目次
TableEval: A Real-World Benchmark for Complex, Multilingual, and Multi-Structured Table Question Answering
この論文は、複雑な多言語および多構造のテーブル質問応答(TableQA)を評価するための新しいベンチマーク「TableEval」を提案し、従来のベンチマークの限界を克服することを目的としています。
TableEvalは、さまざまなテーブル構造と多言語データを含む新しいベンチマークで、実世界の複雑なTableQAタスクにおける大規模言語モデルの性能を評価するために設計されており、特に意味的正確性を評価するためのSEATフレームワークを導入しています。
論文:https://arxiv.org/abs/2506.03949
リポジトリ:https://github.com/wenge-research/TableEval

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
大規模言語モデル(LLMs)は自然言語処理において素晴らしい進展を示していますが、テーブル質問応答(TableQA)においては依然として重要な課題に直面しています。多様なテーブル構造や多言語データ、ドメイン特有の推論など、実世界の複雑さが重要であるためです。既存のTableQAベンチマークは、単純なフラットテーブルに焦点を当てていることが多く、データ漏洩の問題に悩まされています。さらに、ほとんどのベンチマークは単言語であり、実際のアプリケーションにおける異言語間や異ドメインの変動を捉えることができません。
これらの制限に対処するために、私たちはTableEvalを導入します。これは、現実的なTableQAタスクにおけるLLMsを評価するために設計された新しいベンチマークです。具体的には、TableEvalは、政府、金融、学術、産業報告などの4つのドメインから収集されたさまざまな構造(簡潔、階層、ネストされたテーブルなど)のテーブルを含んでいます。また、TableEvalは簡体字中国語、繁体字中国語、英語のテーブルを含む異言語シナリオを特徴としています。データ漏洩のリスクを最小限に抑えるため、すべてのデータは最近の実世界の文書から収集されています。
既存のTableQAメトリックが意味的な正確性を捉えることに失敗していることを考慮し、私たちはSEATを提案します。これは、モデルの応答と参照回答の整合性をサブ質問レベルで評価する新しい評価フレームワークです。実験結果は、SEATが人間の判断と高い一致を達成することを示しています。TableEvalに関する広範な実験は、最先端のLLMsがこれらの複雑な実世界のTableQAタスクを処理する能力において重要なギャップを明らかにし、今後の改善のための洞察を提供します。
この論文は、大規模言語モデル(LLM)の表形式データ質問応答能力を評価するための実世界ベンチマーク「TableEval」を提案した研究です。以下、各章節について詳細に説明します。
1. 導入
TableEvalは複雑で多言語・多構造表質問応答のための実世界ベンチマークとして設計されています。従来のTableQAベンチマークは単純な平坦テーブルに焦点を当て、データリークやモノリンガル制約の問題を抱えています。著者らは、現実世界の複雑性(多様な表構造、多言語データ、ドメイン固有推論)を捉えるため、政府・金融・学術・産業レポートから収集した階層的・入れ子構造を含む表データセットを構築し、簡体字中国語・繁体字中国語・英語による多言語シナリオを提供しています。
2. 関連研究
2.1 TableQA手法
TableQA研究は初期のセマンティック解析手法からText-to-SQLアプローチを経て、現在は検索・推論パラダイムへと発展しています。大規模表事前学習により性能が向上し、LLMのfew-shotプロンプティングによってより柔軟で汎用的な表データ推論が可能になりました。
2.2 TableQAベンチマーク
既存ベンチマーク(WQA、SQA、TabFact等)は主にWikipediaのHTMLテーブルを使用し、単純な表構造に焦点を当てています。ToTTo、OTTQA、FeTaQAなどはより複雑な推論を要求しますが、大部分が単一言語であり、階層的・入れ子構造を無視している限界があります。TableEvalはこれらの制約を克服する包括的ベンチマークを提供します。
3. TableEvalの構築
3.1 データセット構築
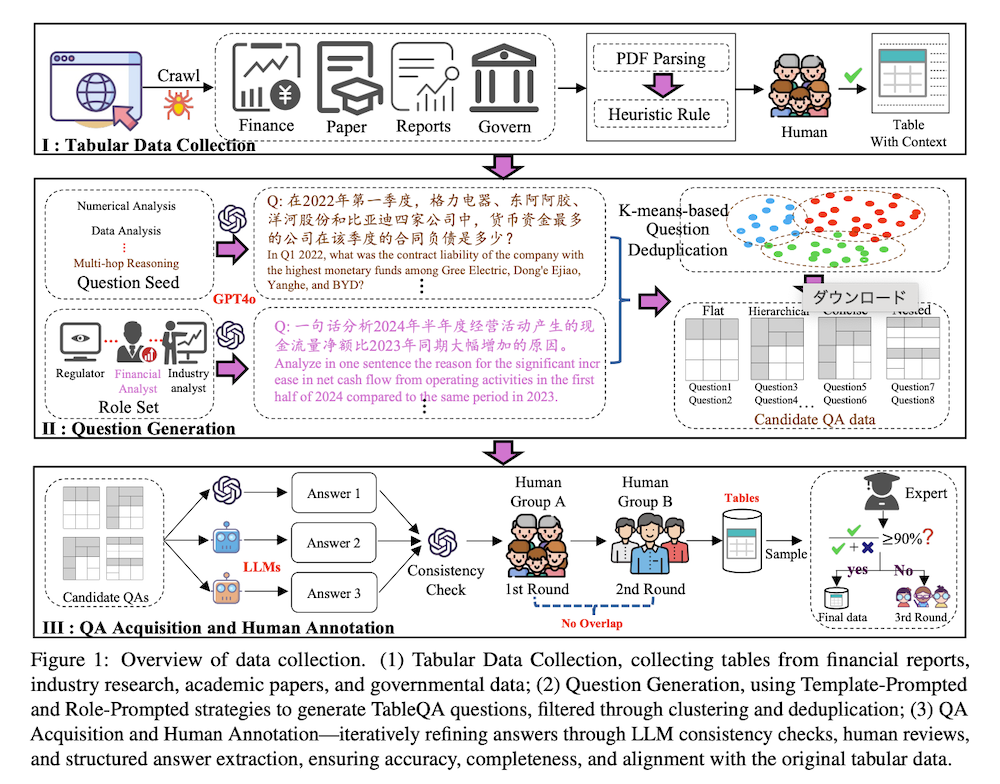
表データ収集: データリーク防止のため2024年発行文書のみを使用し、深圳証券取引所・東方証券・arXiv・CNKI・国家統計局から29,241テーブルを収集しました。PDF・HTML解析後、ヒューリスティックルールで表周辺のコンテキスト情報(キャプション・説明ノート)を抽出し、金融・統計専門の大学院生3名が構造精度を検証してMarkdown形式に変換しました。最終的に617テーブルを構造・サイズ・ソース・内容を考慮してサンプリングしました。
質問生成: Template-Prompted戦略とRole-Prompted戦略の2手法を採用しました。前者はGPT-4oに各TableQAタスク用プロンプトテンプレートとシード例を提供し、後者は投資家・市場アナリスト・ドメインエキスパート等の役割シナリオをシミュレートして多様性を確保しました。K-meansクラスタリングによる重複除去後、34,161の独立質問から2,325の候補を選出しました。
QA取得と人間アノテーション: 金融・統計専門の大学院生6名による3段階アノテーションを実施しました。第1段階では曖昧・不適切質問の除去と精度検証、第2段階では構造化回答抽出とJSON形式化を行い、専門家レビューを含む包括的検証により、サンプル当たり約2.5ドルのアノテーション費用で高品質データセットを構築しました。
3.2 データセット統計
TableEvalは6主要タスクカテゴリと16サブカテゴリから構成され、2,325のQAペアを含みます。情報検索(27.40%)、数値解析(23.48%)、データ分析(29.55%)、多段推論(5.94%)、多ターン会話(1.33%)、表構造理解(12.30%)の分布となっています。表構造別では平坦(166)、階層(6)、簡潔(69)、入れ子(243)、その他(133)テーブルを含み、実世界シナリオの多様性を反映しています。
4. TableQA評価手法
従来のexact match、F1スコア、n-gramマッチング等の指標はLLM生成自然言語応答の意味的精度評価に限界があります。そこで著者らはSEAT(Structured Evaluation for Answers in TableQA)を提案しました。SEATは2段階プロセスで動作します:(1)モデル応答から各サブ質問の重要回答を抽出し、参照回答と比較して一致・相違要素を特定、(2)評価結果をJSON形式で構造化し、最終スコアを集約します。実験により、SEATは人間判定との相関において既存指標を大幅に上回ることが示されました。
5. 実験結果
SEATの有効性: 人間スコアとの相関分析において、SEATはPearson相関係数0.9373、Spearman相関係数0.9346、Kendall相関係数0.9062を達成し、F1(0.1776)やROUGE-L(0.6132)を大幅に上回りました。
主要結果: 19モデル(7B-671Bパラメータ)の評価で、クローズソースモデル(Claude-3.5-Sonnet 83.32%、o1-preview 83.43%)が最高性能を示しました。オープンソースモデルではDeepSeek-R1(82.46%)が優秀でしたが、QwQ-32B-Preview(78.14%)等も競争力を示しました。モデルサイズ拡大により性能向上が確認され、複雑推論・データ分析タスクでクローズソースモデルの優位性が明らかになりました。
構造別性能: 入れ子・階層構造テーブルで平坦テーブル比10-15%の性能低下が観察され、構造認識理解の困難性が示されました。DeepSeek-R1が階層構造で特に優秀な性能を示しましたが、全モデルで複雑構造への対応課題が残存しています。
言語別性能: クローズソースモデルは多言語対応で高い一貫性を維持しました。中国語コーパスで訓練されたモデル(Qwen系列、DeepSeek-R1)は英語で最高性能を示し、簡体字中国語、繁体字中国語の順となりました。英語中心モデルは英語・繁体字中国語で高性能を示す傾向がありました。
ドメイン別性能: 大型モデルは全4ドメイン(金融、政府、論文、レポート)で小型モデルを上回りました。金融・政府データがより困難で、論文・レポートタスクは相対的に安定した処理が可能でした。構造化データの複雑さが分野により異なることが示されました。
6. 結論
TableEvalは構造・言語・ドメインの多様性を備えた実世界ベンチマークとして、LLMのTableQA能力における重要な課題を明らかにしました。最新データ使用によりリーク問題を最小化し、より正確な汎化能力評価を実現しています。SEAT評価フレームワークは従来指標の限界を克服し、人間判定との高い一貫性を示しました。実験結果から、クローズソースモデルの優位性、複雑表構造理解の困難性、ドメイン・言語固有の性能格差が明らかになり、構造認識アプローチ・多言語表現・ドメイン適応の重要性が示されました。
7. 制限事項
(1)多様な表レイアウト(不規則形式・画像ベース表)の完全カバー不足、(2)質問は簡体字中国語提示で表内容は3言語対応だが、完全多言語TableQAシナリオの深い調査が必要、の2点が主要制限として挙げられています。