目次
MLLM-Based UI2Code Automation Guided by UI Layout Information
この論文は、ユーザーインターフェースの画像からコードを自動生成するための新しいフレームワーク「LayoutCoder」を提案し、その性能を評価する研究です。
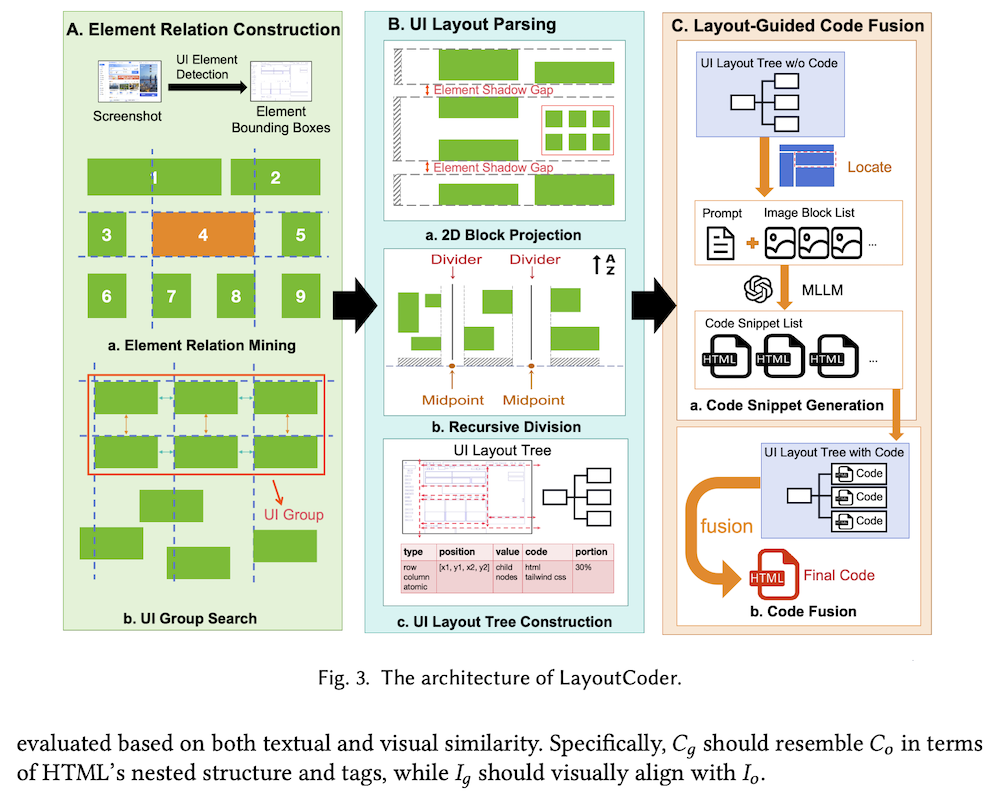
LayoutCoderは、複雑なUIレイアウトを理解し、レイアウトを保持したまま正確なコードを生成するために、要素の関係構築、レイアウト解析、コード融合の3つのモジュールを統合した新しいアプローチを提供しています。
論文:https://arxiv.org/abs/2506.10376
リポジトリ:https://github.com/ay7u1009/LayoutCoder/

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
ユーザーインターフェースをコードに変換すること(UI2Code)は、ウェブサイト開発において重要なステップであり、時間がかかり労力を要します。UI2Codeの自動化は、このタスクを効率化し、開発効率を向上させるために不可欠です。既存の深層学習ベースの手法も存在しますが、これらは大量のラベル付きトレーニングデータに依存しており、実世界の未見のウェブページデザインに対して一般化するのが難しいという問題があります。マルチモーダル大規模言語モデル(MLLM)の登場は、この問題を軽減する可能性を秘めていますが、MLLMはUIにおける複雑なレイアウトを理解し、レイアウトを保持した正確なコードを生成することが難しいのが現状です。
これらの問題に対処するために、私たちはLayoutCoderという新しいMLLMベースのフレームワークを提案します。このフレームワークは、実世界のウェブページ画像からUIコードを生成するもので、3つの主要モジュールを含みます:(1)要素関係構築、これは、UIレイアウトを把握することを目指し、構造が類似したコンポーネントを特定しグループ化します;(2)UIレイアウト解析、これは、次のコード生成プロセスを導くためのUIレイアウトツリーを生成することを目指します;(3)レイアウトガイドコード融合、これは、レイアウトを保持した正確なコードを生成することを目指します。
評価のために、Snap2Codeという新しいベンチマークデータセットを構築しました。これは350の実世界のウェブサイトを含み、データ漏洩の問題を軽減するために、見えた部分と見えない部分に分かれています。広範な評価により、LayoutCoderが最先端のアプローチに対して優れた性能を示すことが確認されました。最も性能の良いベースラインと比較して、LayoutCoderは全データセットにおいてBLEUスコアで平均10.14%、CLIPスコアで平均3.95%向上しました。
1. はじめに
本論文は、WebページのUIから自動的にコードを生成するUI2Codeタスクにおける課題に取り組んでいる。既存の深層学習ベースの手法は大量のラベル付きデータに依存し、実世界の未見Webページデザインへの汎化に困難を抱えている。MLLMsの出現により新たな可能性が示されたが、複雑なレイアウトの理解とレイアウト保持したコード生成に限界がある。本論文では、これらの課題を解決するためにLayoutCoderという新しいMLLMベースのフレームワークを提案している。
2. 関連研究
2.1 UI2Code自動化
UI2Codeタスクは入力タイプに基づいて3つのカテゴリに分類される:Screenshot2Code、Sketch2Code、Prototype2Code。Screenshot2Codeが最も困難なタスクとされている。実装観点から、研究は3つの段階に分けられる:初期段階では従来の画像処理技術とヒューリスティックルール(REMAUIなど)、中期段階ではCVとNLPの統合手法(pix2codeなど)、後期段階ではMLLMs(DCGen、WebSight VLM-8Bなど)が用いられている。
2.2 UIレイアウト生成
ソフトウェア工学分野では、UIレイアウト関連の研究はUI要素グループ化として現れている。これはUI要素検出に基づいて、空間的に近く機能的に関連する要素をグループ化するプロセスである。手法は3つのタイプに分類される:ヒューリスティックルール、クラスタリング、深層学習技術。コンピュータビジョン分野では、UIレイアウト生成として現れ、GANs、VAEs、Transformers、拡散モデルベースの手法が研究されている。
3. 手法
3.1 問題定式化
UI2Codeタスクを以下のように定義する:元のHTML+CSSコードをCo、WebページのスクリーンショットをIo、MLLMをMとし、画像Ioを入力として生成されたHTML+CSSコードCg = M(Io)を出力する。生成されたコードCgの品質は、テキストと視覚的類似性の両方に基づいて評価される。具体的には、CgはHTMLの入れ子構造とタグの観点でCoに類似し、IgはIoと視覚的に一致する必要がある。
3.2 概要
提案するLayoutCoderフレームワークは3つの主要モジュールで構成される:Element Relation Construction(要素関係構築)、UI Layout Parsing(UIレイアウト解析)、Layout-Guided Code Fusion(レイアウト誘導コード融合)。要素関係構築では類似構造を持つ要素グループを特定し、UIレイアウト解析では再帰的分割によりレイアウトツリーを生成し、レイアウト誘導コード融合では原子画像ブロックに対してコードスニペットを生成してツリー構造に基づいて融合する。
3.3 モジュールA:要素関係構築
このモジュールの目標は、Webページ全体で類似構造を示すUI要素をグループ化することである。現代のWebデザインでは類似構造を持つ反復領域が頻繁に組み込まれているため、これらを適切にグループ化しないと、過度な分割、冗長な画像ブロックの生成、一貫性のないコード生成、API呼び出し数の増加という4つの問題が生じる。Element Relation MiningとUI Group Searchという2つの手法を提案している。
3.4 モジュールB:UIレイアウト解析
このモジュールはUI画像のレイアウトを正確にセグメント化する課題に対処する。既存のSAMなどの画像セグメント化技術の予備研究により、小さなUIコンポーネントの保持困難、UI画像における物体感度、同一タイプの反復UIコンポーネントのクラスタリング失敗という3つの課題を特定した。これらの制限を軽減するため、2D Block Projection、Recursive Division、UI Layout Tree Constructionという3つの手法を提案している。
3.5 モジュールC:レイアウト誘導コード融合
このモジュールはコード生成と融合に焦点を当てている。DCGenがMLLMsをコード融合に使用するアプローチには、テキストによるレイアウト表現能力の制約とMLLMsの複雑レイアウトに対するコード生成の限界という2つの制限がある。全体的なコード生成タスクを2つのサブタスクに分割:UIレイアウトツリーのリーフノード内の原子領域に対するコード生成と、リーフノード内のコードスニペット間のレイアウト関係の処理。Code Snippet GenerationとCode Fusionという2つの手法を使用している。
4. 実験設定
4.1 研究質問
以下の4つの研究質問(RQ)に焦点を当てて評価を行った:RQ1では既存のUI2Code手法との比較効果、RQ2ではLayoutCoderの主要コンポーネントの性能への影響、RQ3では実世界Webサイトの複雑性がLayoutCoderの性能に与える影響、RQ4ではユーザー研究と人間評価の結果について検討している。5つの代表的モデル(pix2code、WebSight VLM-8B、DeepSeek VL-7B、GPT-4o、Claude 3.5 Sonnet)と3つの異なるレベルのプロンプト(Direct、CoT、Self-Refine)を比較対象としている。
4.2 データセット
2つの実世界UI-to-Codeデータセット、Design2CodeとSnap2Codeで評価を行った。Design2CodeはC4検証セットからの484の実世界Webページで構成され、主にMLLMsの視覚デザインからコードへの変換をテストするために使用される。Snap2Codeはより複雑なレイアウトとコンポーネントを持つWebページでの性能評価のために新たに作成したデータセットで、SeenとUnseenの2つの部分に分けられ、データ漏洩問題を軽減している。
4.3 ベースライン
LayoutCoderの性能評価のため、5つの代表的モデルと3つの異なるレベルのプロンプトを選択し、合計9つのベースラインとした。pix2codeはCNNとLSTMモデルを統合して画像からコードを生成する代表的なオープンソースモデル、WebSight VLM-8BはHuggingfaceの合成UI-to-Codeデータセットで微調整されたオープンソースVLM、DeepSeek VL-7Bは広範囲な多様な実世界アプリケーションを処理可能なオープンソース視覚言語モデル、GPT-4oとClaude 3.5 Sonnetは優れたコード生成と視覚理解能力を持つクローズドソースMLLMsである。
4.4 評価指標
先行研究に従い、生成されたWebページコードとレンダリングされたWebページ間の類似性を評価するため、テキストと視覚的側面に焦点を当てた2つの広く使用される指標、BLEUスコアとCLIPスコアを採用した。BLEUスコアは生成されたコード(Cg)と元のコード(Co)間の類似性を評価し、CLIPスコアは生成されたコードからレンダリングされたWebページスクリーンショット(Ig)と元のコードからのスクリーンショット(Io)間の類似性を評価する。
4.5 実装詳細
実行環境はPython 3.8.18、conda 24.5.0を使用し、Linux server(64-bit Ubuntu 20.04)上で実験を実施した。サーバーは2つの48コアIntel Xeon Platinum 8260C CPU @ 2.40GHz(96論理プロセッサ)、4つのNVIDIA A100-40GB GPU、251GB RAMを搭載している。
5. 実験結果
5.1 RQ1:ベースラインとの比較
LayoutCoderは他のベースラインと比較して、テキスト類似性と視覚的忠実性の両方で優れた性能を示した。3つのデータセットに関する2つの指標(6つの組み合わせケース)を考慮すると、LayoutCoderは6ケース中5ケースで最高性能を達成した。Snap2Code(Seen)データセットでBLEUスコアが24.12%改善、Design2Codeデータセットで2.28%改善を示した。視覚的一貫性においても、Snap2CodeデータセットのSeenとUnseen部分でClaude(SR)を8.38%から4.63%上回る性能を示した。
5.2 RQ2:アブレーション研究
LayoutCoderの異なるコンポーネントの影響を探るため、UI Group Search、Recursive Division、Code Snippet Generationの3つの主要コンポーネントについてアブレーション研究を実施した。UI groupingの除去では、構造的に類似した領域がUIグループにマージされず、レイアウトセグメント化と視覚レンダリングの均一性に支障をきたした。Gap sortingの除去では、ゲシュタルト近接原理に従った遠近セグメント化順序が乱れ、レイアウトセグメント化と正確なコード生成に支障をきたした。
5.3 RQ3:Webサイト複雑性の影響
Webページの複雑性がLayoutCoderの性能に与える影響を評価するため、主要ベースラインのClaude(SR)と比較実験を実施した。DOM深度、タグ数、長さ、アスペクト比という4つの代表的特徴を選択し、Webページの複雑性を測定した。等頻度ビニングを実装してx軸上のデータポイントの均一分布を確保した。LayoutCoderは様々なWebページ複雑性次元でClaude(SR)を一貫して上回り、高度に複雑なWebページでも堅牢な汎化性能を示した。
5.4 RQ4:人間評価
Claude 3.5 Sonnet(Self-Refine)とLayoutCoderによって生成されたWebページの定量評価を人間評価により実施した。ソフトウェア開発またはUIデザインの経験を持つ4人の参加者を招いて評価を行った。Layout Accuracy、Visual Fidelity、Content Alignment、Code Usabilityという4つの指標を用いて1-5のリッカート尺度で品質を評価した。LayoutCoderはすべてのデータセットと指標でClaude(SR)を上回る性能を示し、特にSnap2Code(Seen)データセットでは大幅な改善を達成した。
6. 考察
6.1 なぜ我々のモデルが機能するのか
LayoutCoderのUI2CodeタスクにおけるWebページでの有効性を実証するため、いくつかの生成ケースを提供している。観察1では、LayoutCoderがWebページ画像からレイアウト情報をより正確に捉えることを示している。観察2では、LayoutCoderのUIグループ化が反復コンポーネントの視覚的一貫性を向上させることを示している。観察3では、LayoutCoderのプロンプトが内側divと外側div間の構造的互換性を改善することを示している。
6.2 LayoutCoderと他の既存手法との主要な違い
LayoutCoder、DCGen、Screen Parsingの3つの手法をレイアウト抽出、部分コード生成、コード融合の3つの主要コンポーネントで分析した。主要な違いとして、レイアウト抽出ではLayoutCoderが投影ベースの手法を使用して深いUI構造を効果的に処理すること、コード融合ではLayoutCoderがdiv要素間の分離関係を使用してMLLMの制限を回避し、より効果的なコード融合を可能にすることが挙げられる。
6.3 LayoutCoderとDCGenの比較
Design2Code、Snap2Code(Seen)、Snap2Code(Unseen)データセットで実験を実施し、生成プロセス中の時間とトークン消費を記録した。DCGenではMLLMベースのコード融合への依存により、MLLMのコンテキストウィンドウ長による制限を受けていた。LayoutCoderはDCGenと比較して時間効率、トークン消費、経済コスト、コード生成成功率、両データセットでの全体的性能で優れた結果を示した。
6.4 妥当性への脅威
LayoutCoderの有効性に対する潜在的脅威として3つの状況を特定した。ベースラインの選択では、計算リソースの制限によりLLaVA1.5などの他のMLLMsとの実験を実施していない。Webページでの汎化性では、実験予算を制御するため各データセットのサイズを250サンプルに制限した。指標バイアスでは、BLEUとCLIPスコアを使用しているが、これらの指標はUI2Codeタスクの微妙な違いを完全に捉えられない可能性がある。
7. 結論
本論文では、実世界のWebページ画像からUIコードを生成する新しいMLLMベースのフレームワークLayoutCoderを紹介した。Element Relation Construction、UI Layout Parsing、Layout-Guided Code Fusionという3つの主要モジュールを含み、複雑なレイアウトを理解し、レイアウトが保持された正確なコードを生成する能力を改善できる。実験結果は、実世界のWebページでの視覚的およびコード類似性の両方において、最高のベースラインであるClaude 3.5 Sonnetに対するLayoutCoderの優位性と、高度に複雑なWebページでの堅牢な汎化性能を実証している。