTML文書をプレーンテキストに変換する過程で、HTML特有の構造や意味の情報が失われることが課題です。本論文では、HTMLをRAGシステムの外部知識の形式として利用する新たなアプローチを提案します。
1.3 目的
本研究の目的は、HTMLを効果的に利用し、RAGシステムにおける情報保持を向上させる手法、HtmlRAGを提案することです。
2. 関連研究
2.1 Retrieval-Augmented Generation (RAG)
RAGシステムは、クエリリライター、リトリーバー、リランカー、リファイナー、リーダーなどのコンポーネントから成り立っています。多くの研究がこのフレームワークの最適化に取り組んでおり、特に外部知識の形式としてプレーンテキストが一般的に利用されています。
2.2 RAGのポストリトリーバルプロセス
ポストリトリーバルプロセスは、取得された情報から有用なコンテンツを抽出し、LLMに送信するための入力コンテキストを短縮します。しかし、従来のプロセスはHTMLの構造を考慮していないため、特有の問題が生じます。
2.3 構造化データ理解
構造化データはプレーンテキストよりも豊富な情報を提供できるため、本研究ではHTMLをRAGシステムにおける新しいデータ形式として提案します。
3. 方法論
3.1 問題定義
RAGパイプラインにおいて、リトリーバーはHTML文書を取得し、LLMはその情報を基に回答を生成します。この過程で、HTML文書の長さがLLMの最大コンテキストウィンドウを超えないようにすることが求められます。
3.2 HTMLクリーニング
HTML文書は通常、冗長であるため、無関係な要素やタグを削除するルールベースのクリーニングを実施します。具体的には、CSS、JavaScript、コメントを削除し、冗長な構造を圧縮します。
3.3 ブロックツリーの構築
HTML文書を連結し、Beautiful Soupを用いてDOMツリーを構築します。ノードを階層的なブロックにマージすることで、計算コストを削減します。
3.4 ブロックツリーに基づくHTMLプルーニング
HTMLプルーニングは、テキスト埋め込みモデルを使用したブロックの関連性スコア計算と、生成モデルを用いた細粒度のプルーニングの二段階で行います。
4. 実験
4.1 データセット
ASQA、Hotpot-QA、NQ、Trivia-QA、MuSiQue、ELI5の6つのデータセットを用いて実験が行われました。
4.2 評価指標
各データセットに応じた評価指標を設定し、HtmlRAGの効果を測定します。
4.3 ベースライン
HtmlRAGは従来のプレーンテキストやMarkdown形式に基づくベースラインと比較され、その優位性が示されました。
4.4 実験結果
HtmlRAGは全てのデータセットでベースラインを上回る結果を示し、HTMLの利用がRAGシステムにおいて有効であることが確認されました。
5. 結論と今後の課題
本研究は、HTMLをRAGシステムの外部知識の形式として採用し、その情報を保持するための手法を提案しました。HtmlRAGは、従来のプレーンテキストに基づくプロセスを凌駕することが実験により確認され、今後の研究方向性に新たな視点を提供します。
付録
A. 生成モデルのトレーニング詳細
生成モデルのトレーニングに関するハイパーパラメータや設定の詳細が含まれています。
B. 主要アルゴリズム
ブロックツリー構築や、埋め込みモデル、生成モデルによるプルーニングのアルゴリズムが擬似コードで示されています。