目次
LSRP: A Leader–Subordinate Retrieval Framework for Privacy-Preserving Cloud–Device Collaboration
本論文は、プライバシーを保護しつつクラウドとデバイス間の協力を強化するために、リーダー-従属型の情報検索フレームワーク(LSRP)を提案し、個別化されたユーザー体験を向上させる方法を探求しています。
LSRPは、クラウド上の大規模言語モデルとデバイス上の小規模言語モデルの協調を強化し、ユーザーのプライバシーを保護しつつ、タスク特有のリーダー戦略を動的に選択することで、個別化された応答の関連性を大幅に向上させる革新的なフレームワークです。
論文:https://arxiv.org/abs/2505.05031
リポジトリ:https://github.com/Zhang-Yingyi/LSRP

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
クラウドデバイスのコラボレーションは、公共のユーザークエリを処理するためにクラウド上の大規模言語モデル(LLMs)を活用し、プライベートなユーザーデータを処理するためにデバイス上の小規模言語モデル(SLMs)を使用することで、強力かつプライバシーを保護するソリューションを形成します。しかし、既存のアプローチは、クラウド上のLLMsのスケーラブルな問題解決能力を十分に活用できておらず、デバイス上のSLMsが個別のデータにアクセスして処理する利点を十分に活かせていません。
これにより、2つの相互に関連する問題が生じます。1つは、パーソナライズされたユーザータスクのニーズに合致しないために、クラウド上のLLMsの問題解決能力が限られていること、2つ目は、ユーザーデータがデバイス上のSLMsの応答に適切に統合されず、文脈におけるユーザー情報の不一致が生じることです。
本論文では、プライバシーを保護するクラウドデバイスのコラボレーションのためのリーダー–従属検索フレームワーク(LSRP)を提案します。この新しいソリューションは、1つ目として、ユーザーからユーザーへの検索強化生成(U-U-RAG)というタスク特有のリーダー戦略の動的選択を通じて、デバイス上のSLMに対するクラウド上のLLMの指導を強化し、2つ目として、プライバシーを保護するユーザー応答の関連性(Q-A Rel.)、ユーザーデータ参照率(UDRR)、および困惑度(PPL)に基づくフィードバックを統合することにより、クラウド上のLLMとデバイス上のSLMの整合性を向上させます。2つのデータセットに基づく実験では、LSRPが常に最先端のベースラインを上回り、質問応答の関連性とパーソナライズが大幅に改善され、効率的なデバイス上の検索を通じてユーザーのプライバシーを保護することが示されました。
1. 導入
LLM活用企業は質問応答を通じてユーザーデータを収集しサービスを強化していますが、GDPRなどの規制によりプライベートデータはデバイス外でアクセス不可となっています。企業はSLMを導入しローカルデータ処理を実現していますが、問題解決能力は制限されています。現行フレームワークはLLMの応答スケッチをSLMが精緻化するアプローチですが、LLMの能力活用不足とユーザーデータ統合の不十分さが課題です。LSRPではLLMをリーダー、SLMをサボーディネイトとして、効率的なタスク実行と問題解決・プライバシーのバランスを実現します。
2. 問題定義
入出力レベルのプライバシー保護クラウド・デバイス協調は、クラウドLLM(パラメータθ)の出力を活用してデバイスSLM(パラメータφ)のパフォーマンスを向上させることが目的です。LLMはユーザータスクTを処理し中間結果OLLMを出力、SLMはこれとプライバシーデータPを用いて最終出力OSLMを生成します。目的は①ユーザープライバシーをデバイス内に保持し、②クラウドLLMの中間結果を活用してSLM出力の品質とパーソナライゼーションを向上させることです。
3. LSRPフレームワーク
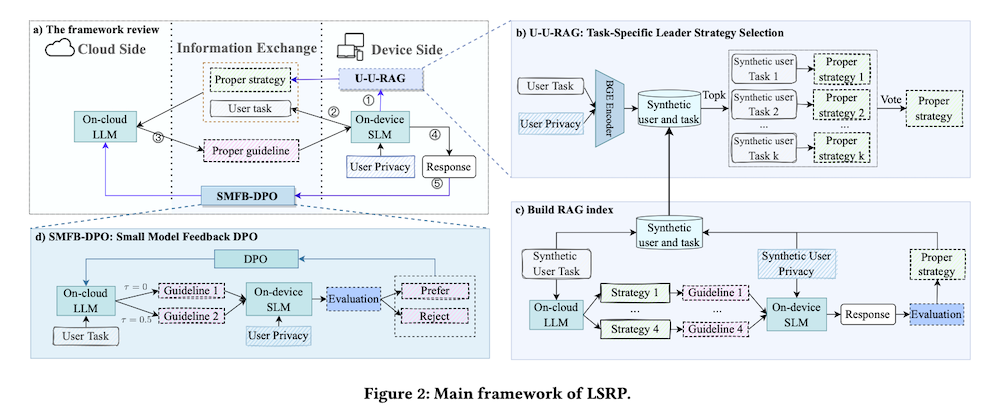
3.1 リーダー・サボーディネイトフレームワーク概要
クラウド・デバイス協調向上のため、パス・ゴールリーダーシップ理論に基づくフレームワークを提案します。クラウドLLMがリーダーとしてガイドラインを提供し、デバイスSLMがサボーディネイトとしてプライバシー保護・パーソナライズされたタスクを実行します。協調プロセスは①SLMによるリーダー戦略選択、②ユーザータスクのクラウド送信、③LLMによるガイドライン生成、④SLMによる最終応答生成、⑤LLM最適化のためのフィードバック送信の5ステップで構成されます。
3.2 U-U-RAG:タスク固有リーダー戦略選択
クラウド・デバイス協調の課題はタスクとユーザーニーズの多様性への対応です。提案するU-U-RAGでは、LLMが4つのリーダーシップ戦略(指示的、支援的、参加的、達成志向)を採用し、タスクに応じて最適な戦略を選択します。「似た者同士が集まる」原則に基づき、合成ユーザーのタスクパターンから実ユーザーに最適な戦略を検索・投票で決定します。
3.3 SMFB-DPO:小規模モデルフィードバックDPO
データ優位性を持つオンデバイスSLMからのフィードバックを活用するSMFB-DPOを提案します。プロセスはLLMが異なる温度で2つのガイドラインを生成し、SLMがこれらを評価して「好む」と「拒否」にラベル付けします。LLMパラメータはDPOを用いて、好まれるガイドライン生成確率を最大化し拒否されるガイドライン生成確率を最小化するよう更新されます。
3.4 評価指標Q
システム評価のため、Q-A関連性(質問と回答の関連性)、ユーザーデータ参照率(プライバシーデータの活用度)、パープレキシティ(モデルの流暢さ)の3指標を採用します。総合評価スコアは重み付け組み合わせQ(OSLM) = w1・RQ-A + w2・UDRR – w3・PPLで表され、NSGA-IIアルゴリズムを用いて最適な重みを決定します。
4. 実験
4.1 実験設定
オープンソースCoGenisデータセット(ユーザープライバシーデータと多様なパーソナライズタスクを含む)と合成Movie Explainデータセット(映画推薦の説明)を使用し、オンデバイスSLM、蒸留、CoGenesis、LLM Guide SLM、オンデバイスLLMをベースラインとして比較しました。
4.2 全体的なパフォーマンス(RQ1)
実験結果から:①LSRPのリーダー・サボーディネイト協調は両データセットでSLM応答を大幅に強化、②多様なタスク(CoGenis)ではQ-A関連性がより向上、③単一タスク(Movie Explain)ではパーソナライゼーションがより向上することが示されました。LSRPは適切な戦略選択とフィードバック学習により他手法を上回りました。
4.3 アブレーション研究(RQ2)
LSRPの各コンポーネント(U-U-RAG、SMFB-DPO)の影響を検証した結果:①両コンポーネントが重要、②U-U-RAGはQ-A関連性に貢献、③SMFB-DPOはパーソナライゼーションに貢献していることが判明しました。完全なフレームワークが最高スコアを達成しています。
4.4 U-U-RAGの有効性(RQ3)
U-U-RAGの評価から:①LLMの能力を活用してQ-A関連性を向上、②関連ユーザー検索は精度向上に貢献し不要なユーザーは精度低下を招く、③ユーザープライバシーを使用した検索はよりパーソナライズされた結果を生成することが確認されました。U-U-RAGはSLM選択方式より優れたパフォーマンスを示しています。
4.5 SMFB-DPOの有効性(RQ4)
SMFB-DPO前後のパフォーマンス比較から、フィードバックからの学習がオンデバイスユーザーデータの活用を大幅に向上させることが示されました。LLaMaとQwen両モデルでDPO実装後のQ-A関連性とパーソナライゼーションスコアが向上し、一般戦略の使用でさらなる効果が得られました。
5. 関連研究
5.1 プライバシー保護のためのオンデバイスSLM
大手企業はプライバシー保護のため軽量モデル開発に注力しています。Apple、Google、Huaweiなどはセンシティブデータ処理用の小型モデルを導入し、ユーザーはプライバシー強化型サービスの恩恵を受けています。しかしSLMはLLMと比べ能力が制限されるため、提案手法ではプライバシーを維持しつつLLMの問題解決能力を活用します。
5.2 クラウド・デバイスLLM SLM協調
オンクラウドLLMは問題解決力に優れる一方、オンデバイスSLMはパーソナライズデータへのアクセスが強みです。両者の利点を組み合わせる「クラウド・デバイスSLM LLM協調」が研究されていますが、既存手法はクラウド能力とデバイスデータの活用が不十分です。LSRPは適切な戦略選択とフィードバック活用により協調を改善します。
6. 結論
本研究で提案したLSRPは、U-U-RAGとSMFB-DPOを活用し多様なタスクに動的適応することで、関連性・パーソナライゼーション・流暢さを最適化します。広範な実験により、LSRPが既存手法を複数指標で上回り、プライバシー保護とパーソナライゼーションが必要なシナリオで効果的なソリューションであることを実証しました。