目次
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
この論文は、オープンソースの高性能コード大型言語モデル「OpenCoder」を提案し、その透明性と再現性のある訓練プロセスを通じて、コード生成やプログラミングタスクにおける研究を促進することを目的としています。
論文:https://arxiv.org/abs/2411.04905
リポジトリ:https://opencoder-llm.github.io
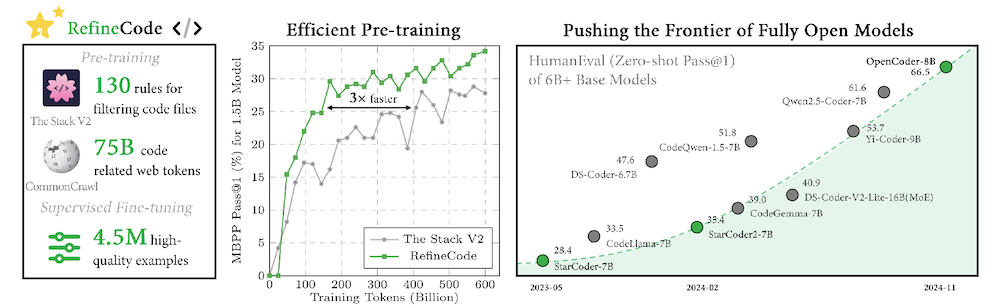
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文では、コード生成や推論タスク、エージェントシステムなどに不可欠な大規模言語モデル(LLM)の開発に関する新しいオープンソースモデル「OpenCoder」を提案しています。OpenCoderは、従来のプロプライエタリモデルに匹敵する性能を持ちながら、研究コミュニティ向けに透明性のあるデータ処理パイプラインやトレーニングプロトコルを提供します。また、データクレンジングや重複排除のための最適化されたヒューリスティックルール、高品質な合成データを用い、トップクラスのコードLLMを構築するための重要な要素を示しています。この取り組みにより、OpenCoderはオープンソースコードLLMの成長を促進し、再現性のある研究の進展を可能にすることを目指しています。最終的に、OpenCoderは、科学研究のための強力な基盤として機能し、コードAIの分野での進展を加速することを目指しています。
以下に、論文の各章についてまとめました。
1. はじめに
1.1 大規模言語モデルの重要性
大規模言語モデル(LLMs)は、特にコード生成や推論タスク、エージェントシステムにおいて重要な役割を果たしています。これにより、ソフトウェア開発のプロセスが革新されていますが、オープンソースのモデルは依然として最先端の性能に達していないという課題があります。
1.2 Open-Coderの目的
本研究では、Open-Coderというオープンアクセスの高品質なコードLLMを提案します。このモデルは、再現可能なトレーニングデータやデータ処理パイプラインを提供することで、研究コミュニティの透明性と再現性を向上させることを目指しています。
2. プレトレーニングデータ
2.1 RefineCode
RefineCodeは、9600億トークンを含む高品質なデータセットで、607のプログラミング言語をサポートしています。このデータは主にGitHubリポジトリから集められた生コードと、ウェブデータからのコード関連データで構成されています。
2.1.1 生コード
データ処理パイプラインでは、ファイルサイズが8MBを超えるものを除外し、プログラミング言語に関連しないファイルも排除します。前処理、重複排除、データサンプリングを通じて高品質なコードデータを確保します。
2.1.2 コード関連ウェブデータ
Common Crawlデータセットから高品質なデータを収集し、500,000の高品質なコードライクデータを生成します。
2.2 アニーリングデータ
アニーリング段階では、プレトレーニングデータから得られた情報を基に高品質なアルゴリズムコーパスと合成データを使用します。
3. プレトレーニング
3.1 モデルアーキテクチャ
Open-Coderは、1.5Bパラメータモデルと8Bパラメータモデルの二つのサイズを持ち、SwiGLU活性化関数を使用しています。
3.2 トレーニング詳細
トレーニングは、Megatron-LMフレームワークを使用して256台のGPUクラスターで行われ、トークン数は2兆を超えています。学習率スケジュールにはウォームアップとエクスポネンシャル減衰が含まれています。
4. ポストトレーニング
4.1 データ構成
オープンソースの指示コーパスを収集し、多様性のあるデータセットを生成します。特に、ユーザーのクエリをサンプリングし、実際の問題に焦点を当てたデータを構築します。
4.2 二段階指示調整
理論的なコンピュータサイエンスに関するQAペアと実践的なコーディングタスクのデータセットを使って、二段階の指示調整プロセスを実施します。
5. 実験結果
5.1 ベースモデルの評価
HumanEvalやMBPPなどのベンチマークを使用して、OpenCoderのコード補完能力を評価しました。
5.2 指示モデルの評価
LiveCodeBenchやMultiPL-Eを用いて、OpenCoderの複雑なアルゴリズムタスクに対する処理能力を測定しました。
6. 分析
6.1 重複排除レベルの分析
重複排除がモデルのパフォーマンスに与える影響を調査し、ファイルレベルでの重複排除が効果的であることを示しました。
6.2 アニーリング段階における高品質データの重要性
高品質なトレーニングデータの効果を検証し、その重要性を示す実験結果を提示しました。
7. 関連研究
コードLLMやオープンソースモデルの進展に関する文献をレビューし、OpenCoderの貢献を明らかにします。
8. 結論と今後の課題
Open-Coderは、高品質かつ透明性のあるコードLLMを提供し、研究の透明性と再現性を促進します。今後は、ユーザーフィードバックを反映したモデルの更新を行う予定です。