目次
xGen-MM-Vid (BLIP-3-Video): You Only Need 32 Tokens to Represent a Video Even in VLMs
この論文は、少ない視覚トークン(32トークン)で動画の情報を効率的に表現できるマルチモーダル言語モデル「BLIP-3-Video」を提案し、その性能を実験的に検証しています。
論文:https://arxiv.org/abs/2410.16267
リポジトリ:https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文では、BLIP-3-Videoと呼ばれるマルチモーダル言語モデルを提案しています。このモデルは、複数のフレームにわたる時間情報を効率的にキャプチャすることを目的としており、従来の視覚トークナイザーに加えて「時間エンコーダー」を利用しています。BLIP-3-Videoは、競合するモデルと比較して、はるかに少ない視覚トークン(例:32対4608トークン)で高い精度を達成しています。また、異なるタイプの時間エンコーダーを探求し、オープンエンドの質問応答やキャプション生成タスクにおいて、パラメータ数が少なくても優れた性能を示すことを実験的に確認しました。最終的に、この研究は、効率的な視覚言語モデルの設計において新たなアプローチを提供しています。
BLIP-3-Videoは、従来のモデルよりも圧倒的に少ない視覚トークン(32トークン)で高精度なビデオ質問応答を実現し、効率的な時間エンコーディングの重要性を示した点が特筆されます。
1. はじめに
1.1 背景
本論文は、xGen-MM-Vid(BLIP-3-Video)という新たなマルチモーダル言語モデルを提案しています。このモデルは、動画からの時間的情報を効率的にキャプチャすることを目的としており、従来の視覚トークナイザーに加えて、学習可能な「時間エンコーダー」を搭載しています。BLIP-3-Videoは、他の競合モデルと比較して必要な視覚トークン数を大幅に削減し(例:32トークン対4608トークン)、動画に関する質問応答タスクにおいて優れた精度を示します。
2. BLIP-3-Video
2.1 モデルアーキテクチャ
BLIP-3-Videoのアーキテクチャは、以下の4つの主要コンポーネントから構成されています:
1. 視覚エンコーダ(ViT):各フレームの入力を処理。
2. フレームレベルのトークナイザー:トークン数を削減。
3. 時間エンコーダ:動画全体のトークン表現を構築。
4. 自己回帰型LLM:動画トークンとテキストプロンプトトークンに基づいて出力テキストキャプションを生成。
具体的には、事前学習済みのSigLIPをビジョンエンコーダとして使用し、Perceiver-Resamplerを適用することで、各フレームから128の視覚トークンを生成します。これらのトークンは、時間エンコーダにより動画レベルのトークン表現に変換されます。
2.2 時間エンコーダ
時間エンコーダは、N・Tトークンを入力として受け取り、Mトークンを出力する役割を果たします。BLIP-3-Videoでは、以下の異なるタイプの時間エンコーダが探求されています:
– 時間プーリング:シンプルにフレームごとのトークンを合算。
– 空間-時間注意プーリング:TokenLearnerを使用し、情報量の多いトークンを選択。
– シーケンシャルモデル:Token Turing Machines(TTM)を使用し、任意のフレーム数を処理。
2.3 トレーニング手法
BLIP-3-Videoは、三段階のカリキュラム学習を採用しています:
1. 画像キャプションの事前学習。
2. 動画キャプションの事前学習。
3. 動画指示調整。
このプロセスでは、900k以上の動画キャプションデータを用いてモデルを訓練し、最終的には複数の動画質問応答データセットで調整を行います。
3. 実験と結果
3.1 モデル実装の詳細
BLIP-3-Videoは384×384の解像度で動画を処理し、SigLIPエンコーダを使用して729トークンを生成します。その後、Perceiver-Resamplerを介して、時間エンコーダに渡すトークンを128に圧縮します。
3.2 公共ベンチマーク
BLIP-3-Videoは、MSVD-QAやNExT-QAなどの公共データセットにおいて質問応答精度を測定し、他の大規模モデルと同等またはそれ以上の性能を示しました。
3.3 アブレーションスタディ
異なる時間エンコーダの性能を比較するアブレーションスタディを実施し、特に空間-時間注意プーリングやシーケンシャルモデルの効果を示しました。
4. 関連研究
4.1 画像-テキストLLMs
最近の画像とテキストを結びつけるマルチモーダルモデルの進展について概説し、事前学習された画像エンコーダとテキストモデルの統合方法を論じます。
4.2 動画LLMs
動画の入力を処理するための動画LLMのアーキテクチャの拡張について説明し、BLIP-3-Videoの優位性を強調します。
4.3 トークンプルーニング
トークンプルーニング技術の重要性を述べ、BLIP-3-Videoがトークン効率を最適化し、計算コストを削減する方法を示します。
5. 結論
BLIP-3-Videoは、4Bのパラメータを持ちながら、動画を表現するために16または32のトークンを使用し、競争力のある性能を示す効率的でコンパクトな視覚言語モデルです。この研究は、動画理解の新しい可能性を開くものです。
付録
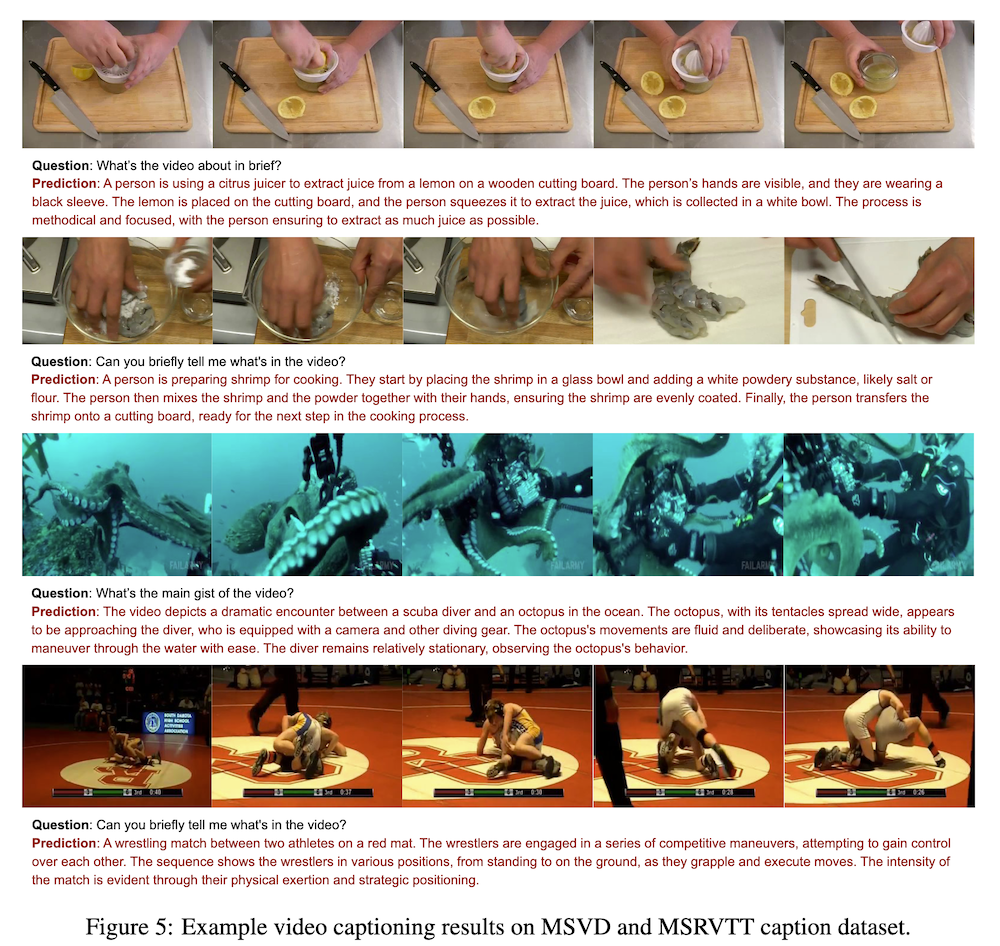
付録では、BLIP-3-Videoの動画キャプション生成結果を他モデルと比較し、その質の高さを示します。BLIP-3-Videoは、より正確で詳細なキャプションを生成し、全体的な理解度が高いことが示されています。