目次
Document Valuation in LLM Summaries: A Cluster Shapley Approach
この論文は、LLM(大規模言語モデル)による要約における文書の価値を公正に評価するための新しいアプローチとして、クラスタシャプレー法を提案しています。
クラスターシャプレーアルゴリズムは、文書の意味的類似性を活用してシャプレー値の計算を効率化し、大規模なデータセットにおける文書評価を高精度で実現する点が特徴です。
論文:https://arxiv.org/abs/2505.23842

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
大規模言語モデル(LLM)は、検索エンジンやAIアシスタントなど、複数のソースからコンテンツを取得して要約するシステムでますます使用されるようになっています。これらのモデルは、首尾一貫した要約を生成することでユーザー体験を向上させますが、元のコンテンツ制作者の貢献を隠してしまうため、クレジットの帰属や報酬に関する懸念が生じています。本研究では、LLM生成の要約に使用される個々の文書の価値を評価するという課題に取り組みます。
私たちは、各文書の限界的な貢献に基づいてクレジットを配分するゲーム理論的手法であるシャプレー値を使用することを提案します。理論的には魅力的ですが、シャプレー値は大規模での計算が高コストであるため、文書間の意味的類似性を活用する効率的な近似アルゴリズムであるクラスターシャプレーを提案します。この方法では、文書をLLMベースの埋め込みを使用してクラスタリングし、クラスターレベルでシャプレー値を計算することで、計算の大幅な削減を実現しつつ帰属の質を維持します。
私たちは、Amazonの製品レビューを用いた要約タスクでこのアプローチを実証します。クラスターシャプレーは計算の複雑さを大幅に減少させる一方で、高い精度を維持し、モンテカルロサンプリングやカーネルSHAPなどのベースライン手法を上回り、より良い効率的フロンティアを提供します。私たちのアプローチは、使用される正確なLLM、要約プロセス、評価手順に依存せず、さまざまな要約設定に広く適用可能です。
1. 導入
大規模言語モデル(LLM)の普及により、検索エンジンやAIアシスタントが複数の情報源から内容を取得し要約する技術が革新された。これらのシステムは一貫した要約を生成してユーザー体験を向上させるが、元のコンテンツ作成者の貢献を不透明にし、クレジット帰属と報酬に関する懸念を生じさせる。本研究では、LLM生成要約で使用される個別文書の価値評価という課題に取り組む。ゲーム理論手法であるShapley値を用いて、各文書の限界貢献に基づいたクレジット配分を提案する。理論的に魅力的だが、Shapley値の大規模計算は高コストである。
2. 関連研究
本研究は、ゲーム理論、LLM、マーケティングの複数の研究領域に関連し貢献する。まず、GPT-4のようなLLMによる要約が、ニュース要約タスクにおいて人間アノテーターと同等以上の事実精度、一貫性、全体的品質を達成することが示されている。テキスト要約は、TextRankのような従来の抽出手法からLLMによるより高度な抽象的アプローチへと進化した。RAGフレームワークは情報検索とLLM生成を組み合わせ、事実精度と情報の最新性において大幅な改善を示している。また、Shapley値はゲーム理論の概念として機械学習で特徴重要度の定量化とデータ評価に大きな注目を集めている。
3. 問題定義
本研究では、異なる生産者によって生成されたD個の元文書にアクセスするプラットフォームの観点から問題を定義する。これらの文書はi.i.d.である必要はなく、重複する情報を含み、内容の量と質が異なる場合がある。ユーザーは分布g(q)から抽出されたクエリqを使用してプラットフォームに情報を問い合わせる。プラットフォームはLLMベースの要約モデルA(q, D)を使用して各クエリqに応答を生成する。実際には、プラットフォームは要約プロセスのためにクエリに最も関連する文書のサブセット(Sq ⊆ D)のみを使用することを選択する場合がある。要約の品質や性能はv(q, A(q, Sq))で表される。
4. 解決策概念:文書評価のためのShapleyフレームワーク
4.1 Shapley値
本研究では、LLM要約における文書評価の問題に対処するための原理的フレームワークを提示する。解決策概念は協力ゲーム理論のShapley値フレームワークに基づく。与えられたクエリqと特定の文書セットに基づくLLMベースの要約について、Shapley値フレームワークを使用して要約によって生成される総価値をこの文書セット全体に配分する。Shapley値は各文書が全体的要約にどの程度貢献するかを定量化し、冗長性や重複情報などの文書間の相互作用を考慮する。Shapley値は効率性、対称性、ヌル文書、線形性の4つの性質を通じて公正な帰属を保証する。
4.2 Shapley値の近似:Cluster Shapleyアプローチ
Shapley値の指数的計算複雑性(2^|Sq| – 1)に対処するため、テキスト埋め込みの意味的類似性を活用するCluster Shapleyアルゴリズムを提案する。
核心的アイデア:類似した内容を持つ文書は最終要約に対して同等の貢献をし、類似したShapley値を受け取るべき
アルゴリズムの流れ:
- ステップ1:LLM生成埋め込みを用いて文書をクラスタ化。距離制約(d(ei, ej) ≤ ε)を課し、同じクラスタ内の文書が厳密に近接することを保証
- ステップ2:各クラスタ内の文書を連結してメタ文書とし、クラスタレベルでShapley値を計算
- ステップ3:クラスタのShapley値を個別文書に均等配分(ϕ̂_i = ϕ̂_Gk/|Gk|)
調整可能なハイパーパラメータεにより、計算効率と近似精度の柔軟なトレードオフが可能。
4.3 Cluster Shapleyアルゴリズムの理論解析
近似誤差の理論保証:
- 埋め込み空間におけるLipschitz連続性仮定の下で、各文書のShapley値近似誤差を束縛
- 定理1:近似誤差は|ϕ̂_i – ϕ_i| ≤ Lεで束縛され、ε→0で正確なShapley値に収束
計算複雑性:
- 全体の最悪ケース時間複雑性:O(n² + 2^m)
- 文書クラスタリング:O(n²)、クラスタレベルShapley計算:O(2^m)
- 文書間の意味的冗長性が高い場合、大幅な計算節約を実現
大規模設定への拡張:
- クラスタ数mが大きい場合、Monte Carlo等の近似アルゴリズムをクラスタレベルで適用
- 定理2:総近似誤差をクラスタリング誤差とクラスタレベル近似誤差の和として分解
- 計算複雑性をO(n² + mε^-2)まで削減可能
5. 応用設定:Amazon レビューデータセット
実証実験のために、Hou et al. (2024)によって収集された公開Amazon製品レビューデータセットを使用する。このデータセットは1996年5月から2023年9月までをカバーし、5451万ユーザーからの5億7154万件以上のレビューを特徴とし、4819万の一意なアイテムを対象としている。33の異なるカテゴリに組織化されており、電子機器、家庭用品、衣料品、書籍が含まれる。消費者にとって大量の情報処理が困難な問題に対処するため、多くのeコマースプラットフォーム(Amazonを含む)がLLMを採用して利用可能なレビュー/ユーザー生成コンテンツから消費者の特定クエリに最も関連する情報を検索・要約し始めている。
6. 実装詳細
6.1 RAGの紹介
AI検索エンジンは、ユーザークエリに対してリアルタイムで文脈的に関連する応答を提供するよう設計されている。これらのシステムの背後にある重要な技術は、事前訓練されたLLMと情報検索を統合して応答精度と関連性を向上させるRAG(Retrieval-Augmented Generation)である。RAGは、最新のドメイン関連文書からの新しい情報を組み込むことで、静的な事前訓練LLMの制限に対処する。信頼できる文書で応答を根拠づけることにより、RAGはAI生成回答の関連性を向上させ、幻覚を減少させ、既成のLLMを悩ませる古い情報の問題を軽減する。
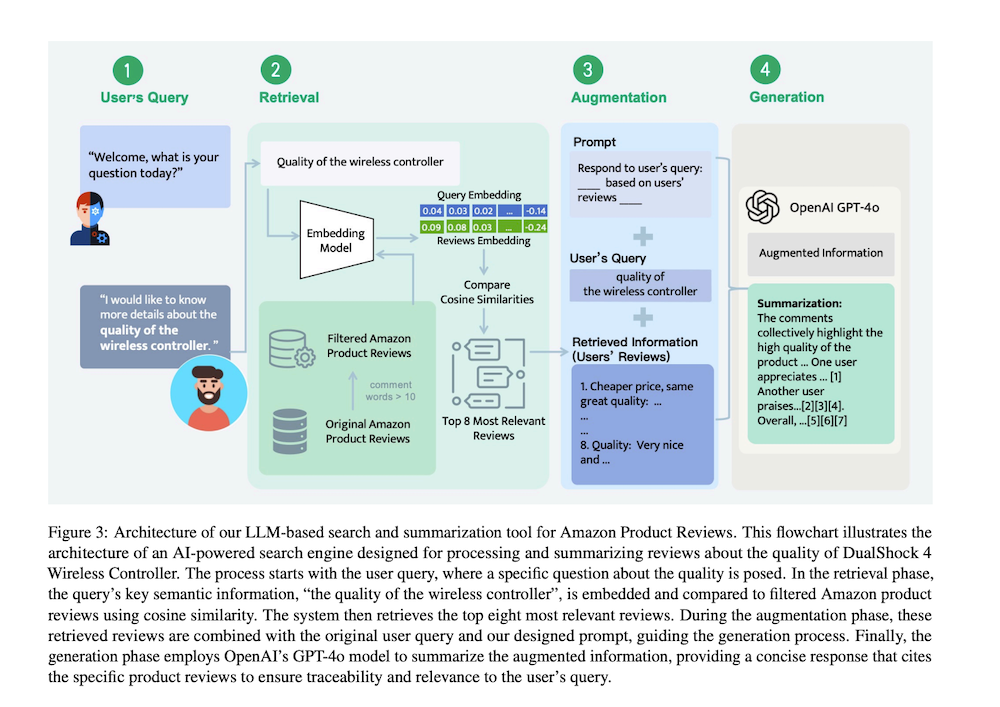
6.2 RAGによるAmazon関連レビューの要約
Amazon レビューから関連文書Sqを見つけ、与えられたクエリqに対する要約ツールA(q, Sq)を構築するRAGベース検索を構築する。4ステップの手順は以下の通り:ステップ0では、製品に関連するすべてのDレビュー/文書のテキスト埋め込みを生成する。ステップ1では、ユーザークエリqを取得する。ステップ2では、まずユーザークエリを処理してその中の主要な意味情報を抽出し、次にOpenAIのtext-embedding-3-largeモデルを使用して処理されたクエリの埋め込みを生成する。各レビューiについて、クエリ埋め込みとレビュー埋め込み間のコサイン類似度を計算し、|Sq| = 8として最も関連性の高いレビューを保持する。
6.3 要約されたAmazonレビューの評価
次に、生成された要約の品質を評価する関数v(·)の実装について説明する。これを運用するため、性能スコアリング関数として機能するGPT-4oのプロンプトを設計する。LLMは各要約の情報性を「情報カバレッジ」に基づいて評価し、要約が製品レビューの主要側面をいかによく捉えているかを反映する。各要約は0から10のスケールで評価され、高いスコアは関連情報のより包括的で正確な反映を示す。LLMは明確性と関連性を優先し、重要な詳細を強調するよう指示される。
6.4 要約と評価における確率性
LLM出力は次トークン予測の確率的性質により本質的に確率的である。GPT-4oの温度が0に設定されていても、要約プロセスA(q, S)と評価プロセスv(q, A(q, S))の両方が、ハードウェアレベルの計算変動性により非決定論的出力を生成する。この確率性を管理するため、異なる温度設定を実験し、要約と評価プロンプトの両方で温度を0.1に設定する。この選択は、意味的一貫性(繰り返し生成間での意味の安定性を測定)と語彙多様性(語彙使用の変動を反映)という2つの指標によって導かれる。
6.5 正確なShapleyの詳細とコスト
実装例:
- 式(5)を使用してShapley値を計算
- 例:「ワイヤレスコントローラーの品質」クエリで、Review #3が最高値(1.83)を獲得
- 理由:他バージョンとの品質比較を直接行い機能性を強調し、「情報カバレッジ」重視のプロンプトと一致
計算コストの課題:
- 8つの関連レビューで2^8 – 1 = 255のサブセット処理が必要
- 各サブセットに要約生成+信頼できるスコアリングのため4回評価
- 実測コスト:単一クエリ処理に平均15分、約1.30ドルのOpenAI API料金
スケーラビリティの限界:
- Perplexity AI(月4億クエリ)に適用した場合:月5.2億ドルの計算コスト
- オープンソースLlama-3使用でも98.4%コスト削減後、月830万ドル
- 年間収益1億ドルと比較して依然として高コスト
- 大規模アプリケーションでは正確なShapley手法は実行不可能で、効率的近似アルゴリズムが必要
6.6 Cluster Shapley実装
提案されたCluster Shapleyアルゴリズムの実装では、まずクラスタリング直径ハイパーパラメータεを指定する。数値比較では、近似誤差と計算時間のトレードオフを示すためにε値のスペクトラムを評価する。クラスタリング直径εを指定した後、Algorithm 2を適用して文書クラスタリングを実行する。適応的クラスタリングアルゴリズムの計算コストは、特にLLMベース要約と評価のコストと比較して無視できる。ステップ2では、クラスタ内のすべての文書を追加し、各クラスタをメタ文書として扱い、クラスタレベルの正確なShapley値を取得する。最後に、クラスタレベルのShapley値を個別文書にクラスタ内で均等に配分し直す。
7. 結果
7.1 ベンチマークアルゴリズム
Shapley値近似の3つの広く使用されているアルゴリズムを簡潔に要約する:Monte Carlo(Mann and Shapley, 1960)は、|Sq|!の可能な組み合わせから順列をランダムサンプリングし、各文書iと1つの順列P_i^πについて限界貢献を計算する。Truncated Monte Carloは、評価されるサンプル数を適応的に削減することでShapley値計算を加速する。Kernel SHAP(Lundberg and Lee, 2017)は、重み付き最小二乗回帰に基づくモデル非依存アプローチでShapley値を近似する。PythonのSHAPパッケージを使用し、LLMベース要約タスク用にカスタム実装する。
7.2 数値比較結果
数値実験には48のテストクエリが含まれ、Amazon レビューデータセットから選択された最も関連性の高い8つのレビューで構成される。安定した評価ベースラインを確立し、要約・評価ステップによって導入される分散を削減するため、プロセスを標準化する。各クエリについて、各サブセット(255の可能なサブセットすべて)に対して単一の要約を生成し、4回の評価の平均を取ることで各要約の評価スコアを固定する。結果は、Cluster Shapleyがすべてのアルゴリズム全体で最高の性能を達成することを示している。その誤差曲線は一貫して他のアルゴリズムより下に位置し、与えられた計算コストでより低い近似誤差を達成するか、同等に同じ精度レベルに到達するためにより少ない計算を要求することを示している。
7.3 頑健性チェックと拡張
アプローチの様々な側面に関する一連の頑健性チェックと拡張を実施する。主解析では要約と評価の両方にGPT-4oを使用したが、評価に異なるLLM(Claude)を使用した解析を実施し、類似の評価結果と同様のShapley値が得られることを確認した。また、MSEとMAPEを含む代替指標を使用した近似誤差の比較も行い、Figure 5と一致する結果を確認した。さらに、主解析では提案した適応的DBSCAN(Algorithm 2)を使用したが、標準(非適応的)DBSCANアルゴリズムを使用した頑健性チェックを実施し、適応的バージョンが一貫して優れた性能を示すことを確認した。
8. 結論
LLMベース要約・検索技術のデジタルプラットフォームへの急速な統合は、情報の消費、共有、収益化の方法を再構築した。これらの進歩はユーザー体験とプラットフォームエンゲージメントを向上させる一方、コンテンツ作成者の帰属、報酬、持続可能性に関する深刻な懸念も提起している。本論文は、この進化するエコシステムにおける重要でタイムリーな課題に取り組む:LLM生成要約に対する個別文書の貢献を公正かつ効率的に評価する方法である。本研究は3つの核心的貢献を行う。第一に、Shapley値に基づく公平な文書評価のための原理的フレームワークを提案し、公正性、汎用性、スケーラビリティなどの重要な望ましい特性を満たす理論的に根拠のあるアプローチを提供する。第二に、意味的類似性を活用してShapley値計算の計算負荷を削減するCluster Shapleyアルゴリズムを導入する。第三に、Amazon製品レビューに基づく実世界ケーススタディを通じて、アルゴリズムの実用的効果を実証し、MAPEを20%未満に保ちながら計算を最大40%削減し、既存のベンチマーク手法を一貫して上回る性能を示した。