目次
RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
この論文は、コード合成における実行フィードバックを活用するための強化学習手法「RLEF」を提案し、複数回の試行を通じてコード生成モデルのパフォーマンスを大幅に向上させることを目指しています。
論文:https://arxiv.org/abs/2410.02089
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文では、複数のステップでユーザー指定のタスクを自動的に解決するために、大規模言語モデル(LLM)が実行フィードバックを活用するための強化学習手法(RLEF)を提案しています。特に、コード生成の分野において、従来のサンプリング手法に比べて、より効果的にコードを改善する能力を持つモデルを開発しました。実験では、競技プログラミングタスクにおいて新たな最先端の成果を達成し、必要なサンプル数を大幅に削減しました。この手法は、LLMが推論時の具体的なフィードバックを基にした生成を行えることを示しており、コード生成の反復的な過程においても高い性能を発揮します。最終的に、RLEFはLLMの自律的な運用能力を大幅に向上させることができると結論付けています。
この論文の特徴は、強化学習を用いた実行フィードバックの活用により、従来の独立したサンプリング手法よりも、コード生成の精度を大幅に向上させることに成功した点です。
以下に、論文の各章に基づいた内容を整理し、解説記事をまとめました。
1. はじめに
1.1 背景
近年、大規模言語モデル(LLMs)は、その能力によって特に注目を集めており、複雑なタスクを人間の介入なしで解決することが期待されています。これらのモデルは、ユーザーの指示を正確に理解し、生成した出力を改善する能力が求められています。
1.2 目的
本研究の目的は、コード合成の分野において、実行フィードバックを利用した強化学習手法を提案し、LLMsが生成したコードを繰り返し改善する能力を向上させることです。
2. 方法
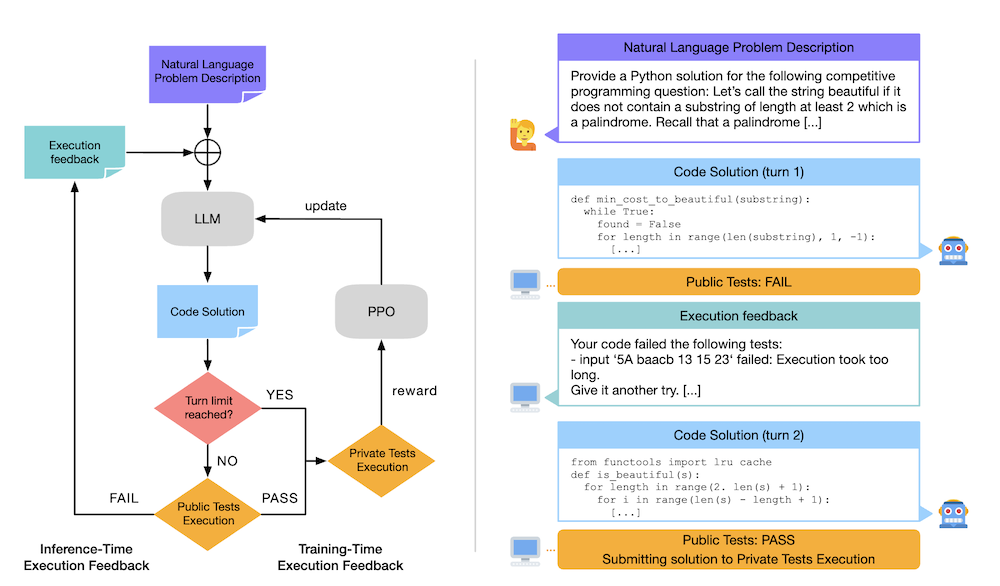
2.1 繰り返しコード合成
コード合成タスクは、多段階の会話形式で構造化されます。初めに、自然言語で記述された問題に基づいてLLMがコードを生成し、その後、生成したコードをテストケースで評価します。このプロセスでは、実行フィードバックが次の試行におけるコンテキストとして活用されます。
2.2 実行フィードバックを用いた強化学習
このアプローチは、マルコフ決定過程(MDP)としてモデル化され、LLMはポリシーとして機能します。エピソードは、全てのテストが成功するか、指定されたステップ数に達するまで続き、成功した場合には報酬が与えられます。報酬最大化のために、近接方策最適化(PPO)が使用されます。
3. 実験結果
3.1 セットアップ
実験にはCodeContestsベンチマークが使用され、自然言語問題とテストケースによって評価されます。Llama 3.1モデルを用いて、反復的なコード生成が行われます。
3.2 主な結果
RLEF(実行フィードバックからの強化学習)を受けたモデルは、従来の手法に比べて大幅に性能を向上させ、小さなサンプル予算での解決率も改善されました。
3.3 推論時の挙動
RLEFトレーニングを受けたモデルは、実行フィードバックを基にエラーを修正する能力を向上させ、初期の応答のエラーを減少させました。逆に、誤ったフィードバックを使用した場合には、修正能力が低下することが確認されました。
4. 関連研究
LLMsを用いたコード生成に関する研究は多岐にわたりますが、実行フィードバックを利用した手法は比較的新しいアプローチです。本研究は、これらの手法に対して、自己修正能力の向上と効率性を兼ね備えた新たな方法を提供します。
5. 結論
本研究では、実行フィードバックを基にした強化学習手法(RLEF)を提案し、LLMsの自己修正機能を強化しました。これにより、CodeContestsベンチマークにおける解決率を大幅に向上させることに成功しました。今後の研究課題として、さらに大規模なタスクへの適用や、自己指導型の手法の開発が挙げられます。
附録
- A. 実験の詳細: 使用したモデル、データセット、ハイパーパラメータ設定などについて詳述。
- B. 追加の実験結果: 事前学習モデルのパフォーマンスや、私的テストからのフィードバックによる性能向上についての結果。
- C. プロンプト: 実験で使用したプロンプトのテンプレートとその設計について。