目次
DiCoRe: Enhancing Zero-shot Event Detection via Divergent-Convergent LLM Reasoning
この論文は、ゼロショットイベント検出の精度を向上させるために、発散的および収束的な推論フレームワーク「DiCoRe」を提案し、従来の手法と比較して優れた性能を示すものです。
DICOREは、発散的推論と収束的推論を組み合わせることで、ゼロショットイベント検出におけるイベントカバレッジを向上させ、LLMの認知負荷を軽減しつつ精度を保つ新しいアプローチを提供します。
論文:https://arxiv.org/abs/2506.05128
リポジトリ:https://github.com/PlusLabNLP/DiCoRe (投稿時点未公開)

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
ゼロショットイベント検出(ED)は、トレーニングデータなしで自然言語テキスト内のイベントの言及を特定するタスクであり、専門分野における文書理解において重要です。複雑なイベントオントロジーの理解、パッセージからのドメイン特有のトリガーの抽出、およびそれらの適切な構造化は、大規模言語モデル(LLM)のゼロショットEDに対する有用性を制限しています。
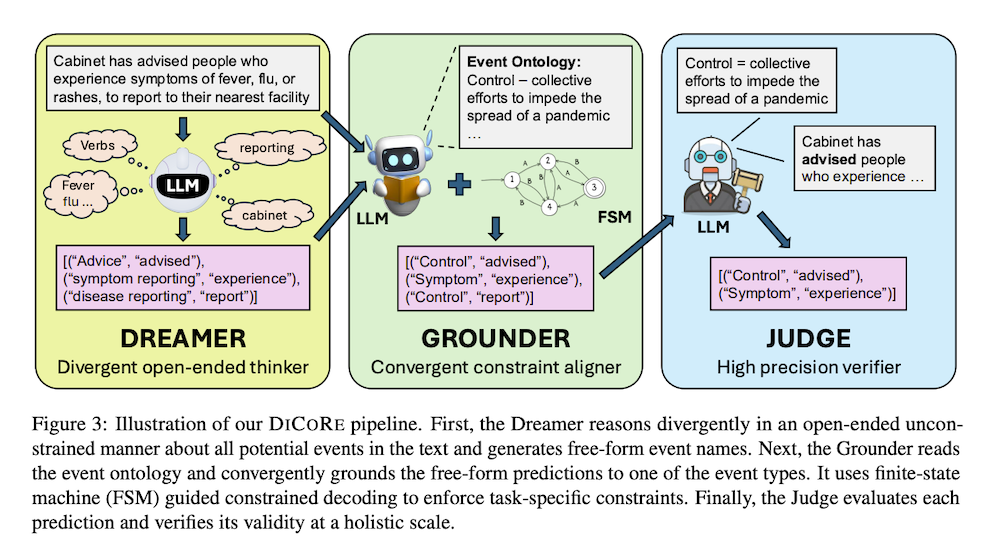
この目的のために、我々はDICOREを提案します。DICOREは、DreamerとGrounderを使用してEDタスクを分離する発散的・収束的推論フレームワークです。Dreamerは、オープンエンドのイベント発見を通じて発散的推論を促進し、イベントのカバレッジを向上させます。一方、Grounderは、有限状態機械に基づく制約付きデコーディングを使用して、自由形式の予測をタスク特有の指示に整合させる収束的推論を導入します。加えて、LLM-Judgeが最終出力を検証し、高い精度を確保します。
5つのドメインにわたる6つのデータセットと9つのLLMに関する広範な実験を通じて、DICOREが従来のゼロショット、転移学習、および推論のベースラインを一貫して上回り、最高のベースラインに対して4〜7%の平均F1改善を達成することを示します。このことにより、DICOREが強力なゼロショットEDフレームワークであることが確立されます。
1. イントロダクション
ゼロショットイベント検出(ED)は、訓練データなしで自然言語テキストからイベント言及を特定するタスクである。専門ドメインでの文書理解に重要だが、大規模言語モデル(LLM)での性能は限定的である。複雑なイベントオントロジーの理解、ドメイン固有トリガーの抽出、適切な構造化が必要で、これらの制約がLLMの認知負荷を増加させ、効果的な推論を阻害する。本研究では、DICOREという新しい発散-収束推論フレームワークを提案し、DreamerとGrounderでEDタスクを分離する。Dreamerは開放的なイベント発見を通じて発散推論を促進し、Grounderは有限状態機械誘導制約デコーディングを用いて収束推論でタスク固有指示との整合を図る。
2. 背景と関連研究
2.1 イベント検出の定義
イベント検出は、事前定義されたオントロジーに基づいて入力テキストからイベント言及を特定するタスクである。イベントは状態変化を示すものとして定義され、各イベントはイベントタイプeでラベル付けされる。イベントトリガーtは、テキスト内でのイベントの存在を示す最も特徴的な単語/フレーズである。トリガー-イベントタイプペア(t, e)は共にイベント言及と呼ばれる。従来、ACE05やEREが様々なシーケンスタギングや生成モデルの開発に利用されてきたが、専門ドメインでの専門家アノテーションデータの取得は高コストで労働集約的である。
2.2 ゼロショットイベント検出
近年、MAVEN、FewEvent、GENEVA等の多様なデータセットが開発されている。初期研究では質問応答や機械読解理解問題としてEDを扱った。様々な研究が情報抽出タスク間の転移学習や共同学習を探求し、より汎用的なIEモデル構築を目指した。一部の研究では生成的テキスト-テキストアプローチやゼロショット言語間転移も探求された。しかし、これらはソースデータ訓練を必要とし、実用性が限られる。最近の研究ではLLMでのゼロショットプロンプティングを探求したが、性能は劣っていることが結論された。
2.3 制約の軽減によるLLMの推論向上
LLMは優れた言語理解・生成能力を示すが、意味のある人間タスクには指示と制約が必要である。しかし、制約の課せることでLLMの推論能力も低下する。これを受けて、出力確率分布を変更する制約デコーディングや文法整合デコーディング戦略が探求されている。最近、数学推論における制約からLLMを解放するより良いプロンプト設計が探求されており、本研究でも同様の着想を得て、IEタスク、特にイベント検出における推論改善のためのLLM制約分離を探求する。
3. 方法論
著者らは生成的観点fgenを通じてEDを枠組み化し、構造化されたタプルリストを出力生成として考慮する。これらの考慮により、予測されたイベントが提供されたリストからのものであること、予測されたトリガーフレーズが入力テキスト内にあること、出力生成がJSON形式に従うことという制約が導入される。これらの構造的制約がLLMの認知負荷を増加させ、推論をより困難にすると主張する。DICOREは発散的開放発見、収束的整合、制約デコーディングを通じて制約遵守を分離・軽減する軽量なパイプラインである。
3.1 Dreamer(発散的開放思考者)
Dreamerコンポーネントは開放的発散発見を促進し、事前定義されたイベントオントロジーに制約されることなく、LLMが潜在的イベントを自由に特定することで高い再現率を達成することを目的とする。具体的に、Dreamerコンポーネントfdはタスク固有イベント制約を除去し、トリガー制約を緩和し、LLMに入力文Xから直接イベント言及を抽出するようプロンプトする。ここで各e’iは自由形式のLLM生成自然言語イベント名であり、イベントオントロジーEに従う必要はない。イベントオントロジーへの明示的参照を除去することで、指示がより制限的でなく、LLMにとってより意味的に直感的になる。
3.2 Grounder(収束的制約整合器)
Grounderコンポーネントは、Dreamerの開放的予測Ydを閉じたタスク固有イベントオントロジーEと収束的に整合させ、マッピング不可能なイベントをフィルタリングする。技術的に、Grounderコンポーネントfgはプロンプトにオリジナルのタスク固有制約を注入し、グラウンドされたイベント言及Ygを生成する。LLM上の制約追従負荷を軽減し、タスク形式への厳密な遵守を確保するため、有限状態機械(FSM)によって誘導される制約デコーディングメカニズムを組み込んでいる。FSMは主要制約をデコーディングプロセス内にエンコードするよう設計されている。
3.3 Judge(高精度検証器)
パイプラインの最終コンポーネントであるJudgeは、各予測されたイベント言及がオリジナルのタスク指示に従うことを確保する役割を果たす。具体的に、各候補ペア(ei, ti)について、Judgefjはトリガーtiがイベントタイプeiを入力文Xの文脈で表現するという仮説を評価する。”Yes”の予測を持つすべての予測が最終出力に受け入れられ、その他は拒否される。この検証ステップは、全体的なレベルでの予測の意味的妥当性とタスク整合を確保する上で重要な役割を果たす。追加の監督や訓練を必要とせず、無関係または不確実な出力をフィルタリングすることで、Judgeはシステム全体の精度を大幅に向上させる。
4. 実験設定
4.1 データセット
6つのEDデータセットで5つの多様なドメインにわたってモデルをベンチマークした:(1)一般ドメインからMAVEN、FewEvent、(2)ニュースドメインからACE、(3)生物医学ドメインからGENIA、(4)疫学/ソーシャルメディアドメインからSPEED、(5)サイバーセキュリティドメインからCASIE。分布バイアスを避けるため、TextEEに従って完全なデータセットから250データポイントを均等にサンプリングして評価に使用した。
4.2 ベースライン
主要ベースラインとして(1)Multi-event Direct(MD):LLMに単一パスで最終出力を提供するよう直接プロンプト、(2)Multi-event Staged(MS):タスクを2段階に分解し、第1段階でイベントを特定、第2段階で対応するトリガーを抽出する手法を考慮した。その他、Binary-event Direct(BD)、Decompose-Enrich-Extract(DEE)、GuidelineEE(GEE)、ChatIEとも比較した。
4.3 評価指標と実装詳細
Trigger Identification(TI)、Event Identification(EI)、Trigger Classification(TC)の3つの指標でF1スコアを報告した。TextEEをベンチマーキング、データセット、評価設定に使用し、FSM誘導制約デコーディングのためにOutlinesをvLLM推論上で利用した。GPTファミリーLLMのクエリにはCuratorを使用し、デコーディングには温度0.4、top-p 0.9を適用し、堅牢なベンチマーキングのため3回実行の平均結果を報告した。
5. 結果と分析
5.1 主要結果
6つのデータセットでLlama3 LLMを用いた主要ゼロショット結果を示した。平均結果から、DICOREが最高のベースラインであるmulti-event staged(MS)を大幅に上回り、TIで5.5-8%、EIで4-8.5%、TCで4-5%の改善を達成した。ChatIE、MS、DICOREの異なるタスク分解手法間の性能格差は、Dreamer-Grounderの発散-収束分解がより強い帰納バイアスを提供することを示している。他のベースラインはGENIA/SPEEDなどの少イベント・単純データセットで比較的良好な性能を示したが、DICOREはMAVEN/FewEvent/ACEなどの大規模イベントデータセットで強い優位性を示した。
5.2 ファインチューニング転移学習手法との比較
様々な研究が転移学習と汎用情報抽出訓練をゼロショット言語間データセットEDに利用している。DEGREE(生成フレームワーク)とGOLLIE(汎用IEフレームワーク)という2つの転移学習アプローチとDICOREを比較した。DEGREEについてはソースデータがACEとMAVENである2つのバージョンを考慮した。結果により、ファインチューニングを行わないにも関わらず、DICOREが全設定でファインチューニング転移学習ベースラインを一貫して上回ることを実証した。平均して、DICOREはLlama3-8B-Instructで3-10%、Llama3-70B-InstructとGPT4oで10-22%のF1改善を達成した。
5.3 推論ベースラインとの比較
追加トークンを使用した思考の言語化による推論は、幅広いタスクで性能向上に有効である。Chain-of-thought(CoT)やDeepseek-R1-Distilled-Qwen-32B、O1-miniなどの思考ベースモデルでゼロショットEDでの推論の有用性を評価した。ベースラインが追加推論で改善することを実証したが、ベースモデル(Llama3-70B)を用いたDICOREは、平均で15-55倍少ないトークンを使用しながら、これらすべての推論ベースライン(O1-miniを含む)を一貫して上回った。また、DICOREと推論を組み合わせることで最大1-2%のF1改善を示し、手法の相補性も実証した。
5.4 アブレーション研究
パイプラインの各コンポーネントの役割を実証するため、ACEデータセットでLlama3-8BとLlama3-70B LLMについて各コンポーネントを追加していく際のモデル性能をアブレーションした。DreamerはTIで高い再現率を達成し(低精度だが)、発散的制約なし推論の有用性を実証した。Grounderは予測を整合させ、再現率がわずかに低下する一方で精度を向上させた。FSM Decodingはマッピング改善によりLlama3-8B-Instructの再現率を大幅に向上させ、制約違反修正によりLlama3-70B-Instructの精度を向上させた。最終的にJudgeがモデルの精度を大幅に向上させた。ベースラインの分析により、保守的で少数の高精度予測を行うのに対し、DICOREはより多くの予測を行い、再現率を大幅に向上させながら合理的に高い精度を維持することが明らかになった。
6. 結論と今後の課題
本研究では、LLMをタスク固有制約から分離し、間接的にLLMの推論をより良く活用することを目指したDreamer-Grounder-Judgeの新しい発散-収束推論パイプラインであるDICOREを紹介した。5つのドメインから6つのEDデータセット、9つのLLMでの実験を通じて、DICOREがより強い帰納バイアスを提供し、他のゼロショットベースライン、ファインチューニング転移学習手法、推論重視アプローチを上回ることを確認した。今後の研究では、このパラダイムをより広範なタスクに探求し、発散-収束推論をより良く引き出す研究が可能である。